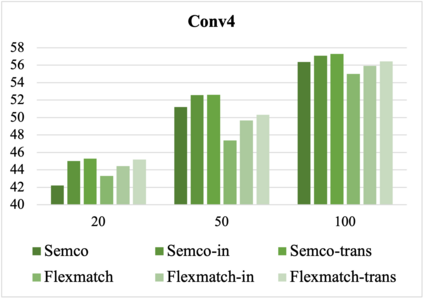
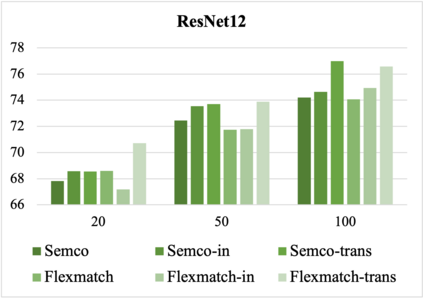
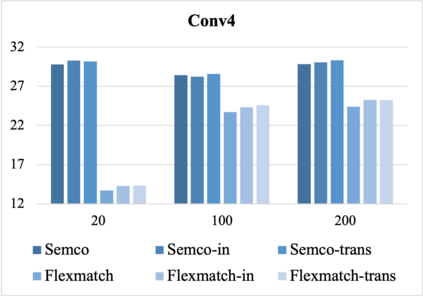
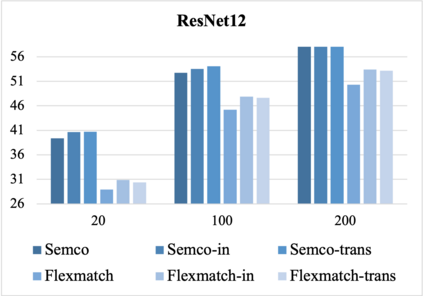
Most existing few-shot learning (FSL) methods require a large amount of labeled data in meta-training, which is a major limit. To reduce the requirement of labels, a semi-supervised meta-training (SSMT) setting has been proposed for FSL, which includes only a few labeled samples and numbers of unlabeled samples in base classes. However, existing methods under this setting require class-aware sample selection from the unlabeled set, which violates the assumption of unlabeled set. In this paper, we propose a practical semi-supervised meta-training setting with truly unlabeled data to facilitate the applications of FSL in realistic scenarios. To better utilize both the labeled and truly unlabeled data, we propose a simple and effective meta-training framework, called pseudo-labeling based meta-learning (PLML). Firstly, we train a classifier via common semi-supervised learning (SSL) and use it to obtain the pseudo-labels of unlabeled data. Then we build few-shot tasks from labeled and pseudo-labeled data and design a novel finetuning method with feature smoothing and noise suppression to better learn the FSL model from noise labels. Surprisingly, through extensive experiments across two FSL datasets, we find that this simple meta-training framework effectively prevents the performance degradation of various FSL models under limited labeled data, and also significantly outperforms the state-of-the-art SSMT models. Besides, benefiting from meta-training, our method also improves two representative SSL algorithms as well.
翻译:大多数小样本学习(Few-Shot Learning,FSL)方法需要大量标记数据用于元训练,这是一个主要限制。为了减少标记数据的要求,提出了半监督元训练(Semi-Supervised Meta-Training,SSMT)设置用于FSL,其中只包括少量基类别标记样本和无标记样本。然而,现有方法针对这种情况需要从无标记集合中进行有意识的样本选择,这违背了无标记集合的假设。本文提出了一个实际的半监督元训练设置,使用真正的无标记数据来促进FSL在实际情况下的应用。为了更好地利用有标记和真正无标记的数据,我们提出了一个简单而有效的元训练框架,称为基于伪标注的元学习(Pseudo-Labeling Based Meta-Learning,PLML)。首先,我们通过常见的半监督学习(Semi-Supervised Learning,SSL)训练分类器,并使用它来获得无标记数据的伪标签。然后,我们使用有标记和伪标签的数据构建小样本任务,并设计了一种新颖的微调方法,通过特征平滑和噪声抑制来更好地学习FSL模型。令人惊讶的是,在两个FSL数据集上的大量实验证明,该简单的元训练框架有效地防止了各种FSL模型在有限有标记数据下的性能下降,而且显著优于现有的SSMT模型。此外,由于元训练的好处,我们的方法还改善了两种代表性的SSL算法。