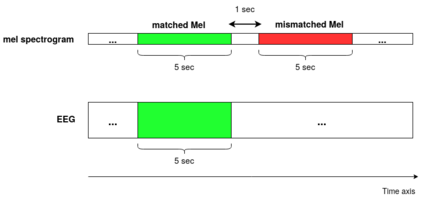
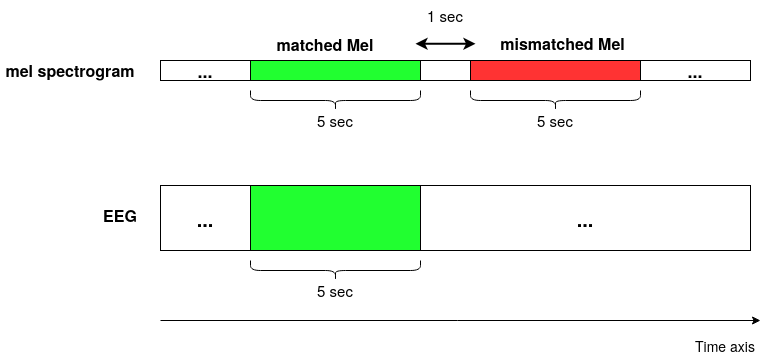
Decoding the speech signal that a person is listening to from the human brain via electroencephalography (EEG) can help us understand how our auditory system works. Linear models have been used to reconstruct the EEG from speech or vice versa. Recently, Artificial Neural Networks (ANNs) such as Convolutional Neural Network (CNN) and Long Short-Term Memory (LSTM) based architectures have outperformed linear models in modeling the relation between EEG and speech. Before attempting to use these models in real-world applications such as hearing tests or (second) language comprehension assessment we need to know what level of speech information is being utilized by these models. In this study, we aim to analyze the performance of an LSTM-based model using different levels of speech features. The task of the model is to determine which of two given speech segments is matched with the recorded EEG. We used low- and high-level speech features including: envelope, mel spectrogram, voice activity, phoneme identity, and word embedding. Our results suggest that the model exploits information about silences, intensity, and broad phonetic classes from the EEG. Furthermore, the mel spectrogram, which contains all this information, yields the highest accuracy (84%) among all the features.
翻译:解说一个人通过电子脑物理学(EEG)从人脑中听到的言语信号可以帮助我们理解我们的听觉系统是如何运作的。 线性模型已被用来从言语或反之亦然地重建EEG。 最近, 人造神经网络(ANNs) 等人造神经网络(ANNs) 和长短期内存(LSTM) 建筑等人工神经网络(ANNs) 在模拟EEG和言语之间的关系时, 优于线性模型。 在试图在现实世界应用中使用这些模型之前, 如听觉测试或( 第二) 语言理解性评估, 我们需要知道这些模型正在使用何种程度的言语信息。 在本研究中, 我们的目标是利用不同程度的言语特征分析基于LSTM的模型的性能。 该模型的任务是确定两个特定部分的性能与所记录的EEEG相匹配。 我们使用了低级和高级的语音特征, 包括: 信封、 线性光谱、 语音活动、 电话身份和单词嵌入词。 我们的结果表明, 模型利用了关于沉默、 密度、 最高性、 率、 和高级的EG。