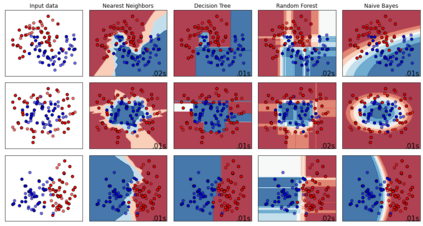
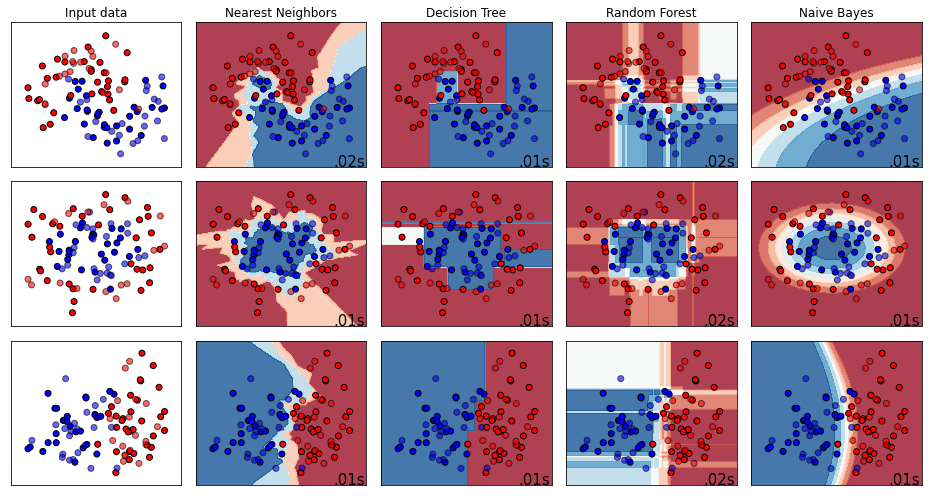
Performance comparison of supervised machine learning (ML) models are widely done in terms of different confusion matrix based scores obtained on test datasets. However, a dataset comprises several instances having different difficulty levels. Therefore, it is more logical to compare effectiveness of ML models on individual instances instead of comparing scores obtained for the entire dataset. In this paper, an alternative approach is proposed for direct comparison of supervised ML models in terms of individual instances within the dataset. A direct comparison matrix called \emph{Prayatul Matrix} is introduced, which accounts for comparative outcome of two ML algorithms on different instances of a dataset. Five different performance measures are designed based on prayatul matrix. Efficacy of the proposed approach as well as designed measures is analyzed with four classification techniques on three datasets. Also analyzed on four large-scale complex image datasets with four deep learning models namely ResNet50V2, MobileNetV2, EfficientNet, and XceptionNet. Results are evident that the newly designed measure are capable of giving more insight about the comparing ML algorithms, which were impossible with existing confusion matrix based scores like accuracy, precision and recall.
翻译:监督机学习模型的性能比较,在测试数据集中获得的基于不同混乱矩阵的分数方面,广泛进行了监督机学习模型(ML)的性能比较,然而,数据集包括若干具有不同难度的事例。因此,比较ML模型在个别事例上的有效性,而不是比较整个数据集的得分,更符合逻辑。在本文中,提议了一种替代办法,直接比较数据集内受监督的ML模型的个别事例。引入了一个称为 emph{Prayatul 矩阵}的直接比较矩阵,该矩阵记录了两个ML算法在不同数据集实例上的比较结果。五个不同的性能措施是根据祈祷矩阵设计的。用三种数据集的四种分类技术分析了拟议方法和设计措施的有效性。还分析了四个大型复杂图像数据集,四个深度学习模型,即ResNet50V2、移动网络2、高效网络和XceptionionNet。结果明显显示,新设计的计量能够更深入地了解对ML算法的比较结果,这五个不同的性尺度是无法与现有的以精确性、精确和回收等分类为基础的混乱矩阵相比较。