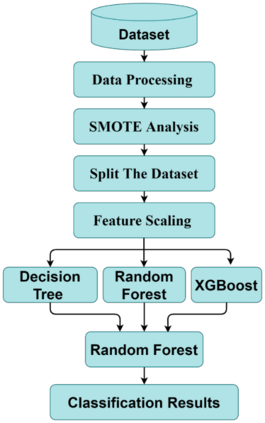
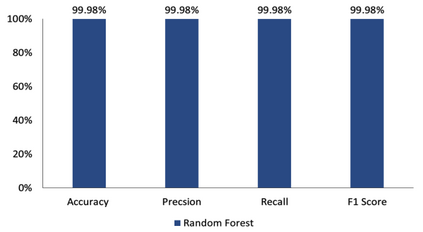
Cardiovascular disease, especially heart failure is one of the major health hazard issues of our time and is a leading cause of death worldwide. Advancement in data mining techniques using machine learning (ML) models is paving promising prediction approaches. Data mining is the process of converting massive volumes of raw data created by the healthcare institutions into meaningful information that can aid in making predictions and crucial decisions. Collecting various follow-up data from patients who have had heart failures, analyzing those data, and utilizing several ML models to predict the survival possibility of cardiovascular patients is the key aim of this study. Due to the imbalance of the classes in the dataset, Synthetic Minority Oversampling Technique (SMOTE) has been implemented. Two unsupervised models (K-Means and Fuzzy C-Means clustering) and three supervised classifiers (Random Forest, XGBoost and Decision Tree) have been used in our study. After thorough investigation, our results demonstrate a superior performance of the supervised ML algorithms over unsupervised models. Moreover, we designed and propose a supervised stacked ensemble learning model that can achieve an accuracy, precision, recall and F1 score of 99.98%. Our study shows that only certain attributes collected from the patients are imperative to successfully predict the surviving possibility post heart failure, using supervised ML algorithms.
翻译:心血管疾病,特别是心脏衰竭,是我们时代的主要健康危害问题之一,也是造成全世界死亡的一个主要原因。使用机器学习(ML)模型的数据挖掘技术的进步正在铺平充满希望的预测方法。数据挖掘是一个过程,将保健机构创造的大量原始数据转换成有意义的信息,有助于作出预测和关键决定。从心脏病患者收集各种后续数据,分析这些数据,并利用若干ML模型来预测心血管病人的生存可能性,这是本研究的关键目标。此外,由于数据集中各班级的不平衡,合成少数群体过度采样技术(SMOTE)已经实施。两个不受监督的模型(K-Means和Fuzzy C-Means群集)和三个受监督的分类师(Random Forest、XGBoost和决定树)已经用于我们的研究中。经过彻底调查后,我们的结果显示,监督的ML算法比未受监督的模型表现优。此外,我们设计并提出了一个经过监督的组合学习模型,这个模型已经落实了99-98人的心脏预算,能够成功地用我们的精确、精确度测测算出一定的M-98的模型。回顾,只能从我们的心脏测测算,只能测算出某种的精确测算结果。