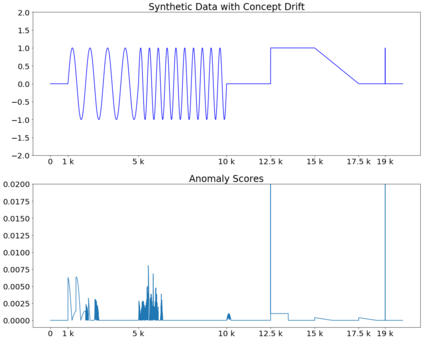
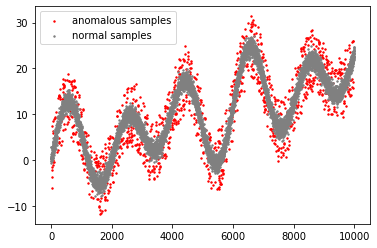
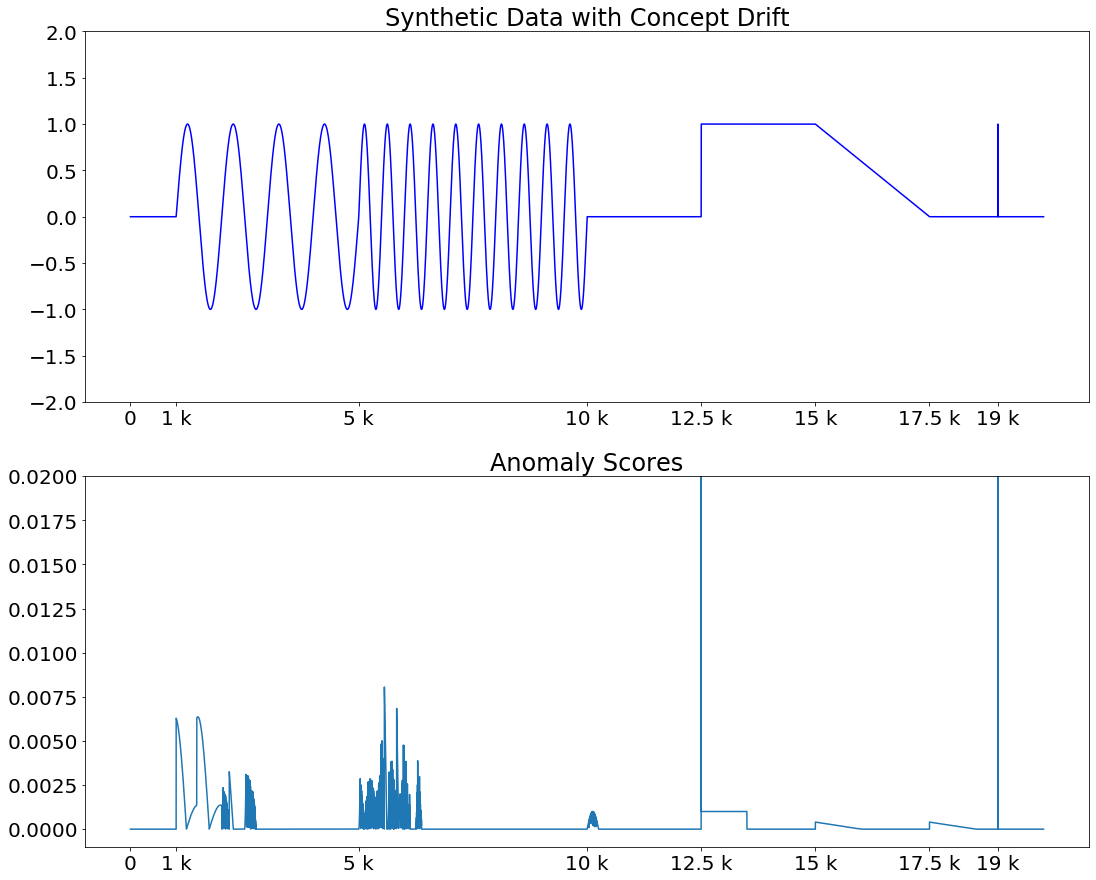
Given a stream of entries over time in a multi-aspect data setting where concept drift is present, how can we detect anomalous activities? Most of the existing unsupervised anomaly detection approaches seek to detect anomalous events in an offline fashion and require a large amount of data for training. This is not practical in real-life scenarios where we receive the data in a streaming manner and do not know the size of the stream beforehand. Thus, we need a data-efficient method that can detect and adapt to changing data trends, or concept drift, in an online manner. In this work, we propose MemStream, a streaming multi-aspect anomaly detection framework, allowing us to detect unusual events as they occur while being resilient to concept drift. We leverage the power of a denoising autoencoder to learn representations and a memory module to learn the dynamically changing trend in data without the need for labels. We prove the optimum memory size required for effective drift handling. Furthermore, MemStream makes use of two architecture design choices to be robust to memory poisoning. Experimental results show the effectiveness of our approach compared to state-of-the-art streaming baselines using 2 synthetic datasets and 11 real-world datasets.
翻译:在存在概念漂移的多层数据设置中,我们如何探测异常活动?大多数现有的未经监督的异常探测方法都试图以离线方式探测异常事件,并需要大量的培训数据。这在现实生活中是不切实际的,因为我们以流方式接收数据,并且不知道流流的大小。因此,我们需要一种数据效率高的方法,能够检测和适应变化中的数据趋势,或概念流,可以在线方式。在这个工作中,我们提议MemStream,一个流动多层异常探测框架,使我们能够在概念漂移时发现异常事件。我们利用一个淡化的自动编码器的力量学习演示和记忆模块,学习数据动态变化趋势,而不需要标签。我们证明有效流处理所需的最佳记忆大小。此外,MemStream利用两种结构设计选择来稳健地应对记忆中毒。实验结果显示我们使用合成数据基线11和合成数据2的对比性数据基点的实际效果。