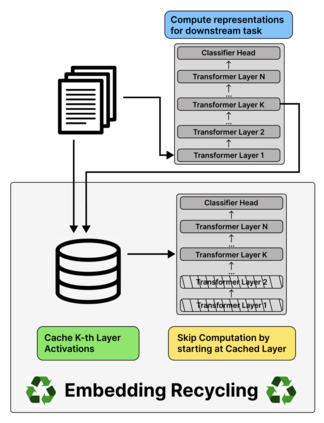
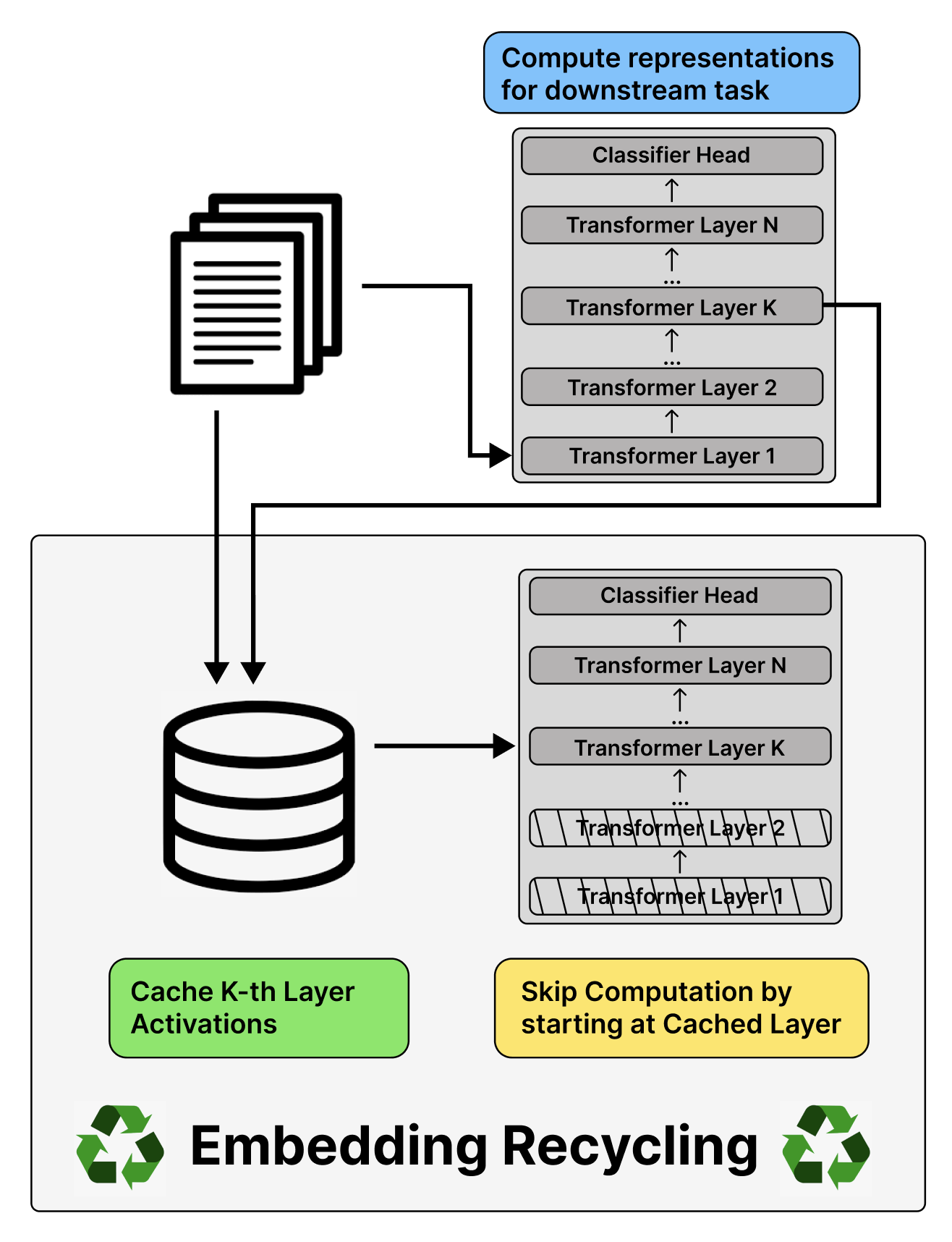
Training and inference with large neural models is expensive. However, for many application domains, while new tasks and models arise frequently, the underlying documents being modeled remain mostly unchanged. We study how to decrease computational cost in such settings through embedding recycling (ER): re-using activations from previous model runs when performing training or inference. In contrast to prior work focusing on freezing small classification heads for finetuning which often leads to notable drops in performance, we propose caching an intermediate layer's output from a pretrained model and finetuning the remaining layers for new tasks. We show that our method provides a 100% speedup during training and a 55-86% speedup for inference, and has negligible impacts on accuracy for text classification and entity recognition tasks in the scientific domain. For general-domain question answering tasks, ER offers a similar speedup and lowers accuracy by a small amount. Finally, we identify several open challenges and future directions for ER.
翻译:大型神经模型的培训和推论费用昂贵。 但是,对于许多应用领域而言,虽然新任务和模型经常出现,但正在建模的基本文件基本保持不变。我们研究如何通过嵌入循环利用(ER):在进行培训或推理时,重新使用先前模型的启动功能。与以前侧重于冻结小型分类头进行微调的工作相比,我们建议从预先训练模式中缓存中间层的输出,并微调剩余层的新任务。我们表明,我们的方法在培训期间提供了100%的加速率,在推断过程中提供了55-86%的加速率,对科学领域的文本分类和实体识别任务的准确性影响微乎其微。对于一般性回答任务,ER提供了类似的加速率和小量的低精度。最后,我们为ER找出了一些公开的挑战和未来的方向。