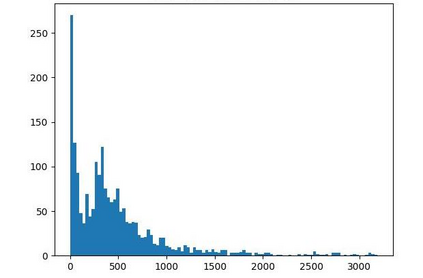
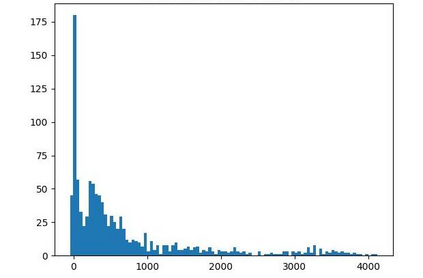
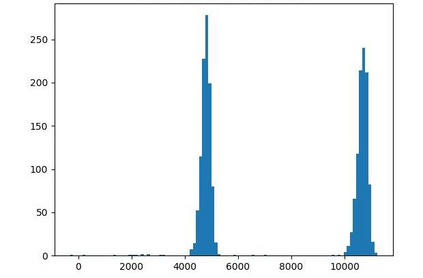
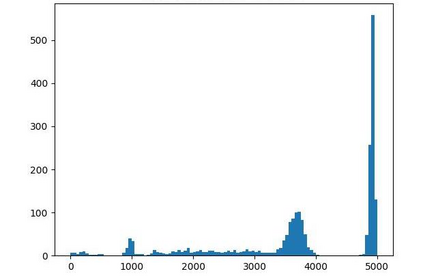
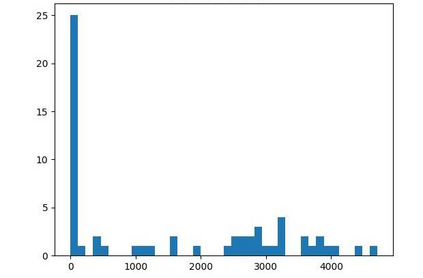
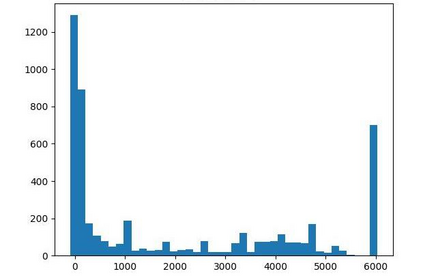
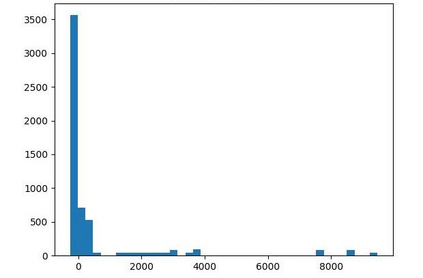
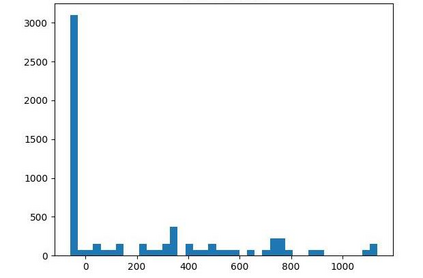
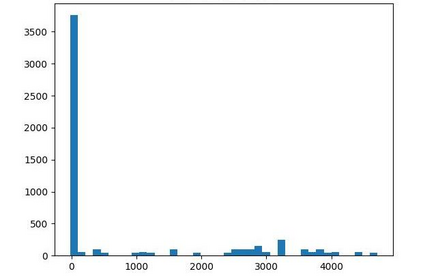
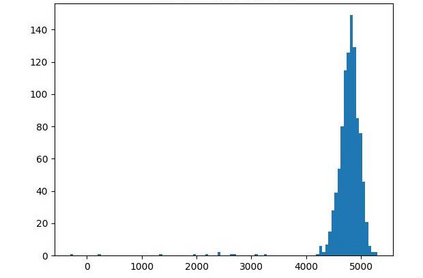
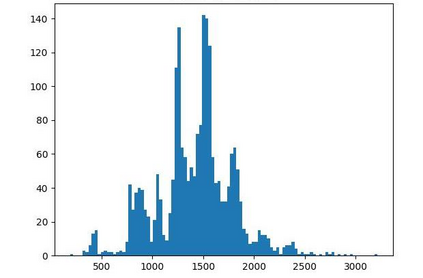
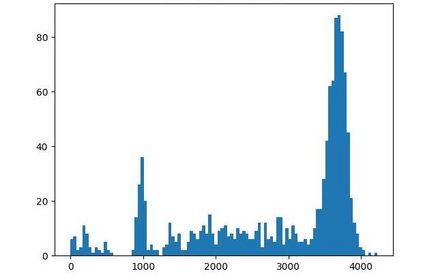
Offline reinforcement learning (RL) is challenged by the distributional shift between learning policies and datasets. To address this problem, existing works mainly focus on designing sophisticated algorithms to explicitly or implicitly constrain the learned policy to be close to the behavior policy. The constraint applies not only to well-performing actions but also to inferior ones, which limits the performance upper bound of the learned policy. Instead of aligning the densities of two distributions, aligning the supports gives a relaxed constraint while still being able to avoid out-of-distribution actions. Therefore, we propose a simple yet effective method to boost offline RL algorithms based on the observation that resampling a dataset keeps the distribution support unchanged. More specifically, we construct a better behavior policy by resampling each transition in an old dataset according to its episodic return. We dub our method ReD (Return-based Data Rebalance), which can be implemented with less than 10 lines of code change and adds negligible running time. Extensive experiments demonstrate that ReD is effective at boosting offline RL performance and orthogonal to decoupling strategies in long-tailed classification. New state-of-the-arts are achieved on the D4RL benchmark.
翻译:离线强化学习( RL) 受到学习政策和数据集之间分布变化的挑战。 解决这个问题, 现有工作主要侧重于设计精密的算法, 以明示或隐含的方式限制所学政策接近行为政策。 限制不仅适用于表现良好的行动,也适用于劣等行动,这限制了所学政策上层的性能。 不调整两个分布的密度, 调整支持会放松限制, 同时仍然能够避免分配之外的行动。 因此, 我们提出一个简单而有效的方法, 以重现数据集使分布支持保持不变的观察为基础, 来提升离线的 RL 算法。 更具体地说, 我们制定更好的行为政策, 根据旧数据集的回归, 重新标注每个转换。 我们用的方法( 以翻转为基础的数据重新平衡) 重新定位, 可以用不到10行的代码变化来实施, 并增加微小的运行时间。 因此, 广泛的实验证明 ReD 能够有效地提升离线 RL 性运行, 以及 或Thotognal 来在长期链接的分类中解析战略。