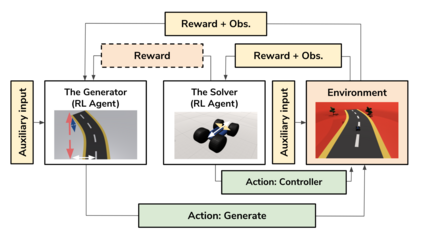
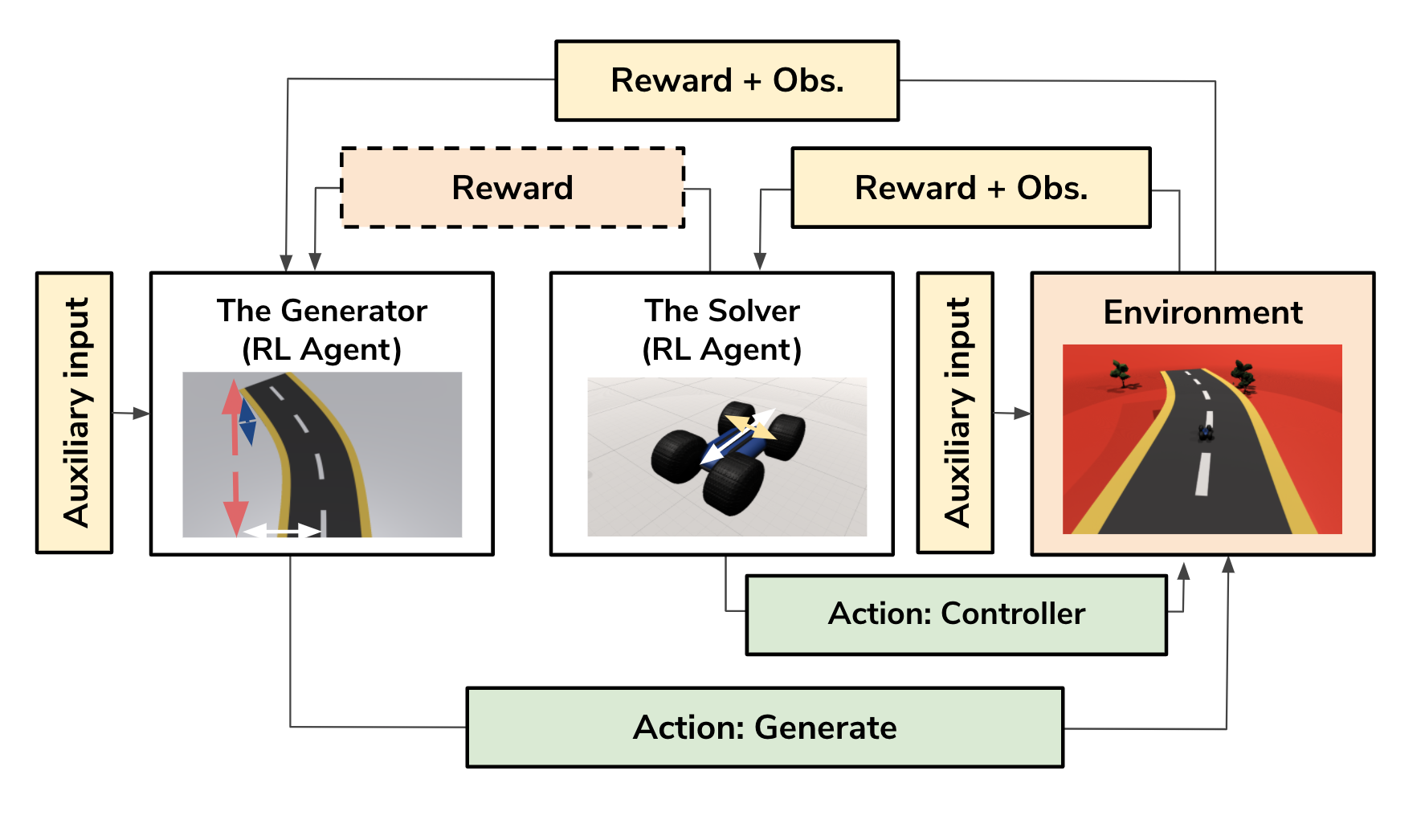
We present an approach for procedural content generation (PCG), and improving generalization in reinforcement learning (RL) agents, by using adversarial deep RL. Training RL agents for generalization over novel environments is a notoriously difficult task. One popular approach is to procedurally generate different environments to increase the generalizability of the trained agents. Here we deploy an adversarial model with one PCG RL agent (called Generator), and one solving RL agent (called Solver). The benefit is mainly two-fold: Firstly, the Solver achieves better generalization through the generated challenges from the Generator. Secondly, the trained Generator can be used as a creator of novel environments that, together with the Solver, can be shown to be solvable. The Generator receives a reward signal based on the performance of the Solver which encourages the environment design to be challenging but not impossible. To further drive diversity and control of the environment generation, we propose the use of auxiliary inputs for the Generator. Thus, we propose adversarial RL for procedural content generation (ARLPCG), an adversarial approach which procedurally generates previously unseen environments with an auxiliary input as a control variable. Herein we describe this concept in detail and compare it with previous methods showing improved generalization, as well as a new method to create novel environments.
翻译:我们提出了一个程序内容生成方法,并通过使用对抗性深度RL来改进强化学习(RL)代理物的普及,从而改进强化学习(RL)代理物的普及,这是一个臭名昭著的困难任务。培训RL代理物对新环境进行普及化培训是一种流行的方法,在程序上创造不同的环境,以提高受过训练的代理物的通用性。我们在这里采用了一个带有PCG RL代理物(所谓的发电机)和一个解决RL代理物(称为Solverer)的对抗性模式。其好处主要有两个方面:首先,解决器通过生成发电机产生的挑战,更好地实现强化学习(RLL)的普及化。第二,受过训练的发电机可以用作创造新环境的创造者,这些新环境与解决器一起,可以证明是可溶解的。根据溶剂的性能产生一种奖励信号,鼓励环境设计具有挑战性,但并非不可能。为了进一步推动环境生成的多样化和控制,我们建议使用辅助性投入物(称为Solverger)。因此,我们建议对程序内容生成采用对抗性RLPG,这是一种在程序上产生程序上创造的对抗性环境,在程序上产生一种程序上产生一种可视环境,在程序上产生一种辅助性的环境,在程序上产生一种辅助性的投入投入物,可以与辅助性的投入性投入物作比较,将它作为新的概念的比较为一种可变式。我们在这里将它作为新的环境的比较。我们用的方法,用的方法,这里将这种解释。我们将这种解释式地描述为一种可比较,将它作为新的方法,将它作为新的环境的比较。