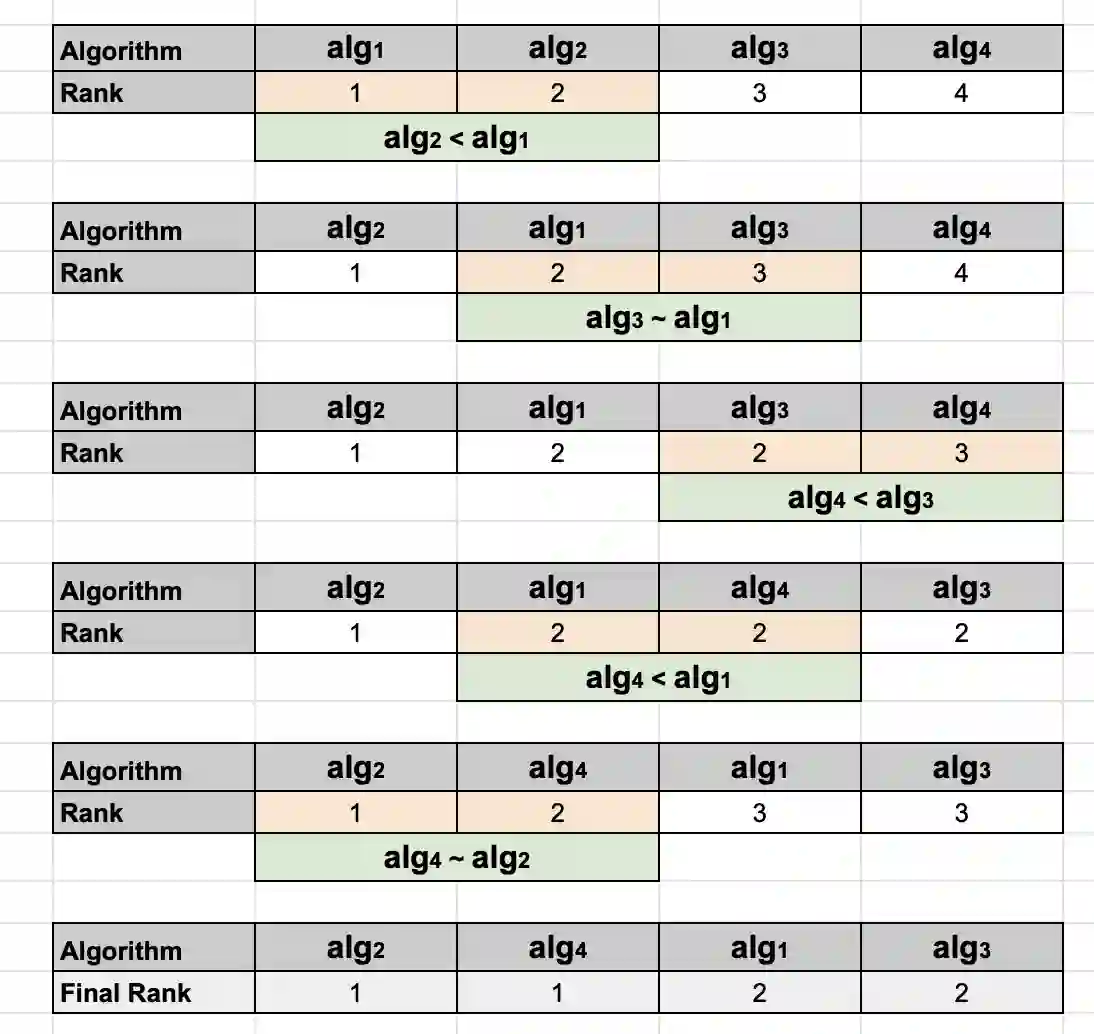
In scientific computing, it is common that a mathematical expression can be computed by many different algorithms (sometimes over hundreds), each identifying a specific sequence of library calls. Although mathematically equivalent, those algorithms might exhibit significant differences in terms of performance. However in practice, due to fluctuations, there is not one algorithm that consistently performs noticeably better than the rest. For this reason, with this work we aim to identify not the one best algorithm, but the subset of algorithms that are reliably faster than the rest. To this end, instead of using the usual approach of quantifying the performance of an algorithm in absolute terms, we present a measurement-based clustering approach to sort the algorithms into equivalence (or performance) classes using pair-wise comparisons. We show that this approach, based on relative performance, leads to robust identification of the fastest algorithms even under noisy system conditions. Furthermore, it enables the development of practical machine learning models for automatic algorithm selection.
翻译:在科学计算中,数学表达方式通常可以由多种不同的算法(有时超过数百个)来计算,每个算法可以确定图书馆通话的具体顺序。虽然在数学上等同,但这些算法在性能方面可能存在显著差异。然而,在实践上,由于波动,没有一个算法始终比其他算法更好地执行。因此,我们不是要确定一个最佳算法,而是要确定比其他算法可靠更快的算法子子。为此,我们不采用通常的方法,用绝对值来量化算法的性能,而是采用基于计量的组合法,用对等比较法将算法分为等(或性能)类。我们显示,根据相对性能,这种方法可以有力地识别即使在繁忙的系统条件下也最快的算法。此外,它使得能够开发实用的机器学习模型,用于自动算法选择。