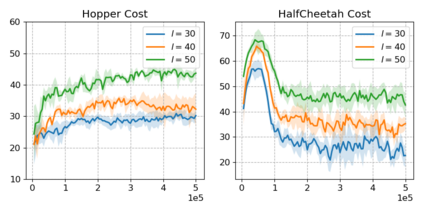
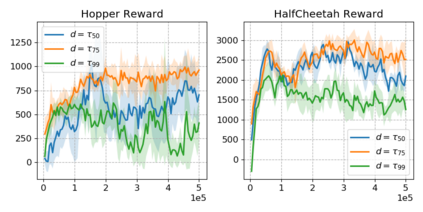
We study the problem of safe offline reinforcement learning (RL), the goal is to learn a policy that maximizes long-term reward while satisfying safety constraints given only offline data, without further interaction with the environment. This problem is more appealing for real world RL applications, in which data collection is costly or dangerous. Enforcing constraint satisfaction is non-trivial, especially in offline settings, as there is a potential large discrepancy between the policy distribution and the data distribution, causing errors in estimating the value of safety constraints. We show that na\"ive approaches that combine techniques from safe RL and offline RL can only learn sub-optimal solutions. We thus develop a simple yet effective algorithm, Constraints Penalized Q-Learning (CPQ), to solve the problem. Our method admits the use of data generated by mixed behavior policies. We present a theoretical analysis and demonstrate empirically that our approach can learn robustly across a variety of benchmark control tasks, outperforming several baselines.
翻译:我们研究安全离线强化学习(RL)的问题,目标是学习一种政策,在满足安全限制的同时,最大限度地增加长期奖励,同时满足只有离线数据的安全限制,而不与环境进一步互动。这个问题更有利于真实世界的RL应用,因为数据收集成本高或危险。强制限制满意度是非三重性的,特别是在离线环境中,因为政策分配和数据分配之间可能存在很大的差异,在估计安全限制的价值方面造成错误。我们显示,将安全 RL 和离线RL 技术结合起来的NA\“动态方法”只能学习亚最佳解决方案。因此,我们制定了简单而有效的算法,即惩罚性Q-学习(CPQ),以解决问题。我们的方法承认使用混合行为政策产生的数据。我们提出理论分析,并用经验证明,我们的方法可以有力地学习各种基准控制任务,超过几个基准。