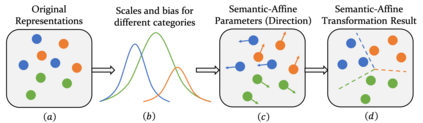
Conventional point cloud semantic segmentation methods usually employ an encoder-decoder architecture, where mid-level features are locally aggregated to extract geometric information. However, the over-reliance on these class-agnostic local geometric representations may raise confusion between local parts from different categories that are similar in appearance or spatially adjacent. To address this issue, we argue that mid-level features can be further enhanced with semantic information, and propose semantic-affine transformation that transforms features of mid-level points belonging to different categories with class-specific affine parameters. Based on this technique, we propose SemAffiNet for point cloud semantic segmentation, which utilizes the attention mechanism in the Transformer module to implicitly and explicitly capture global structural knowledge within local parts for overall comprehension of each category. We conduct extensive experiments on the ScanNetV2 and NYUv2 datasets, and evaluate semantic-affine transformation on various 3D point cloud and 2D image segmentation baselines, where both qualitative and quantitative results demonstrate the superiority and generalization ability of our proposed approach. Code is available at https://github.com/wangzy22/SemAffiNet.
翻译:常规点云分解法通常使用一种编码器-分解器结构,在这种结构中,中层特征在当地汇总,以提取几何信息;然而,过分依赖这些等级不可知的地方几何表示法,可能会造成不同类别、外观相似或空间相邻的局部部分之间的混乱;为解决这一问题,我们认为,中层特征可以通过语义信息进一步加强,并提议语义-情感转换,以转换属于不同类别、有特定等级的分解参数的中层点特征。基于这一技术,我们提议SemAffiNet用于点云分解,利用变异器模块的注意机制,隐含和明确获取地方部分的全球结构知识,以便全面理解每一类别。我们在ScanNetV2和NYUv2数据集上进行了广泛的实验,并评价了3D点云和2D图像分解基线上的语义-等分解转换。 我们的定性和定量结果都表明了我们拟议方法的优越性和一般化能力,可在 https://giusuffem/wangem/com查阅《守则》。