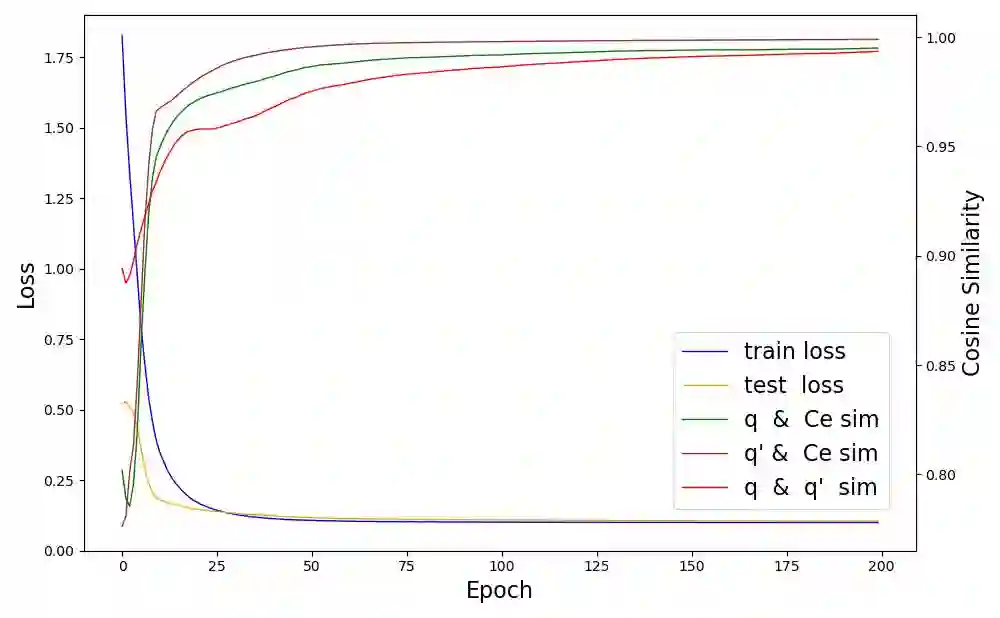
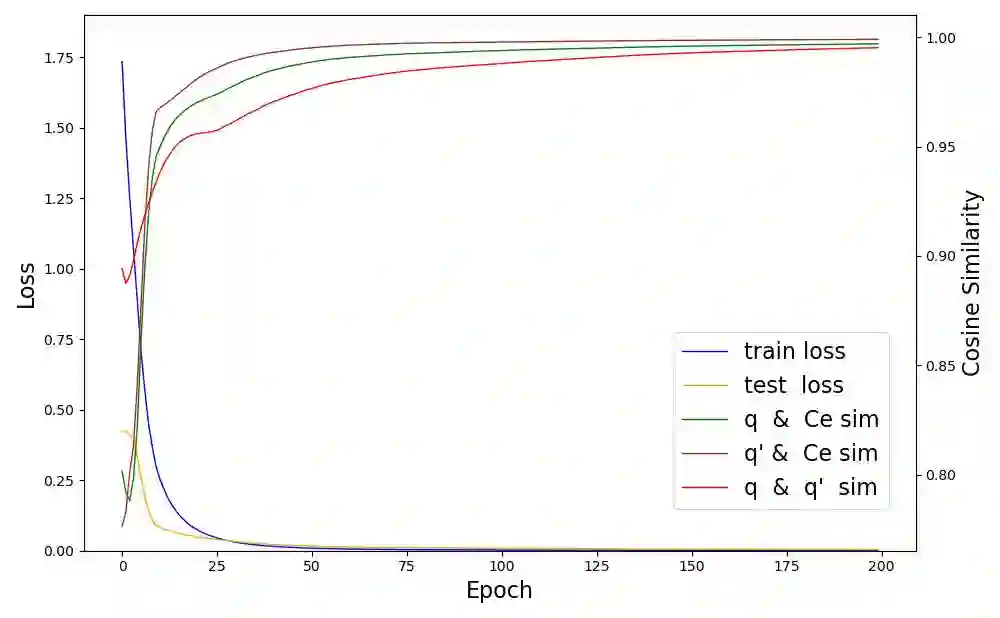
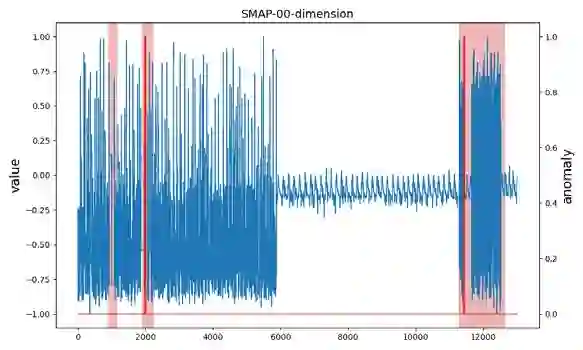
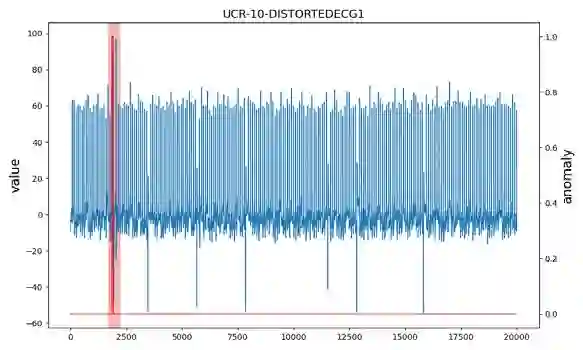
The accumulation of time series data and the absence of labels make time-series Anomaly Detection (AD) a self-supervised deep learning task. Single-assumption-based methods may only touch on a certain aspect of the whole normality, not sufficient to detect various anomalies. Among them, contrastive learning methods adopted for AD always choose negative pairs that are both normal to push away, which is objecting to AD tasks' purpose. Existing multi-assumption-based methods are usually two-staged, firstly applying a pre-training process whose target may differ from AD, so the performance is limited by the pre-trained representations. This paper proposes a deep Contrastive One-Class Anomaly detection method of time series (COCA), which combines the normality assumptions of contrastive learning and one-class classification. The key idea is to treat the representation and reconstructed representation as the positive pair of negative-samples-free contrastive learning, and we name it sequence contrast. Then we apply a contrastive one-class loss function composed of invariance and variance terms, the former optimizing loss of the two assumptions simultaneously, and the latter preventing hypersphere collapse. Extensive experiments conducted on four real-world time-series datasets show the superior performance of the proposed method achieves state-of-the-art. The code is publicly available at https://github.com/ruiking04/COCA.
翻译:时间序列数据的积累和标签的缺失使得时间序列异常检测(AD)成为自我监督的深层次学习任务。基于单一假设的方法可能只触及整个正常度的某个方面,不足以发现各种异常现象。其中,对反倾销的对比式学习方法总是选择通常会推走的反对,这与反倾销任务的目的相左。现有的基于多重假设的方法通常分为两个阶段,首先采用目标可能不同于反倾销的训练前程序,因此绩效受培训前的演示的限制。本文建议采用深度对比性一类异常检测时间序列(COCA)的某些方面,这种方法将对比性学习的正常性假设和一等分类结合起来。关键的想法是将代表制和重组代表制视为正对无反抽样对比学习的正对,我们称之为顺序对比。然后,我们采用了由差异性和差异性条件组成的对比性一等级损失功能,因此绩效受培训前的表述所限制。本文提出了深度对比性一类的单一异常测试方法(COCAOCA)的时间序列(COCA)系列时间序列(COCA)序列(COCA)系列/CLI-S-CS-S-CLAD-S-S-C-C-S-S-S-C-S-S-S-S-C-S-Slentents-S-C-S