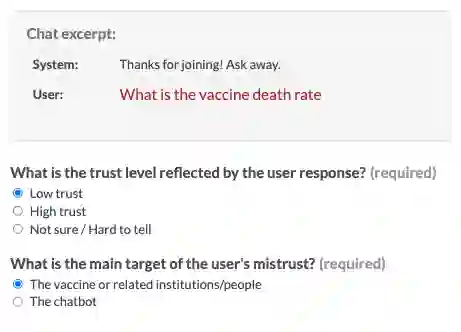
Public trust in medical information is crucial for successful application of public health policies such as vaccine uptake. This is especially true when the information is offered remotely, by chatbots, which have become increasingly popular in recent years. Here, we explore the challenging task of human-bot turn-level trust classification. We rely on a recently released data of observationally-collected (rather than crowdsourced) dialogs with VIRA chatbot, a COVID-19 Vaccine Information Resource Assistant. These dialogs are centered around questions and concerns about COVID-19 vaccines, where trust is particularly acute. We annotated $3k$ VIRA system-user conversational turns for Low Institutional Trust or Low Agent Trust vs. Neutral or High Trust. We release the labeled dataset, VIRATrustData, the first of its kind to the best of our knowledge. We demonstrate how this task is non-trivial and compare several models that predict the different levels of trust.
翻译:公众信任医疗信息对于成功应用诸如疫苗摄取等公共卫生政策至关重要。 当信息由近年来越来越受欢迎的聊天机远程提供时,这一点就更为重要。 在这里,我们探索人类机器人转换信任分类的艰巨任务。 我们依靠最近发布的与COVID-19疫苗信息资源助理VIRA Shabot(而不是众源)进行观测收集的(而不是众源)对话的数据。 这些对话围绕对信任特别尖锐的COVID-19疫苗的问题和关切。 我们为低机构信任或低代理信任对中立或高信任的3k$ VIRA系统用户对话转转。 我们发布了标签数据集VIRATRustData,这是我们最了解的首个此类数据。 我们展示了这项任务是如何不起作用的,并比较了预测不同信任水平的几个模型。