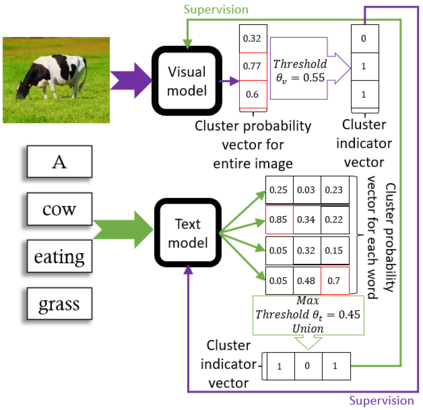
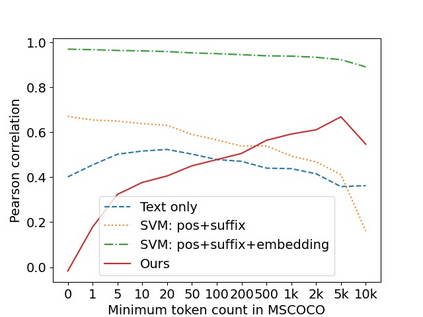
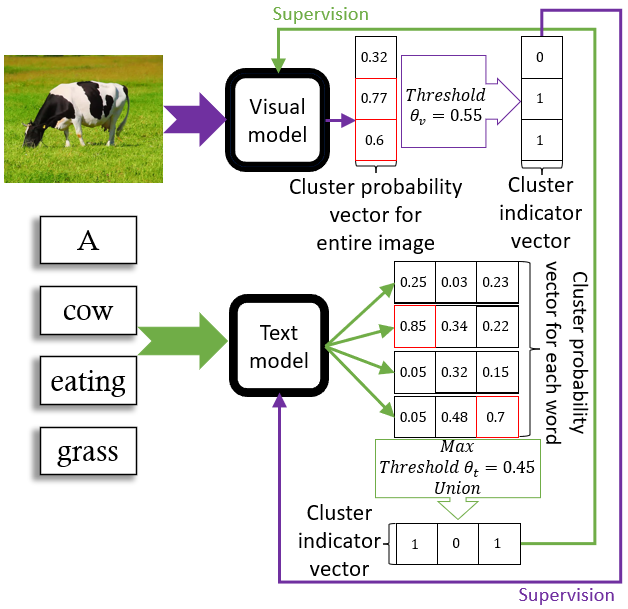
Recent advances in self-supervised modeling of text and images open new opportunities for computational models of child language acquisition, which is believed to rely heavily on cross-modal signals. However, prior studies have been limited by their reliance on vision models trained on large image datasets annotated with a pre-defined set of depicted object categories. This is (a) not faithful to the information children receive and (b) prohibits the evaluation of such models with respect to category learning tasks, due to the pre-imposed category structure. We address this gap, and present a cognitively-inspired, multimodal acquisition model, trained from image-caption pairs on naturalistic data using cross-modal self-supervision. We show that the model learns word categories and object recognition abilities, and presents trends reminiscent of those reported in the developmental literature. We make our code and trained models public for future reference and use.
翻译:在自监督的文本和图像建模方面最近取得的进展为计算获取儿童语言的模式开辟了新的机会,据认为,这种模式在很大程度上依赖跨模式信号;然而,以往的研究由于依赖依靠经过培训的关于大型图像数据集的愿景模型,而受到限制,这些模型附有一套预先界定的描述对象类别,这是:(a) 不忠实于儿童所得到的信息;(b) 由于预先规定的类别结构,禁止对此类模型进行分类学习任务的评估;我们解决了这一差距,并提出了一种认知激励的多式获取模型,由利用跨模式自我监督的自我观察对立的自然数据成型成型模型加以培训;我们展示了这些模型学习文字类别和对象识别能力,并展示了发展文献中所报告的趋势的相似性;我们公开了我们的代码和经过培训的模型,供今后参考和使用。