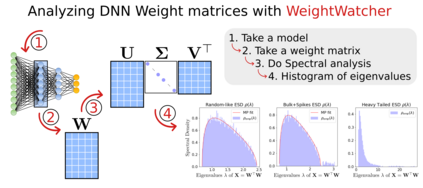
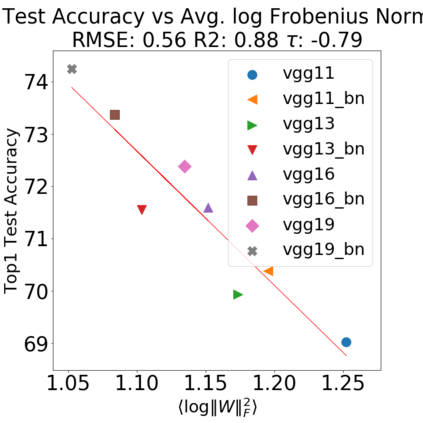
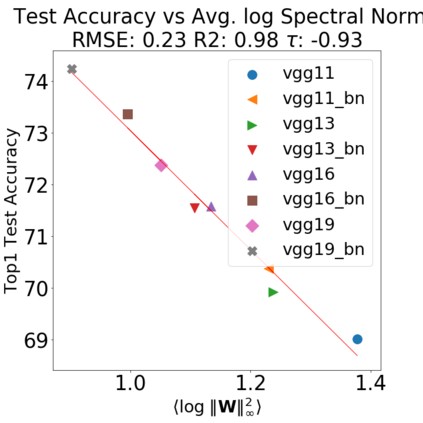
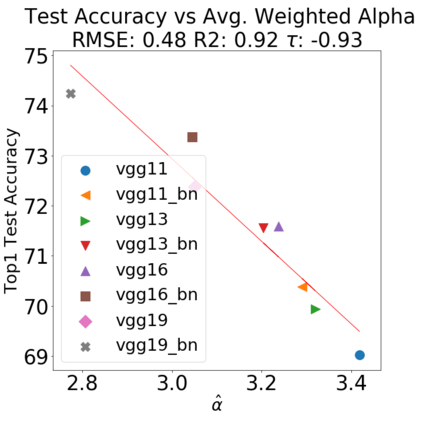
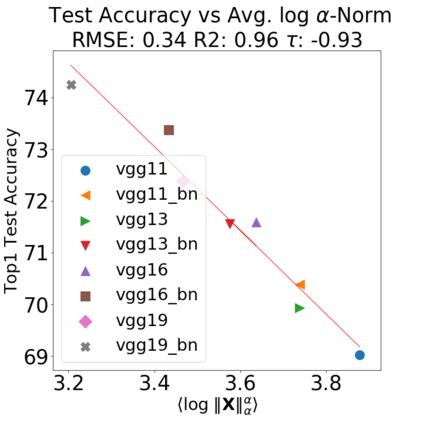
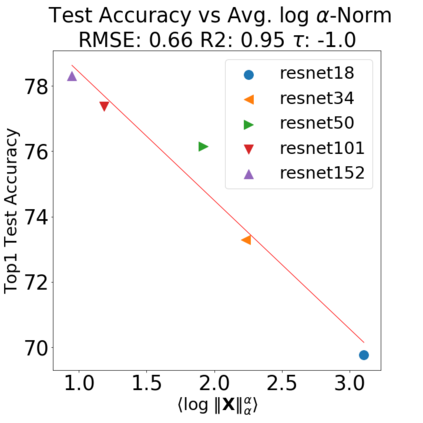
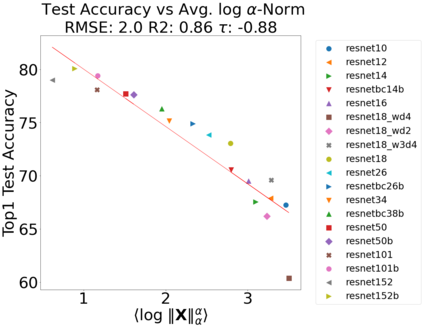
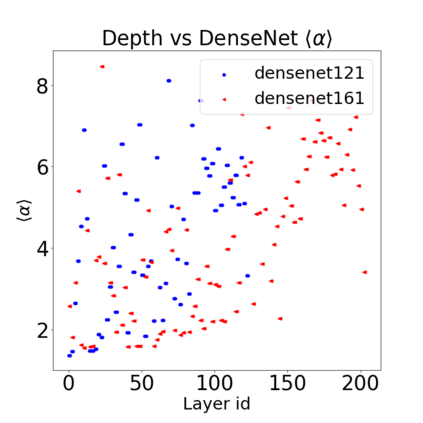
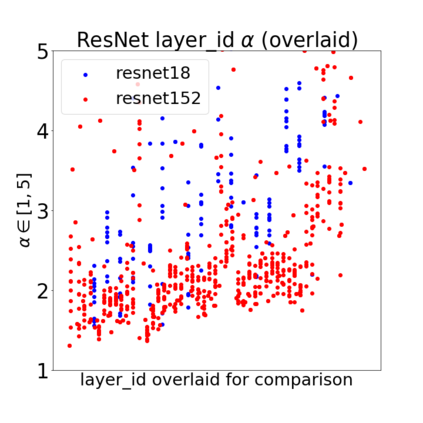
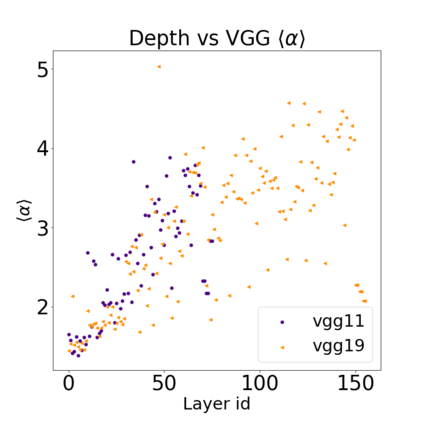
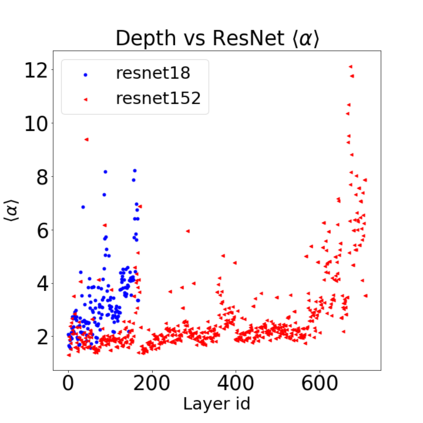
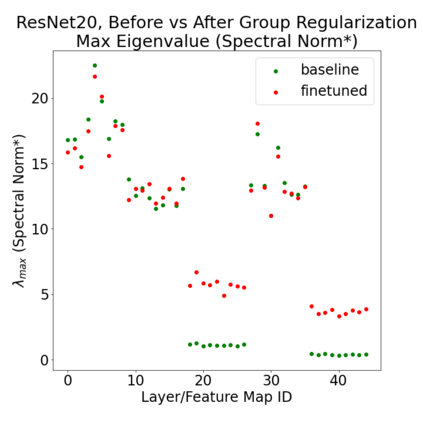
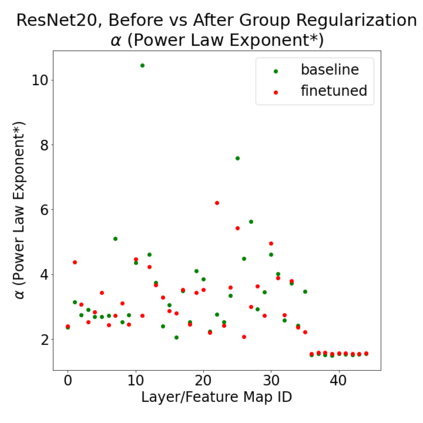
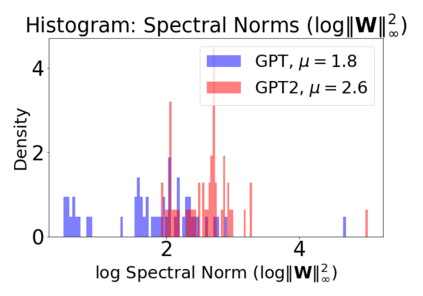
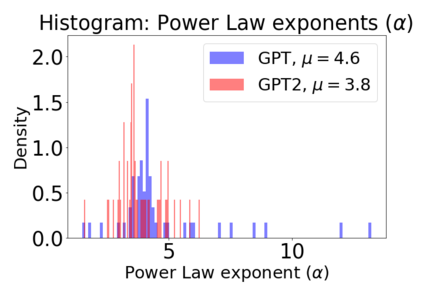
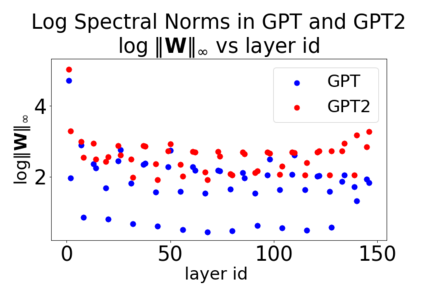
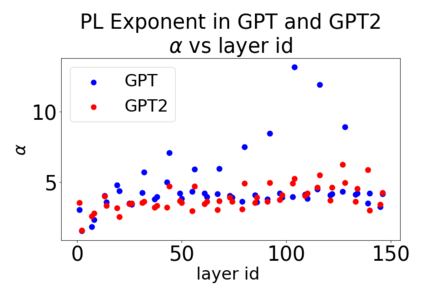
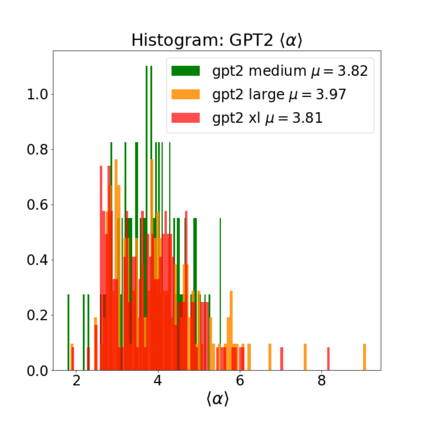
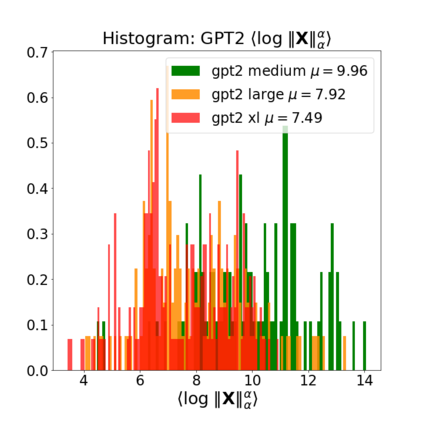
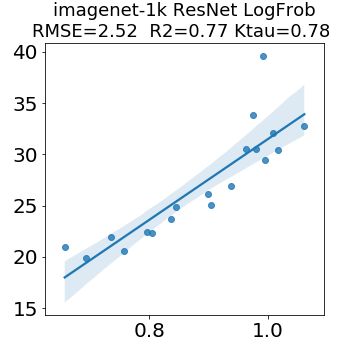
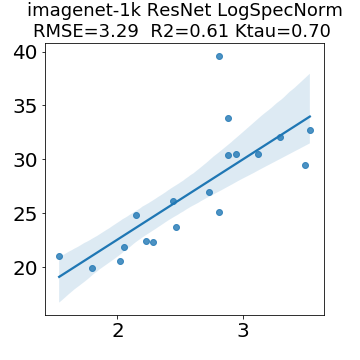
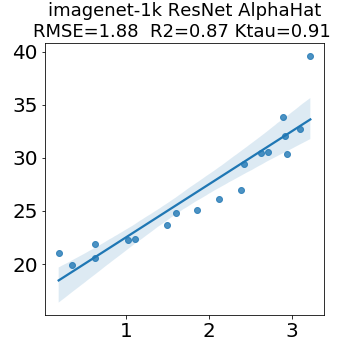
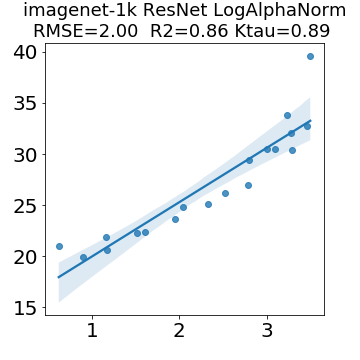
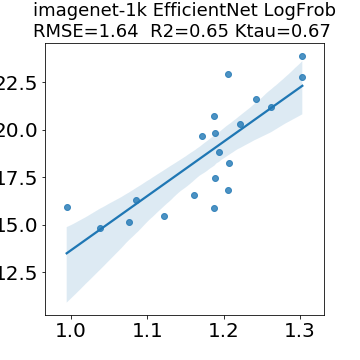
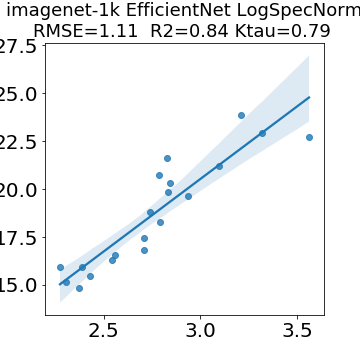
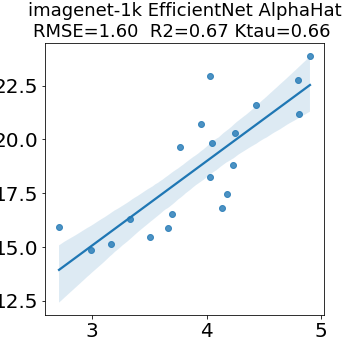
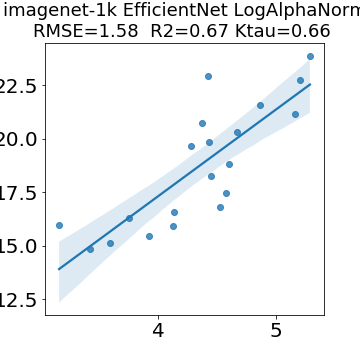
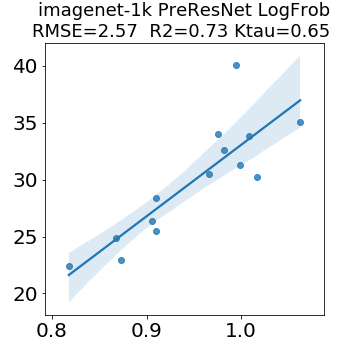
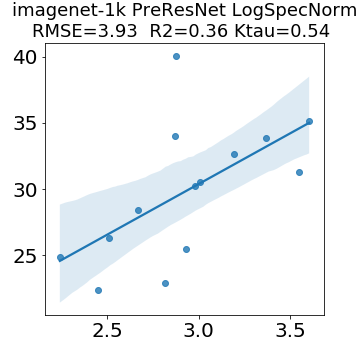
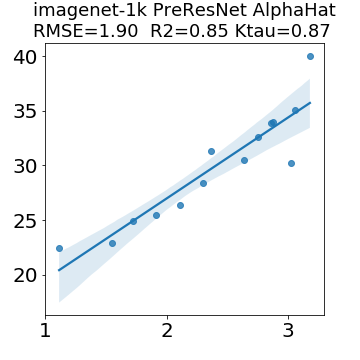
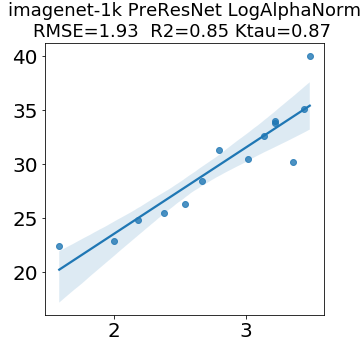
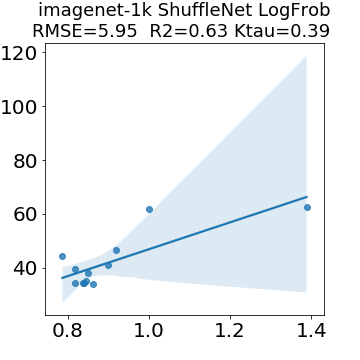
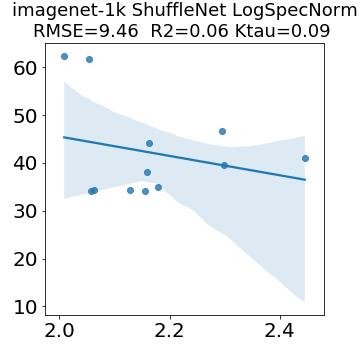
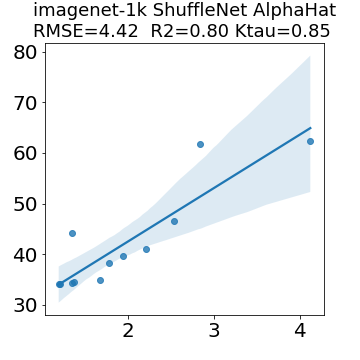
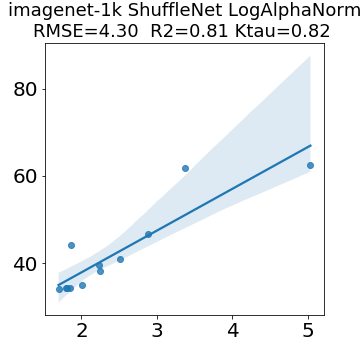
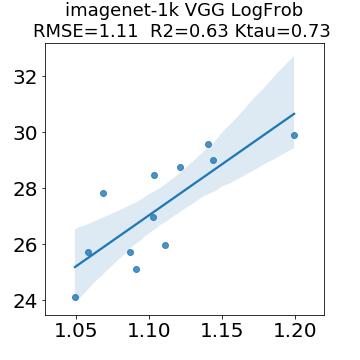
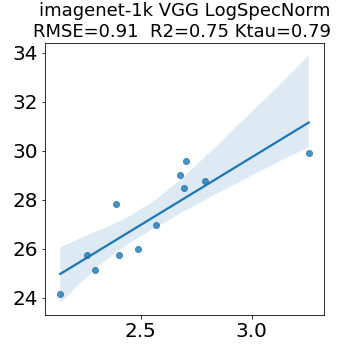
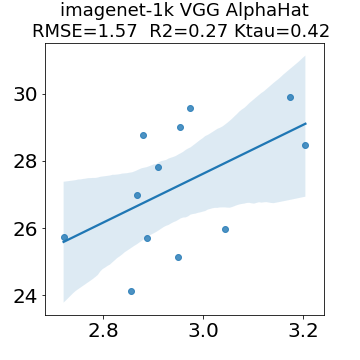
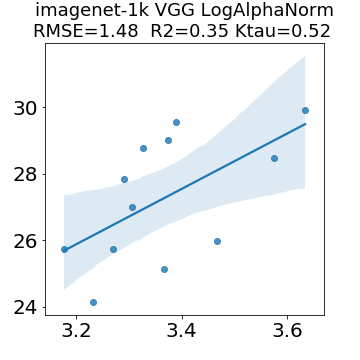
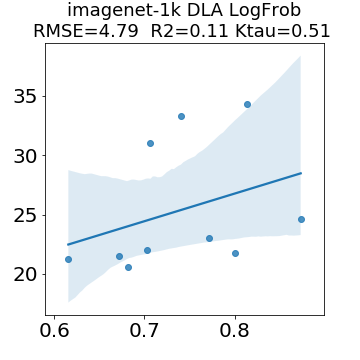
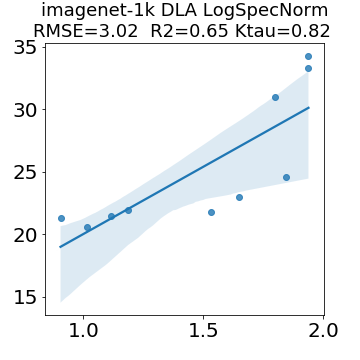
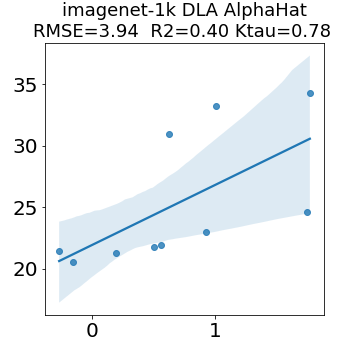
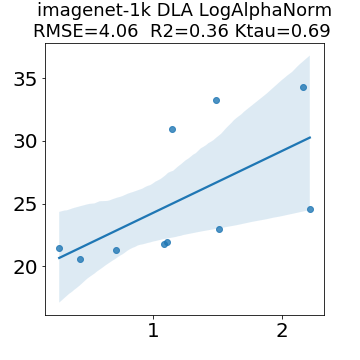
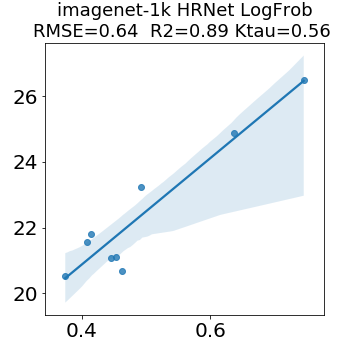
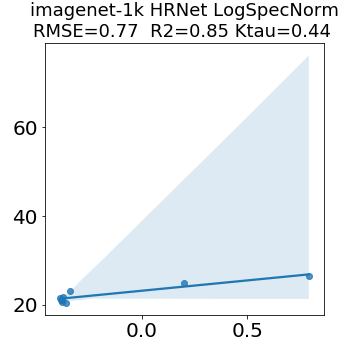
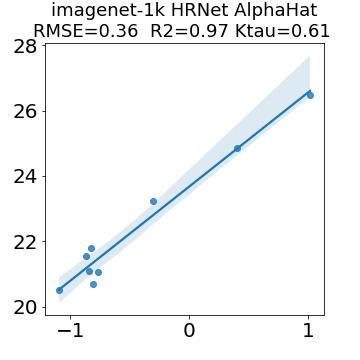
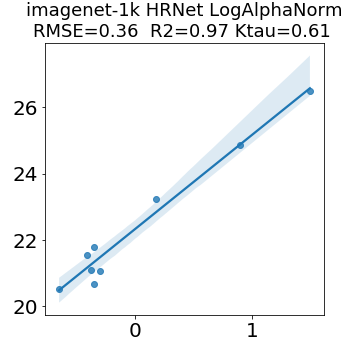
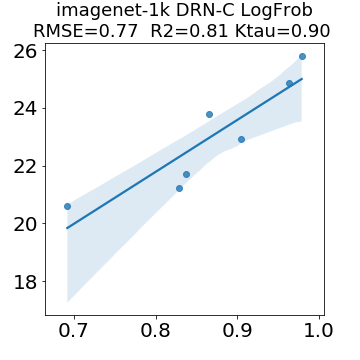
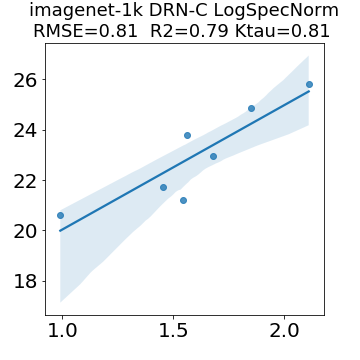
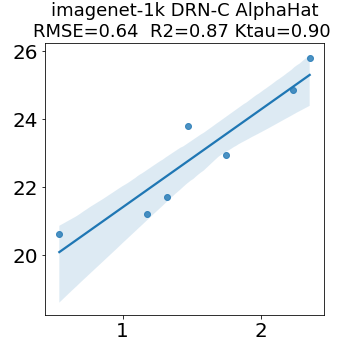
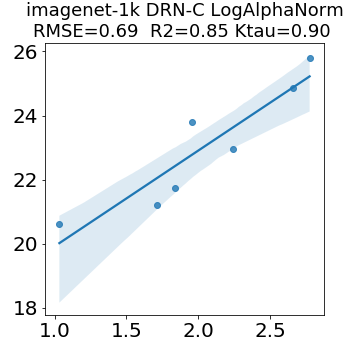
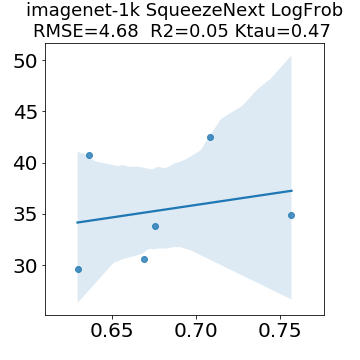
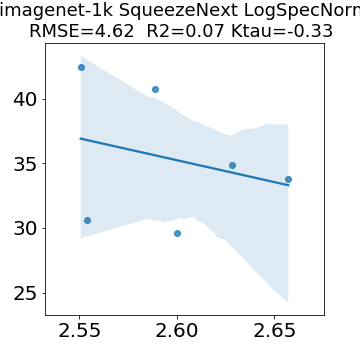
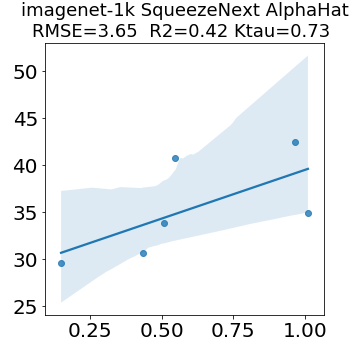
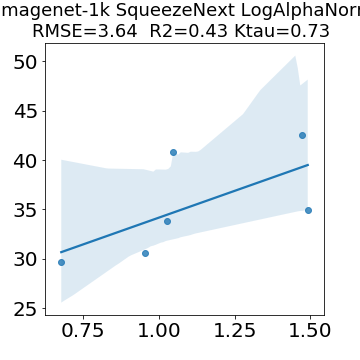
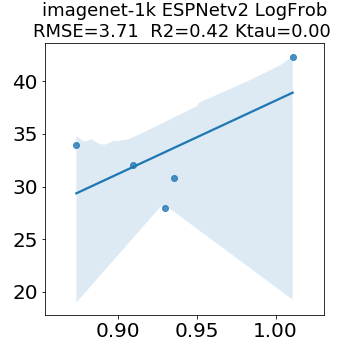
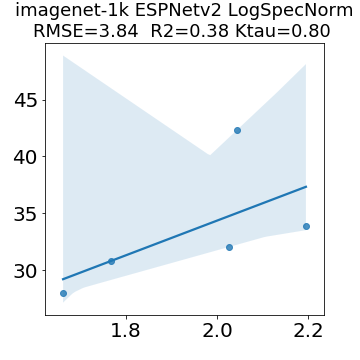
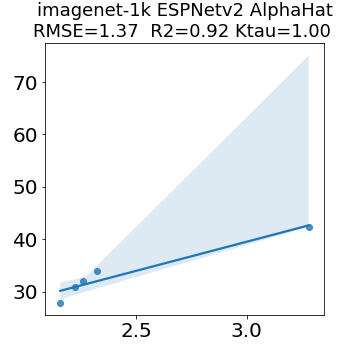
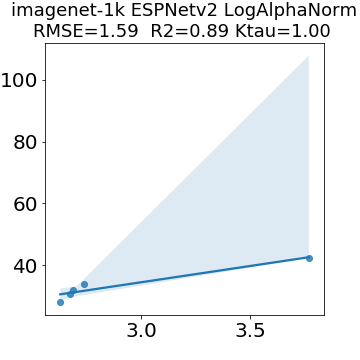
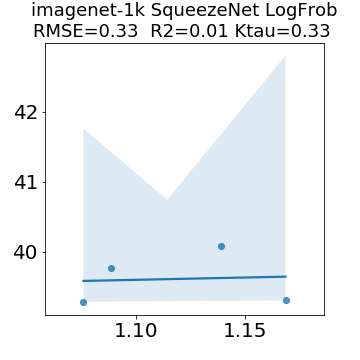
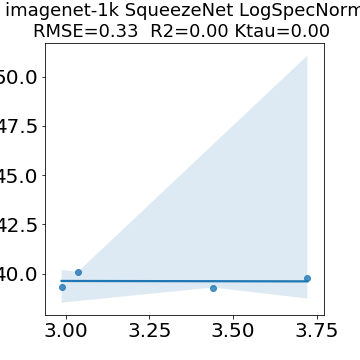
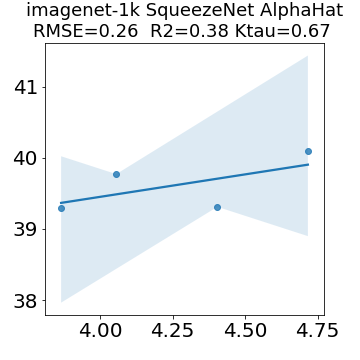
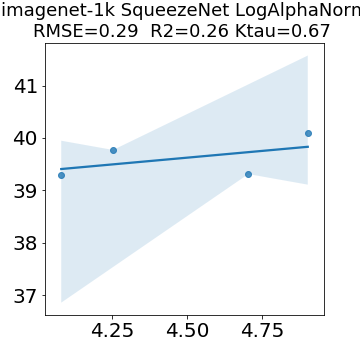
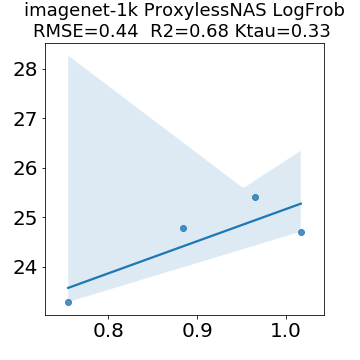
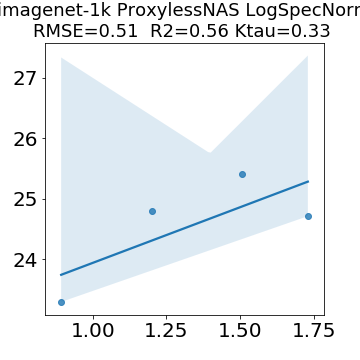
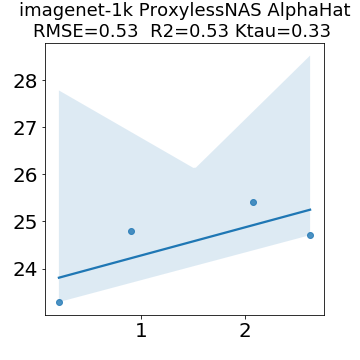
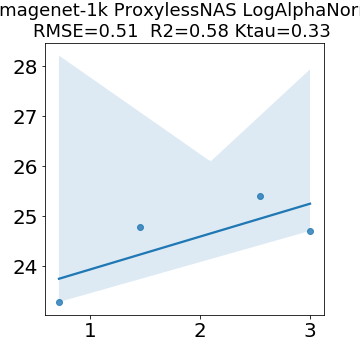
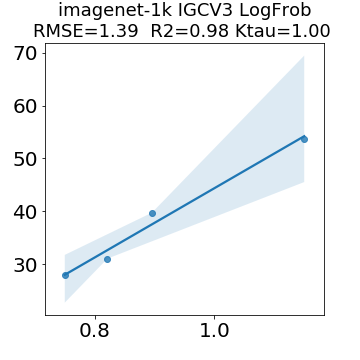
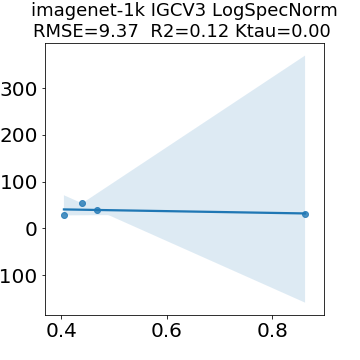
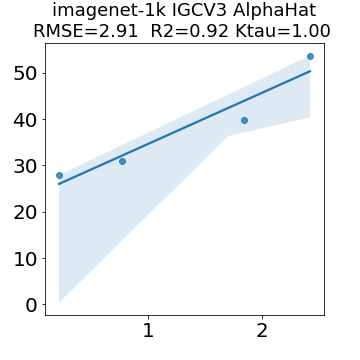
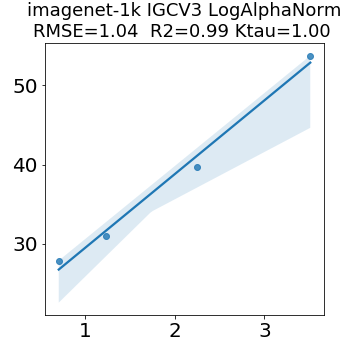
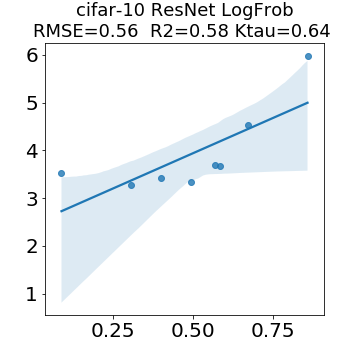
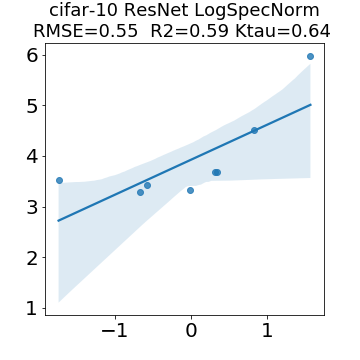
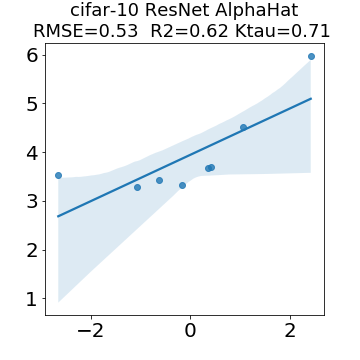
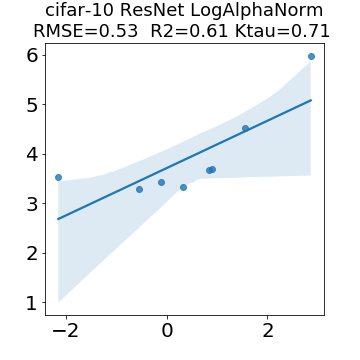
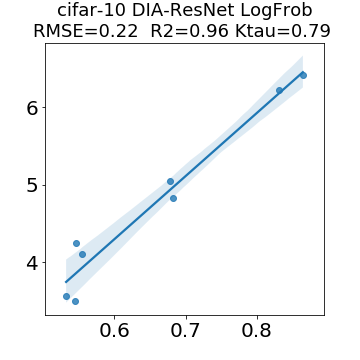
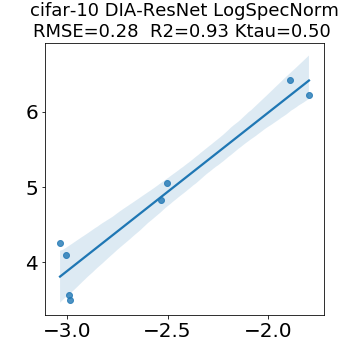
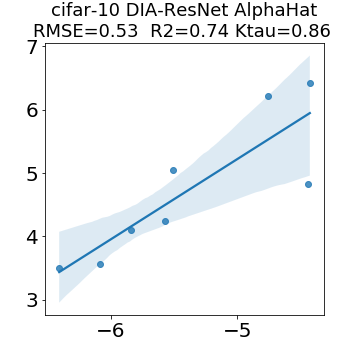
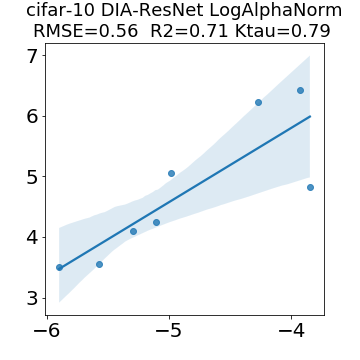
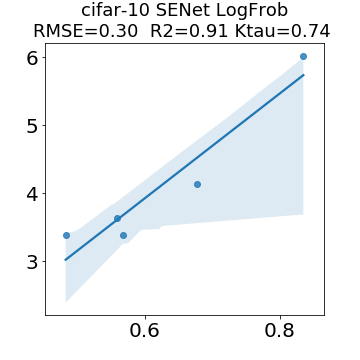
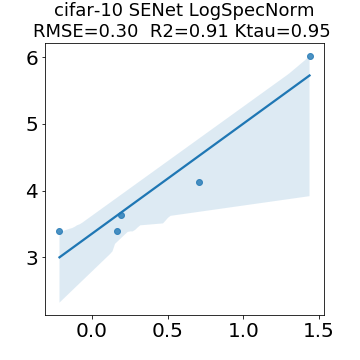
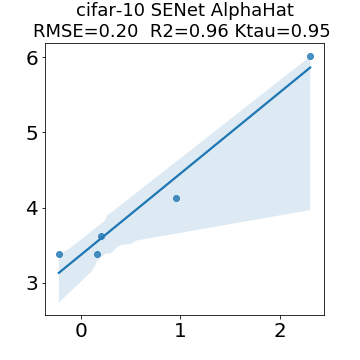
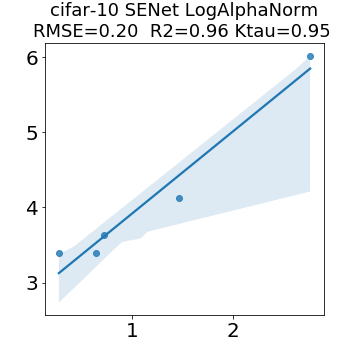
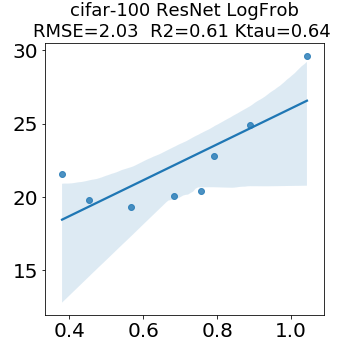
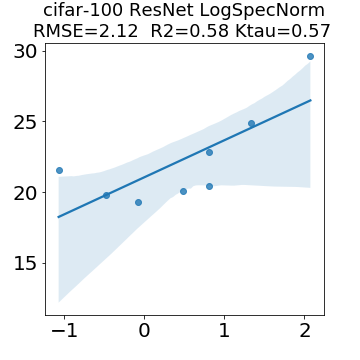
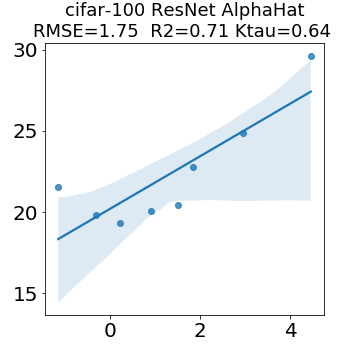
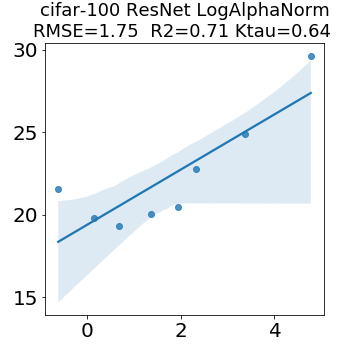
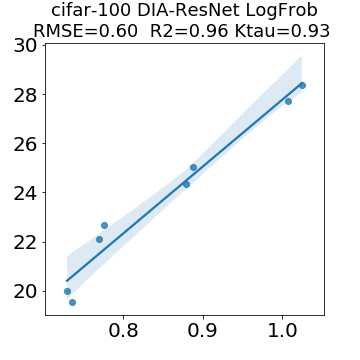
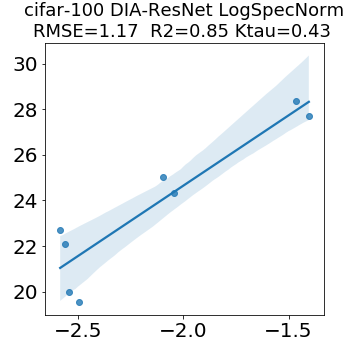
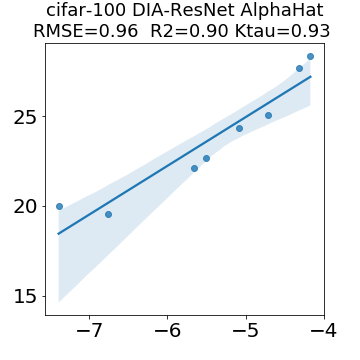
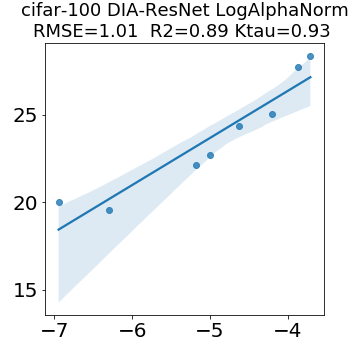
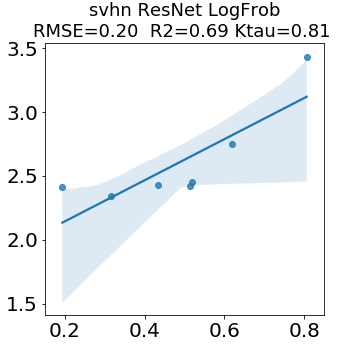
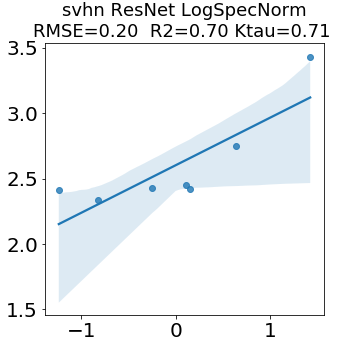
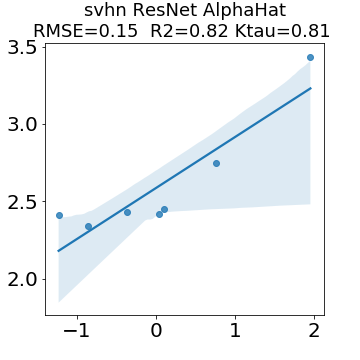
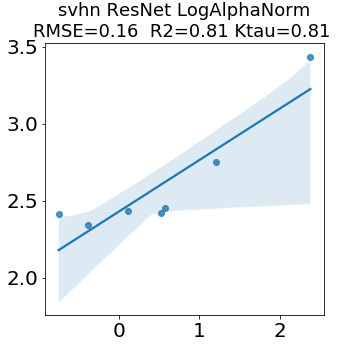
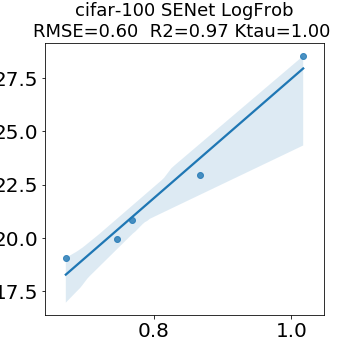
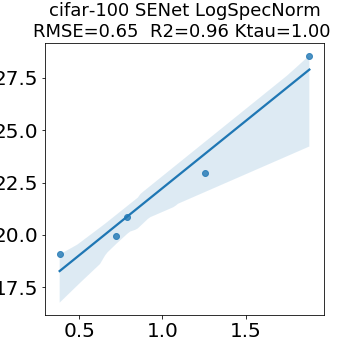
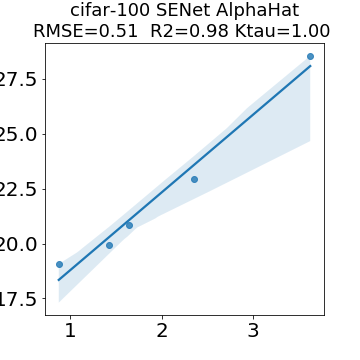
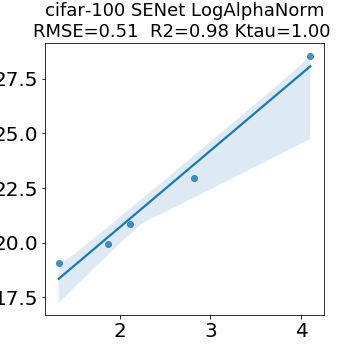
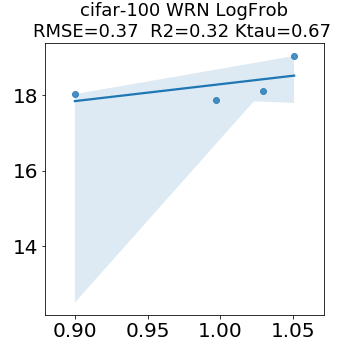
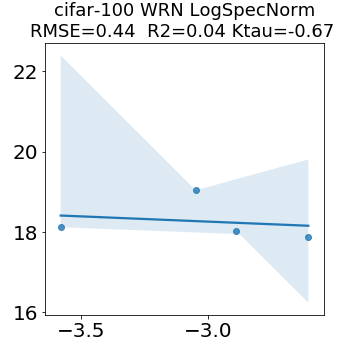
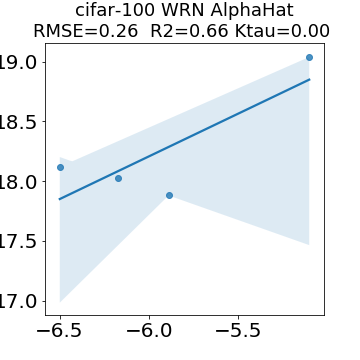
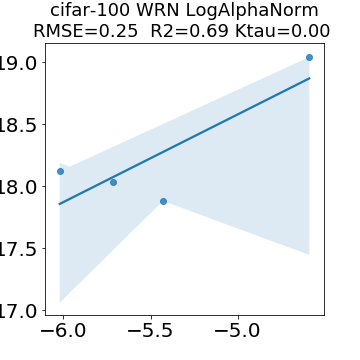
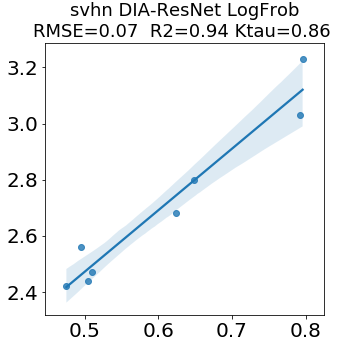
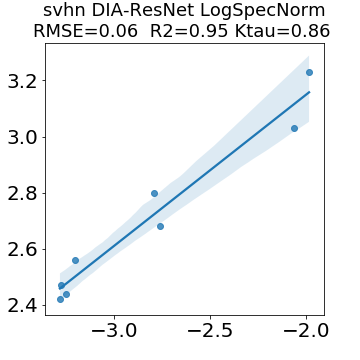
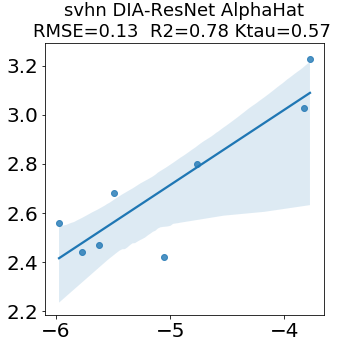
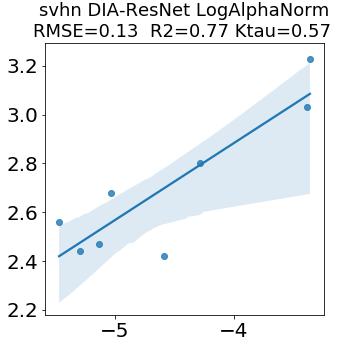
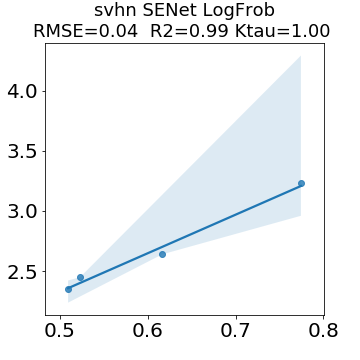
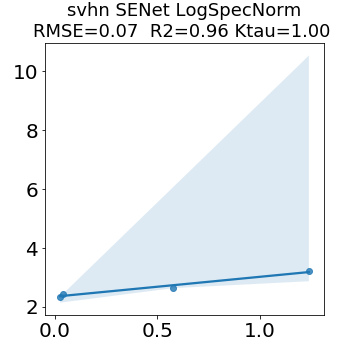
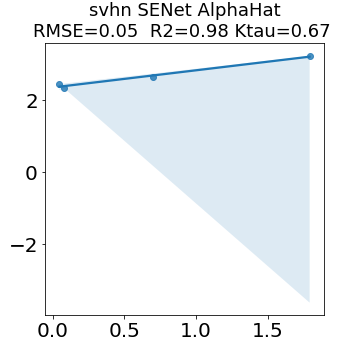
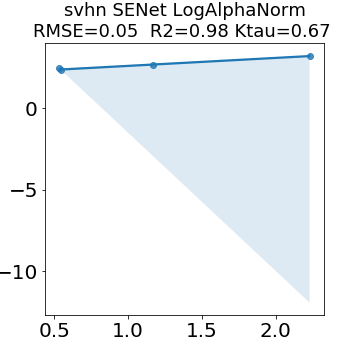
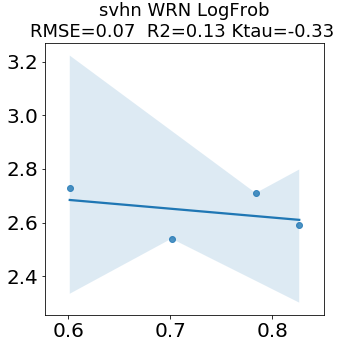
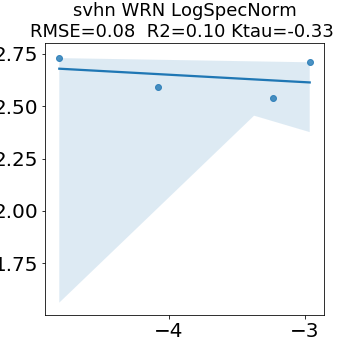
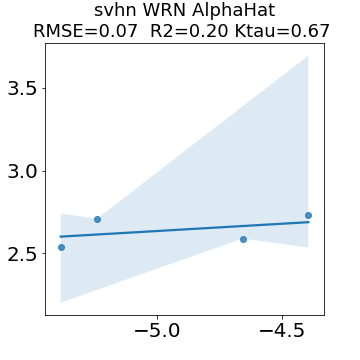
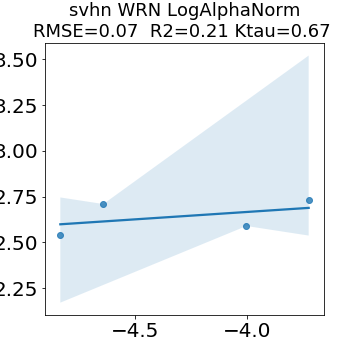
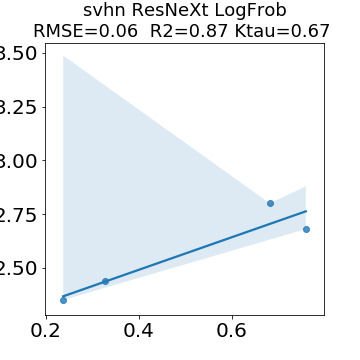
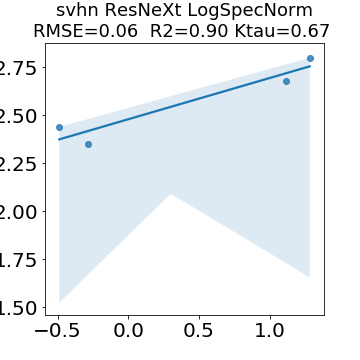
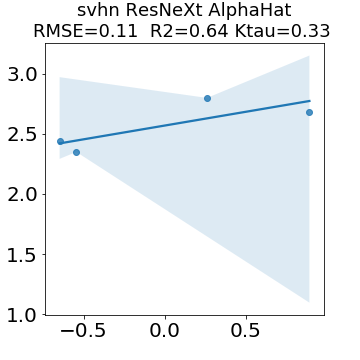
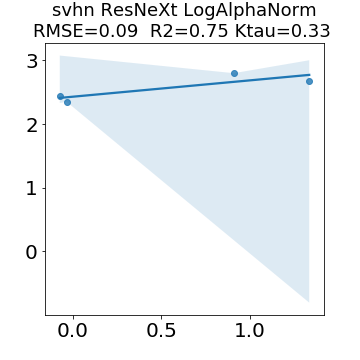
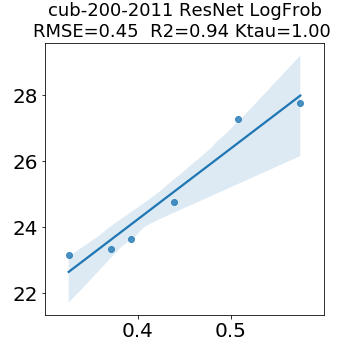
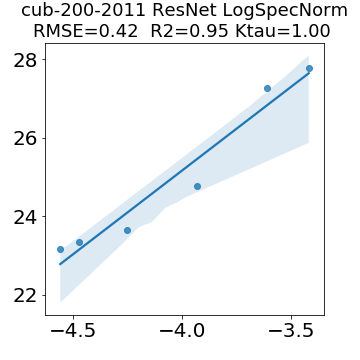
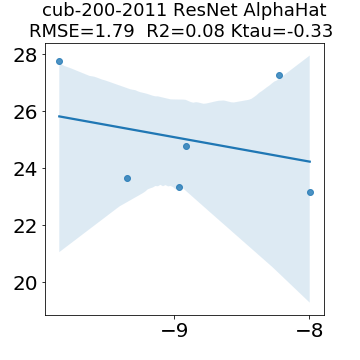
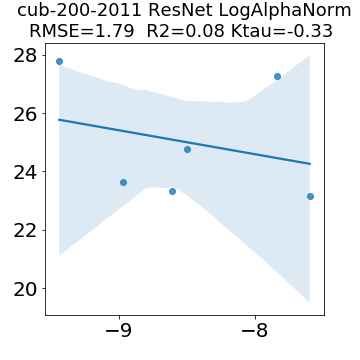
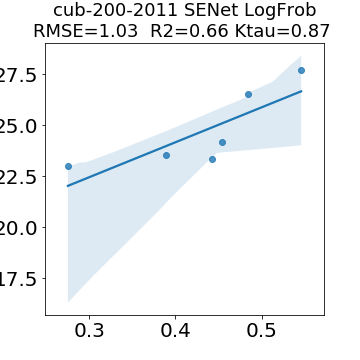
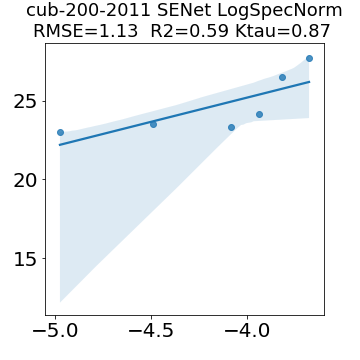
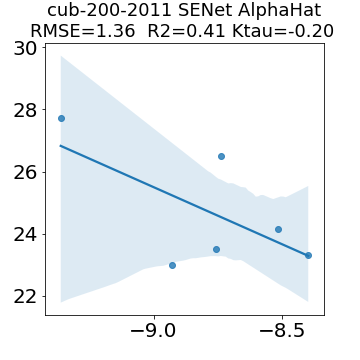
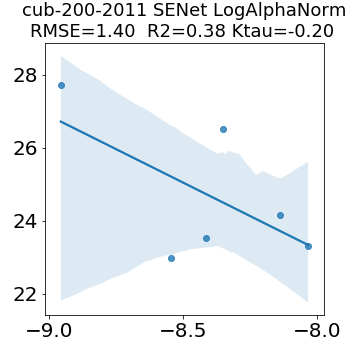
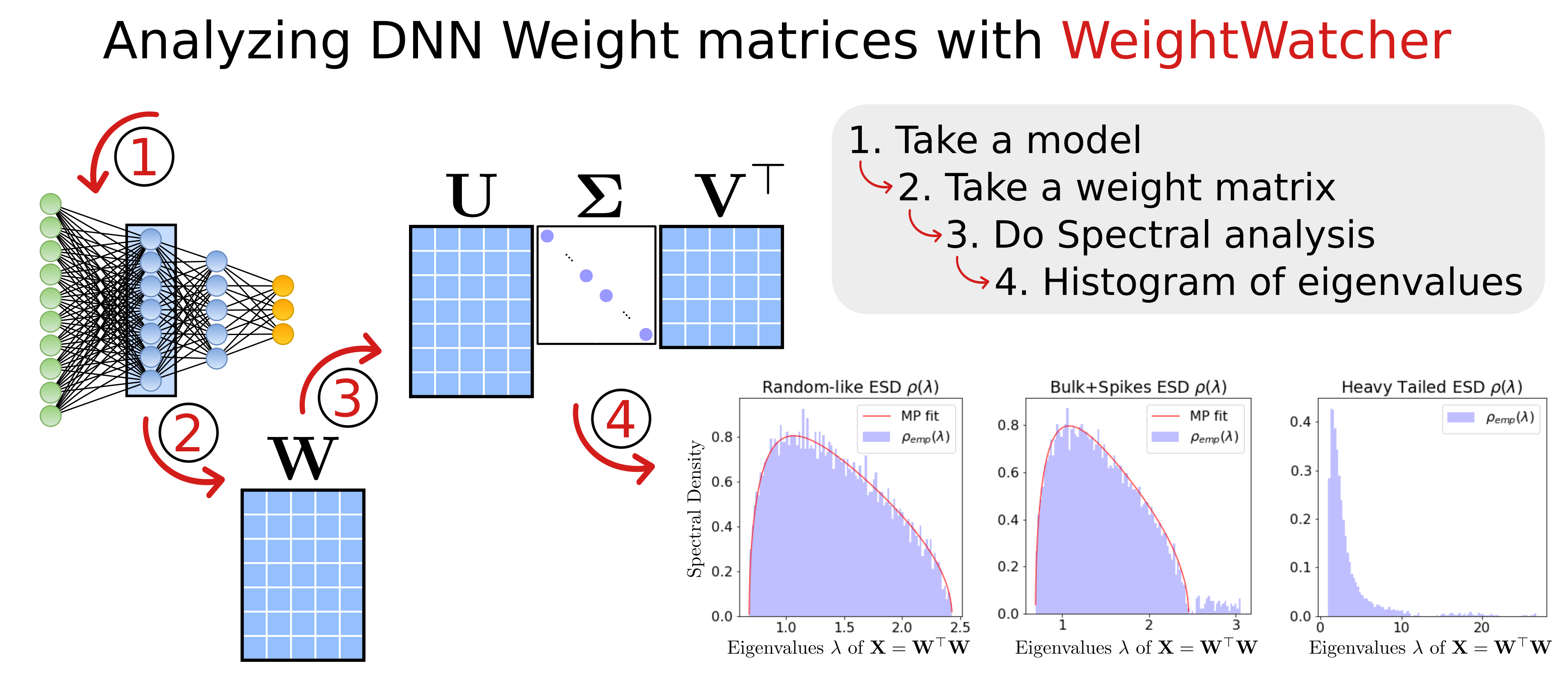
In many applications, one works with neural network models trained by someone else. For such pretrained models, one may not have access to training data or test data. Moreover, one may not know details about the model, e.g., the specifics of the training data, the loss function, the hyperparameter values, etc. Given one or many pretrained models, it is a challenge to say anything about the expected performance or quality of the models. Here, we address this challenge by providing a detailed meta-analysis of hundreds of publicly-available pretrained models. We examine norm based capacity control metrics as well as power law based metrics from the recently-developed Theory of Heavy-Tailed Self Regularization. We find that norm based metrics correlate well with reported test accuracies for well-trained models, but that they often cannot distinguish well-trained versus poorly-trained models. We also find that power law based metrics can do much better -- quantitatively better at discriminating among series of well-trained models with a given architecture; and qualitatively better at discriminating well-trained versus poorly-trained models. These methods can be used to identify when a pretrained neural network has problems that cannot be detected simply by examining training/test accuracies.
翻译:在许多应用程序中, 一个人会使用由他人培训的神经网络模型。 对于此类预培训模型, 一个人可能无法获得培训数据或测试数据。 此外, 人们可能不知道模型的细节, 例如培训数据的具体细节、 损失功能、 超参数值等等。 在一个或许多预培训模型中, 很难说出关于模型预期性能或质量的任何意见。 在这里, 我们通过对数百个公开获得的预培训模型进行详细的元分析来应对这一挑战。 我们检查最近开发的重力自我正规化理论中基于标准的能力控制指标以及基于动力法的衡量标准。 我们发现, 基于规范的标准指标与所报告的良好训练模型的测试精度非常相关, 但是它们往往无法辨别出经过良好训练的模型或训练不良的模型。 我们还发现, 以权力法为基础的衡量标准可以做得更好得多 -- 从数量上更好地区分由特定结构构成的经过良好训练的模型系列; 从质量上讲, 区别经过良好训练的模型和训练不良的模型。 这些方法可以用来在测试前的网络中找出问题时进行测试。