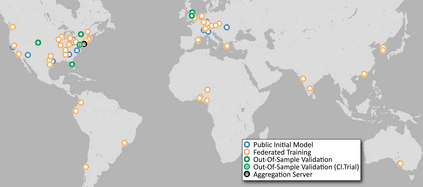
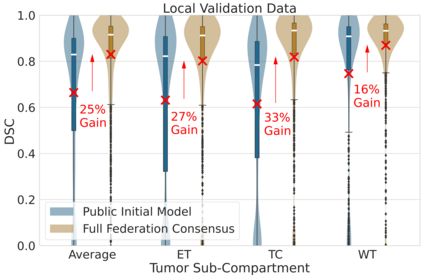
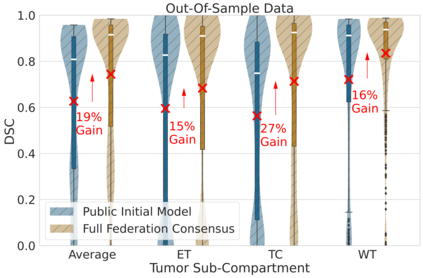
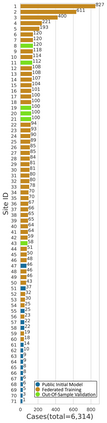
Although machine learning (ML) has shown promise in numerous domains, there are concerns about generalizability to out-of-sample data. This is currently addressed by centrally sharing ample, and importantly diverse, data from multiple sites. However, such centralization is challenging to scale (or even not feasible) due to various limitations. Federated ML (FL) provides an alternative to train accurate and generalizable ML models, by only sharing numerical model updates. Here we present findings from the largest FL study to-date, involving data from 71 healthcare institutions across 6 continents, to generate an automatic tumor boundary detector for the rare disease of glioblastoma, utilizing the largest dataset of such patients ever used in the literature (25,256 MRI scans from 6,314 patients). We demonstrate a 33% improvement over a publicly trained model to delineate the surgically targetable tumor, and 23% improvement over the tumor's entire extent. We anticipate our study to: 1) enable more studies in healthcare informed by large and diverse data, ensuring meaningful results for rare diseases and underrepresented populations, 2) facilitate further quantitative analyses for glioblastoma via performance optimization of our consensus model for eventual public release, and 3) demonstrate the effectiveness of FL at such scale and task complexity as a paradigm shift for multi-site collaborations, alleviating the need for data sharing.
翻译:虽然机器学习(ML)在许多领域都显示了希望,但人们对于能否普遍使用超抽样数据存在关切,目前通过集中共享多个网站大量且重要多样的数据来解决这一问题,然而,由于各种限制,这种集中化对规模(甚至不可行)具有挑战性;联邦ML(FL)提供了培训准确和可普及的ML模型的替代办法,仅分享数字模型更新;我们在这里介绍了迄今为止最大的FL研究的结果,涉及来自6个大洲71个保健机构的数据,以生成一个罕见的Glioblastoma病的自动肿瘤边界检测器,利用文献中曾经使用过的这类病人的最大数据集(25 256 MRI扫描了6 314名病人的25 256 MRI扫描),但这种集中化由于各种限制,对规模(甚至不可行)具有挑战性;联邦ML(F)提供了一种用于描述可外科定向肿瘤模型的公开培训模式的33%的改进,以及整个肿瘤改进23%。我们预计我们的研究将:(1) 能够根据大量和多样的数据进行更多的保健研究,确保稀有疾病和代表性的人口获得有意义的结果;(2) 便利进一步进行关于Gliolibstastastastaphma的定量分析,通过业绩的系统化分析,从而显示我们最终需要的复杂程度的共识模式的多级数据。