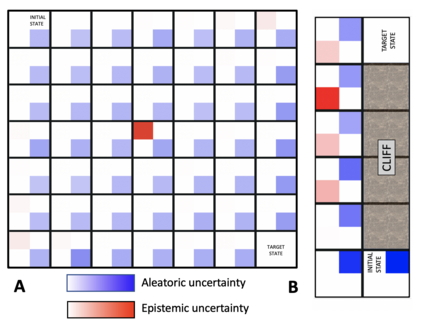
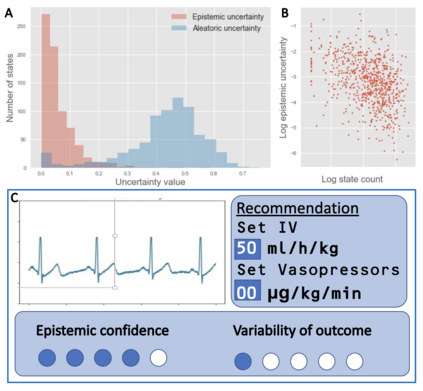
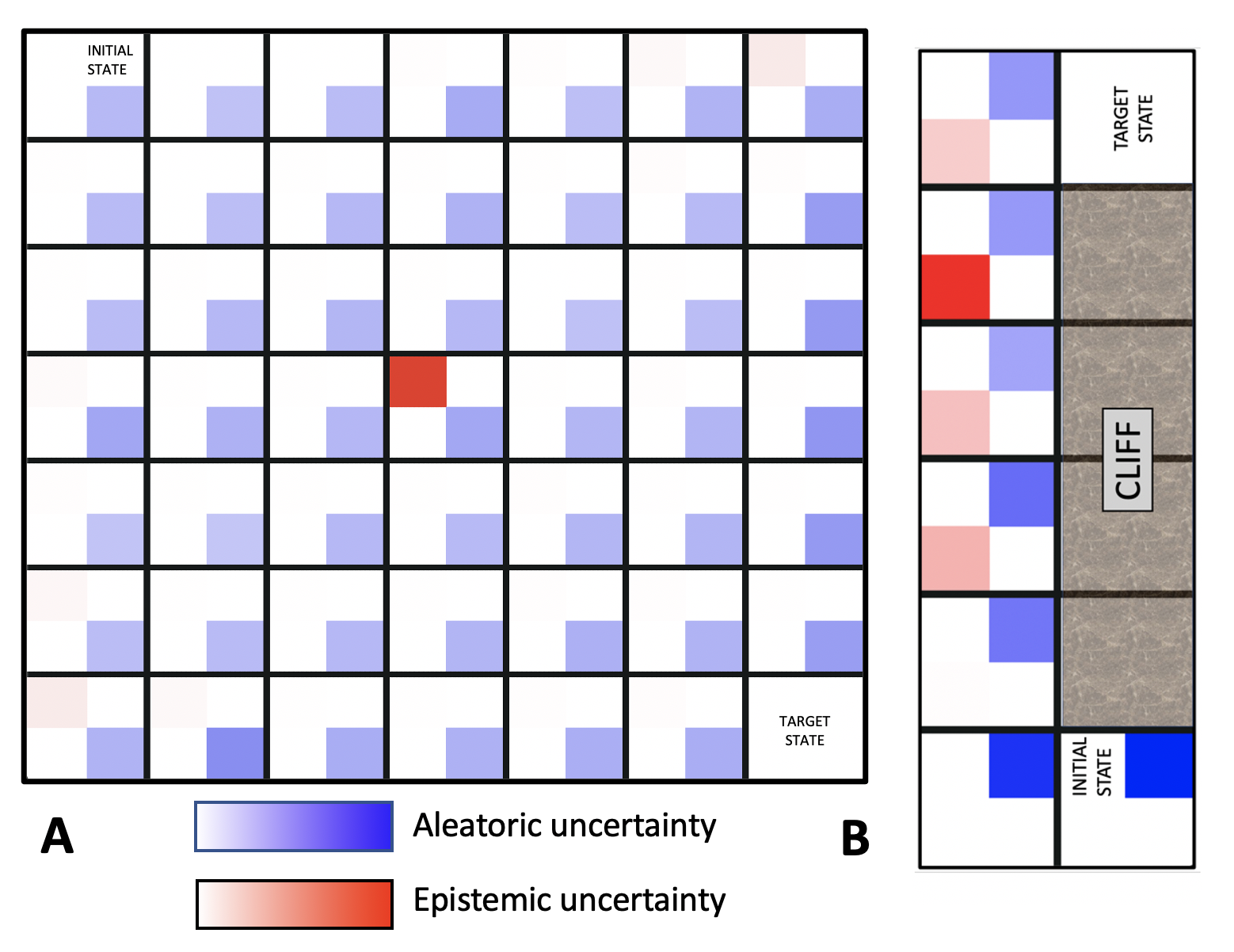
Reinforcement Learning (RL) is emerging as tool for tackling complex control and decision-making problems. However, in high-risk environments such as healthcare, manufacturing, automotive or aerospace, it is often challenging to bridge the gap between an apparently optimal policy learnt by an agent and its real-world deployment, due to the uncertainties and risk associated with it. Broadly speaking RL agents face two kinds of uncertainty, 1. aleatoric uncertainty, which reflects randomness or noise in the dynamics of the world, and 2. epistemic uncertainty, which reflects the bounded knowledge of the agent due to model limitations and finite amount of information/data the agent has acquired about the world. These two types of uncertainty carry fundamentally different implications for the evaluation of performance and the level of risk or trust. Yet these aleatoric and epistemic uncertainties are generally confounded as standard and even distributional RL is agnostic to this difference. Here we propose how a distributional approach (UA-DQN) can be recast to render uncertainties by decomposing the net effects of each uncertainty. We demonstrate the operation of this method in grid world examples to build intuition and then show a proof of concept application for an RL agent operating as a clinical decision support system in critical care
翻译:加强强化学习(RL)正在成为解决复杂控制和决策问题的工具,然而,在保健、制造、汽车或航空航天等高风险环境中,由于不确定性和风险相关风险,往往难以弥合代理人所学会的明显最佳政策与实际部署之间差距。 广义而言,RL代理面临着两种不确定性,一种是悬殊的不确定性,反映了世界动态中的随机或噪音,另一种是典型限制和代理人获得的有限信息/数据数量有限,从而反映了代理人对世界的了解受限制,但在这种高风险环境中,如保健、制造、汽车或航空航天,由于与该代理人的不确定性相关的不确定性及其实际部署和风险或信任程度的不确定性之间的差别往往难以弥合。 广义而言,RL代理机构面临两种不确定性,一种是标准的,甚至分布式RL公司也是这种差异的敏感因素。 我们在这里建议如何重新推导出一种分配式方法(UA-DQN),通过分解每一种不确定性的净影响而造成不确定性。我们证明,这两种不确定性对业绩评价以及风险或信任程度具有根本不同的影响。然而,这些偏差和概括性的不确定性一般是混杂的,因为标准,甚至分布式的R代理机构系统在运行概念中可以证明一种关键的临床操作方法的应用。