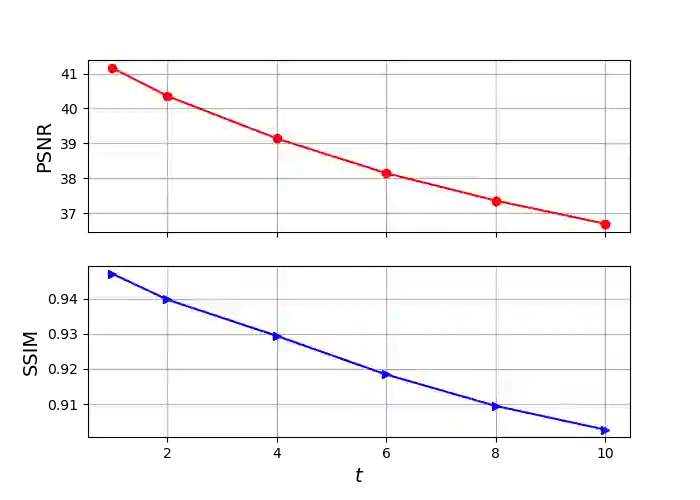
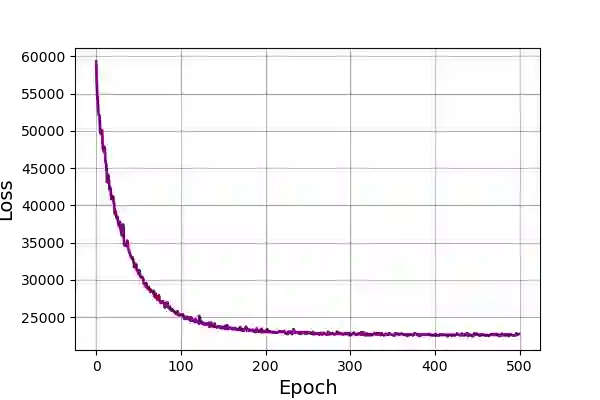
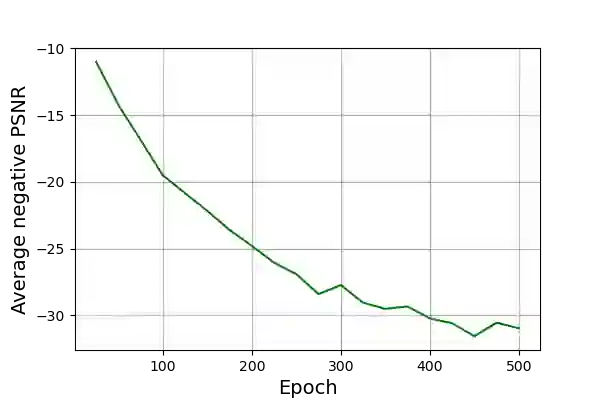
Wildfire forecasting has been one of the most critical tasks that humanities want to thrive. It plays a vital role in protecting human life. Wildfire prediction, on the other hand, is difficult because of its stochastic and chaotic properties. We tackled the problem by interpreting a series of wildfire images as a video and used it to anticipate how the fire would behave in the future. However, creating video prediction models that account for the inherent uncertainty of the future is challenging. The bulk of published attempts is based on stochastic image-autoregressive recurrent networks, which raises various performance and application difficulties, such as computational cost and limited efficiency on massive datasets. Another possibility is to use entirely latent temporal models that combine frame synthesis and temporal dynamics. However, due to design and training issues, no such model for stochastic video prediction has yet been proposed in the literature. This paper addresses these issues by introducing a novel stochastic temporal model whose dynamics are driven in a latent space. It naturally predicts video dynamics by allowing our lighter, more interpretable latent model to beat previous state-of-the-art approaches on the GOES-16 dataset. Results will be compared towards various benchmarking models.
翻译:野火预报是人类希望兴旺发展的最关键任务之一。 它在保护人类生命方面发挥着关键作用。 另一方面,野火预测由于其随机和混乱的特性而困难重重。 我们通过将一系列野火图像解读为视频来解决这个问题,并用它来预测火灾未来将如何发生。然而,创建视频预测模型来说明未来固有的不确定性是具有挑战性的。 大部分已公布的尝试都基于随机图像-视觉反向循环网络,这增加了各种性能和应用困难,例如计算成本和大规模数据集的效率有限。 另一种可能性是使用完全潜在的时间模型,将框架合成和时间动态结合起来。然而,由于设计和培训问题,文献中尚未提出这种模拟视频预测模型。本文通过引入一种新型的随机时间模型来解决这些问题,该模型的动态在暗中驱动。 它自然地预测了视频动态,允许我们的更轻、更可解释的潜在模型在GOES-16数据集上击败先前的状态模型。 将结果对比到各种基准。