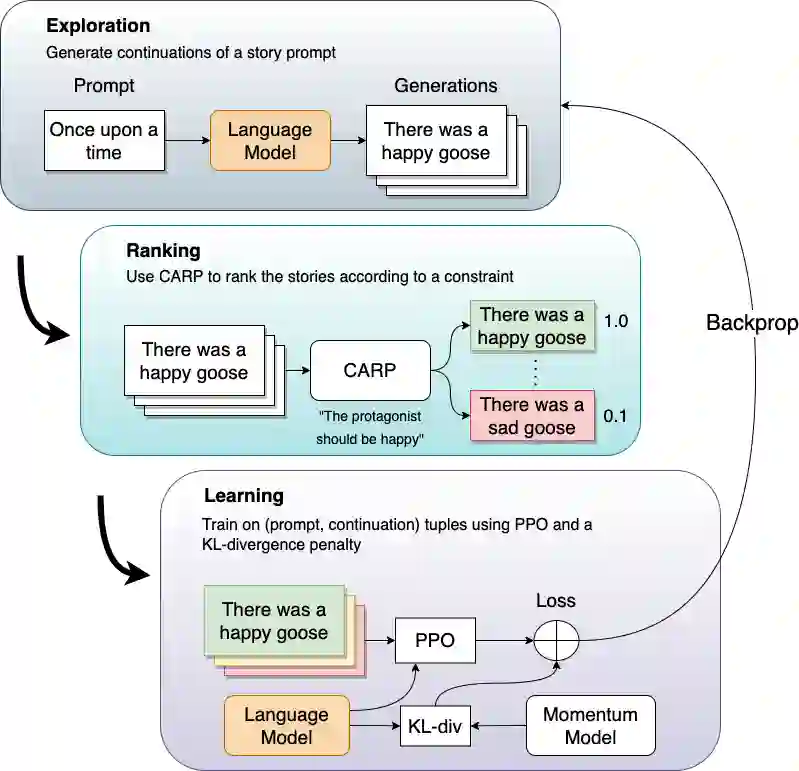
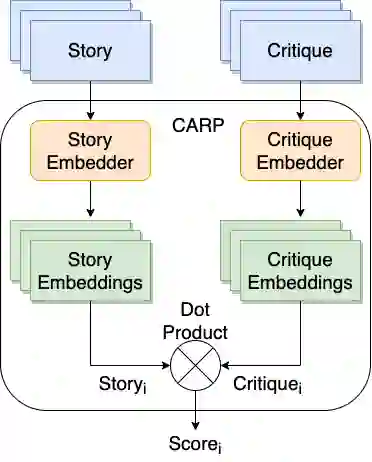
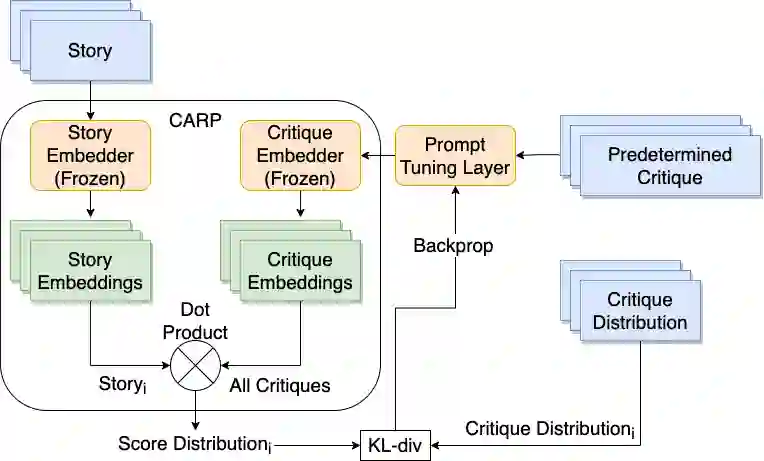
Controlled automated story generation seeks to generate natural language stories satisfying constraints from natural language critiques or preferences. Existing methods to control for story preference utilize prompt engineering which is labor intensive and often inconsistent. They may also use logit-manipulation methods which require annotated datasets to exist for the desired attributes. To address these issues, we first train a contrastive bi-encoder model to align stories with corresponding human critiques, named CARP, building a general purpose preference model. This is subsequently used as a reward function to fine-tune a generative language model via reinforcement learning. However, simply fine-tuning a generative language model with a contrastive reward model does not always reliably result in a story generation system capable of generating stories that meet user preferences. To increase story generation robustness we further fine-tune the contrastive reward model using a prompt-learning technique. A human participant study is then conducted comparing generations from our full system, ablations, and two baselines. We show that the full fine-tuning pipeline results in a story generator preferred over a LLM 20x as large as well as logit-based methods. This motivates the use of contrastive learning for general purpose human preference modeling.
翻译:现有的故事偏好控制方法使用迅速的工程,这种工程是劳力密集的,而且往往不一致。它们还可能使用逻辑管理方法,这种方法要求存在附加注释的数据集,以达到理想的属性。为了解决这些问题,我们首先培训一个对比的双相码模型,以便将故事与相应的人类评论、名为CARP的CARP的人类评论联系起来,建立一个通用目的偏好模型。这随后被用作奖励功能,通过强化学习微调一种基因化语言模型。然而,简单微调一种配有对比性奖赏模型的基因化语言模型并不总是可靠地产生能够产生符合用户喜好的故事的生成系统。为了提高故事的活力,我们用迅速学习技术进一步微调对比性奖赏模型。然后进行一项人类参与者研究,将我们整个系统的几代人、缩略图和两个基线进行比较。我们显示,完全微调试管的结果是故事生成者喜欢的LM 20 和基于逻辑的模型方法。这鼓励了人类对比性学习一般偏好方法。