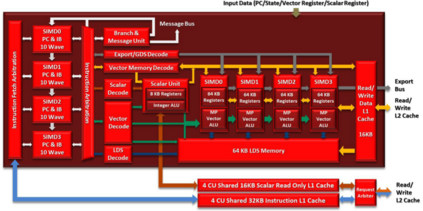
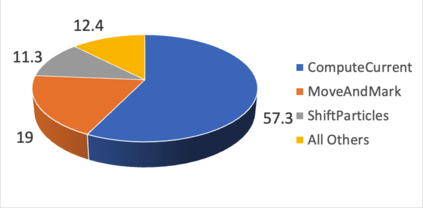
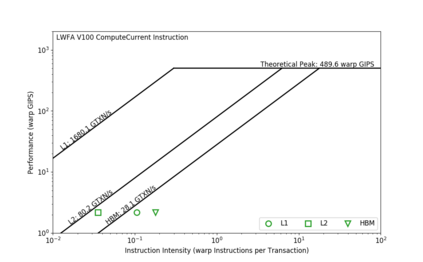
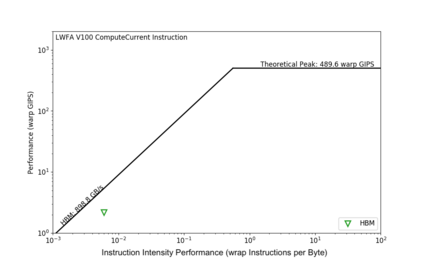
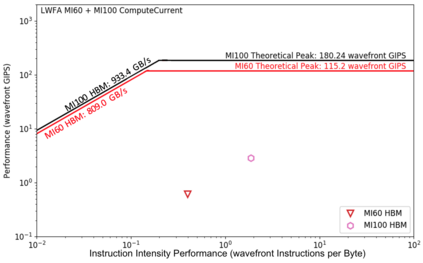
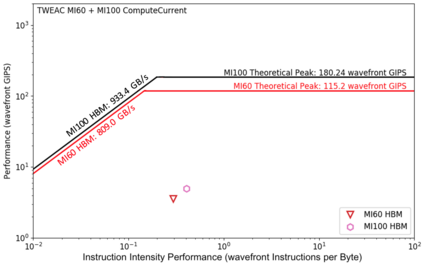
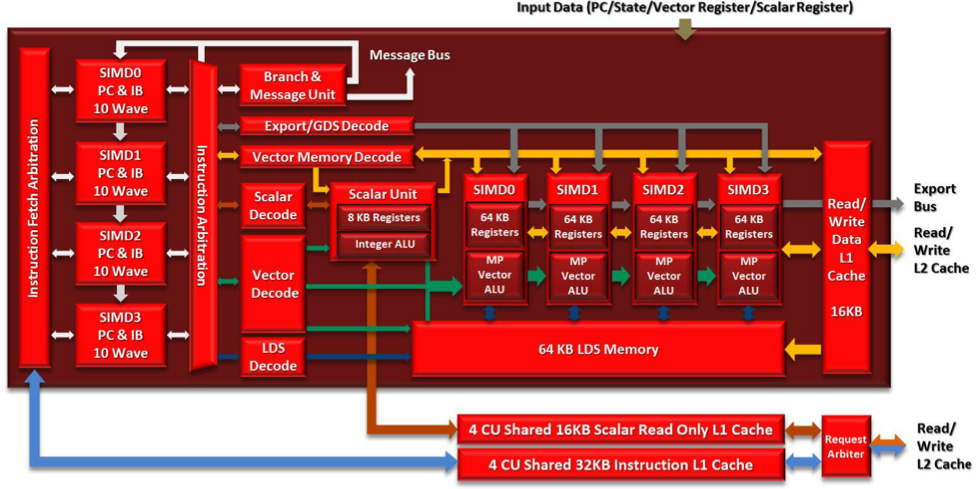
Due to the recent announcement of the Frontier supercomputer, many scientific application developers are working to make their applications compatible with AMD architectures (CPU-GPU), which means moving away from the traditional CPU and NVIDIA-GPU systems. Due to the current limitations of profiling tools for AMD GPUs, this shift leaves a void in how to measure application performance on AMD GPUs. In this paper, we design an instruction roofline model for AMD GPUs using AMD's ROCProfiler and a benchmarking tool, BabelStream (the HIP implementation), as a way to measure an application's performance in instructions and memory transactions on new AMD hardware. Specifically, we create instruction roofline models for a case study scientific application, PIConGPU, an open source particle-in-cell (PIC) simulations application used for plasma and laser-plasma physics on the NVIDIA V100, AMD Radeon Instinct MI60, and AMD Instinct MI100 GPUs. When looking at the performance of multiple kernels of interest in PIConGPU we find that although the AMD MI100 GPU achieves a similar, or better, execution time compared to the NVIDIA V100 GPU, profiling tool differences make comparing performance of these two architectures hard. When looking at execution time, GIPS, and instruction intensity, the AMD MI60 achieves the worst performance out of the three GPUs used in this work.
翻译:由于边境超级计算机的最近宣布,许多科学应用开发者正在努力使其应用程序与AMD架构(CPU-GPU)兼容,这意味着从传统的 CPU 和 NVIDIA-GPU 系统向传统 CPU 和 NVIDIA-GPU 系统转移。由于目前AMD GPU 的特征工具有限,这一转变在如何测量AMD GPU 应用性能方面留下了一个空白。在本文中,我们使用AMD的 ROC Profileer 和一个基准工具 BabelStream 设计了AMD GPU 的指令性能模型。 BabelStream (HIP 实施) 是为了测量应用程序在新的AMD硬件指令和记忆交易中的性能。具体来说,我们为案例研究应用程序创建了指导性能模型,PIConGPPP(PPP),这是用于 NVDIA V100 、AM 和 IMBM 3 的性能比对 GPI 工具进行更好的执行。