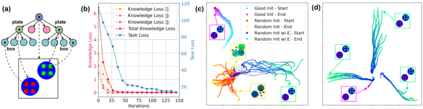
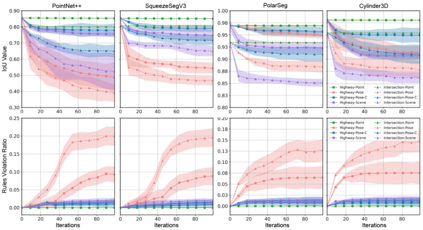
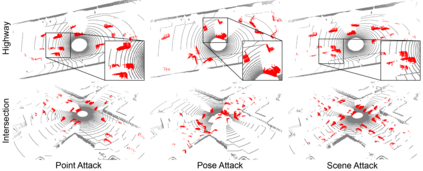
Generating adversarial scenarios, which have the potential to fail autonomous driving systems, provides an effective way to improve the robustness. Extending purely data-driven generative models, recent specialized models satisfy additional controllable requirements such as embedding a traffic sign in a driving scene by manipulating patterns implicitly in the neuron level. In this paper, we introduce a method to incorporate domain knowledge explicitly in the generation process to achieve the Semantically Adversarial Generation (SAG). To be consistent with the composition of driving scenes, we first categorize the knowledge into two types, the property of objects and the relationship among objects. We then propose a tree-structured variational auto-encoder (T-VAE) to learn hierarchical scene representation. By imposing semantic rules on the properties of nodes and edges in the tree structure, explicit knowledge integration enables controllable generation. We construct a synthetic example to illustrate the controllability and explainability of our method in a succinct setting. We further extend to realistic environments for autonomous vehicles: our method efficiently identifies adversarial driving scenes against different state-of-the-art 3D point cloud segmentation models and satisfies the traffic rules specified as the explicit knowledge.
翻译:产生对抗情景,有可能使自动驾驶系统失效,为改进稳健性提供了有效途径。推广纯数据驱动的基因模型,最近的专门模型满足了额外的可控性要求,例如通过隐含的神经神经层面的操纵模式,将交通标志嵌入驾驶场中。在本文件中,我们引入了一种方法,将域知识明确纳入生产过程,以实现Semantical Aversarial General(SAG) 。为了与驾驶场的构成保持一致,我们首先将知识分为两类,即物体属性和物体之间的关系。然后我们提出了树形变形自动编码(T-VAE)以学习分级场面代表。通过对节点和树结构边缘的特性实施语义化规则,明确的知识整合使得能够控制生成。我们建立了一个综合范例,以说明我们方法在简洁的环境中的可控性和可解释性。我们进一步将自动飞行器的实用环境分为两种类型:我们的方法有效地辨别了对不同状态的3D点云层断面截面模型的对立面驱动场景,并满足明确的交通规则。