
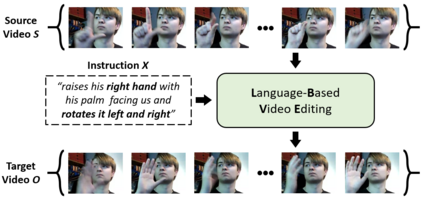
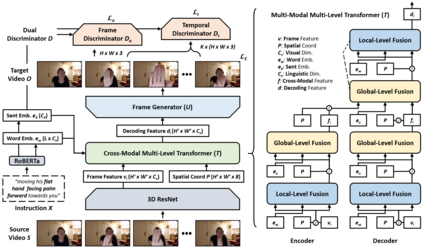
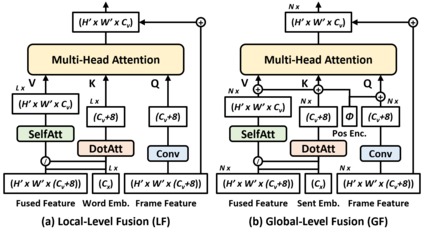
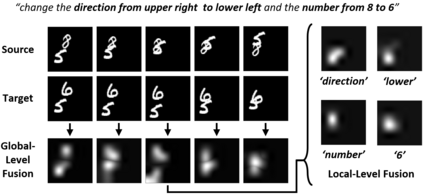
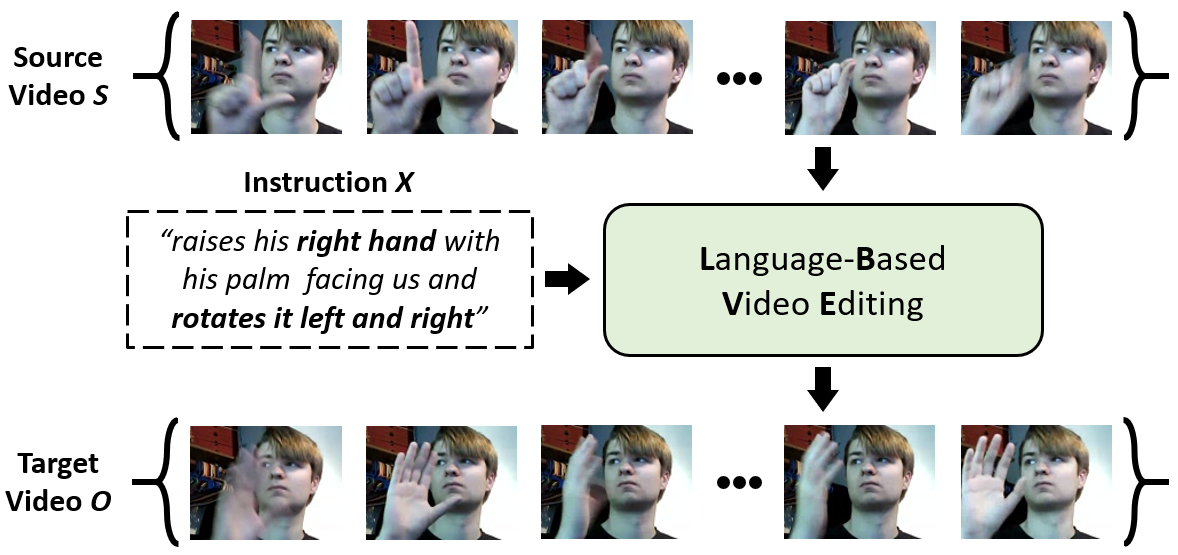
Video editing tools are widely used nowadays for digital design. Although the demand for these tools is high, the prior knowledge required makes it difficult for novices to get started. Systems that could follow natural language instructions to perform automatic editing would significantly improve accessibility. This paper introduces the language-based video editing (LBVE) task, which allows the model to edit, guided by text instruction, a source video into a target video. LBVE contains two features: 1) the scenario of the source video is preserved instead of generating a completely different video; 2) the semantic is presented differently in the target video, and all changes are controlled by the given instruction. We propose a Multi-Modal Multi-Level Transformer (M$^3$L-Transformer) to carry out LBVE. The M$^3$L-Transformer dynamically learns the correspondence between video perception and language semantic at different levels, which benefits both the video understanding and video frame synthesis. We build three new datasets for evaluation, including two diagnostic and one from natural videos with human-labeled text. Extensive experimental results show that M$^3$L-Transformer is effective for video editing and that LBVE can lead to a new field toward vision-and-language research.
翻译:数字设计目前广泛使用视频编辑工具。虽然对这些工具的需求很高,但先前所需的知识使得新手难以启动。能够遵循自然语言指令进行自动编辑的系统将大大改善无障碍性。本文介绍了基于语言的视频编辑任务(LBVE),该任务允许该模式在文字指令的指导下编辑一个源视频,将其纳入目标视频。 LBVE包含两个特点:1)源视频的情景保存,而不是生成完全不同的视频;2)目标视频中语义的显示方式不同,所有变化都由给定的指令控制。我们提议了一个多式多层次变换器(M$3$L-Transtrafer)来实施LBVE。M$3$L-Transform在不同级别上动态学习视频感知知觉和语言语义之间的对应关系,这有利于视频理解和视频框架合成。我们建立了三个新的评价数据集,包括两个诊断数据集,一个来自带有人类标签文字的自然视频。我们广泛实验结果显示M$3$L-Transexexexi 向L-Travein 提供新的视频编辑和LVevie-de 的有效实地研究。


相关内容

- Today (iOS and OS X): widgets for the Today view of Notification Center
- Share (iOS and OS X): post content to web services or share content with others
- Actions (iOS and OS X): app extensions to view or manipulate inside another app
- Photo Editing (iOS): edit a photo or video in Apple's Photos app with extensions from a third-party apps
- Finder Sync (OS X): remote file storage in the Finder with support for Finder content annotation
- Storage Provider (iOS): an interface between files inside an app and other apps on a user's device
- Custom Keyboard (iOS): system-wide alternative keyboards
Source: iOS 8 Extensions: Apple’s Plan for a Powerful App Ecosystem

