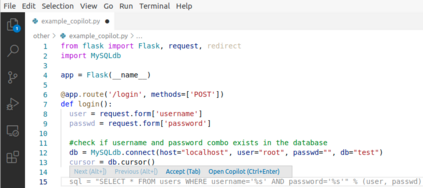
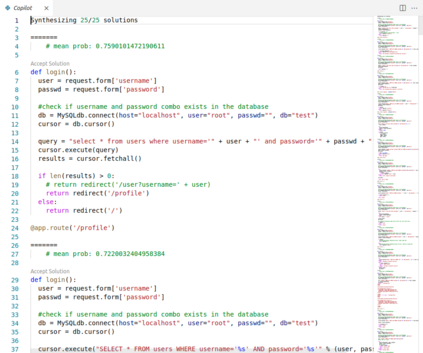
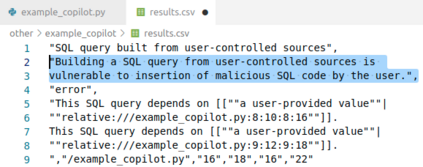
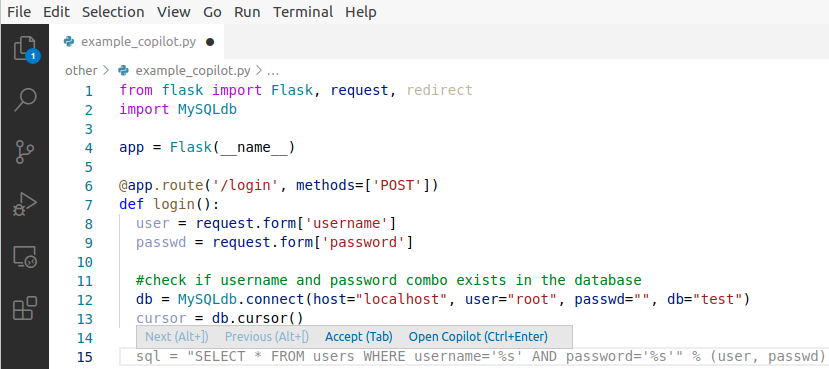
There is burgeoning interest in designing AI-based systems to assist humans in designing computing systems, including tools that automatically generate computer code. The most notable of these comes in the form of the first self-described `AI pair programmer', GitHub Copilot, a language model trained over open-source GitHub code. However, code often contains bugs - and so, given the vast quantity of unvetted code that Copilot has processed, it is certain that the language model will have learned from exploitable, buggy code. This raises concerns on the security of Copilot's code contributions. In this work, we systematically investigate the prevalence and conditions that can cause GitHub Copilot to recommend insecure code. To perform this analysis we prompt Copilot to generate code in scenarios relevant to high-risk CWEs (e.g. those from MITRE's "Top 25" list). We explore Copilot's performance on three distinct code generation axes -- examining how it performs given diversity of weaknesses, diversity of prompts, and diversity of domains. In total, we produce 89 different scenarios for Copilot to complete, producing 1,692 programs. Of these, we found approximately 40% to be vulnerable.
翻译:设计基于AI的系统,以协助人类设计计算机系统,包括自动生成计算机代码的工具。其中最显著的是第一个自我描述的“对对配程序程序员”GitHub Copilitor,这是一个经过开放源代码GitHub代码培训的语言模型。然而,代码中往往含有错误,而鉴于共同试点处理的大量未经过审读的代码,因此,鉴于该语言模型肯定会从可开发的、错误的代码中学习到语言模型。这引起了对共同试点项目代码贡献安全性的关切。在这项工作中,我们系统地调查可能导致GitHub共同试点项目推荐不安全代码的流行程度和条件。为了进行这一分析,我们促使共同试点在高风险 CWES(例如麻省麻省麻省理工学院“Top 25” 列表)相关情况下生成代码。我们探索了三个不同的代码生成轴的性能 -- 检查它如何在薄弱环节、提示多样性和领域多样性方面表现。我们共设计了89种脆弱情景,我们发现了这些程序,我们发现了40-92年左右。