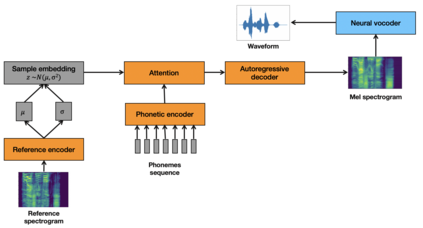
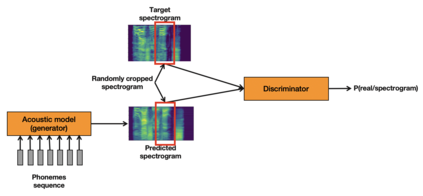
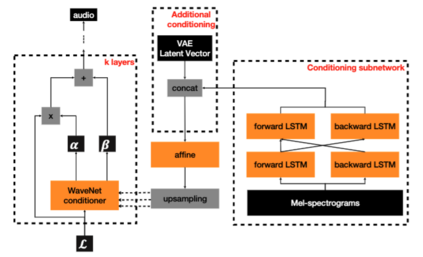
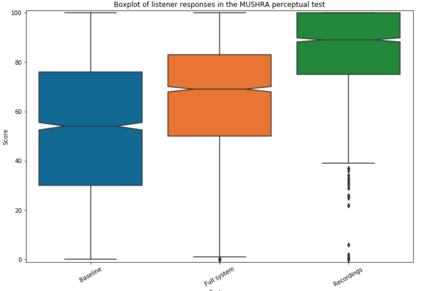
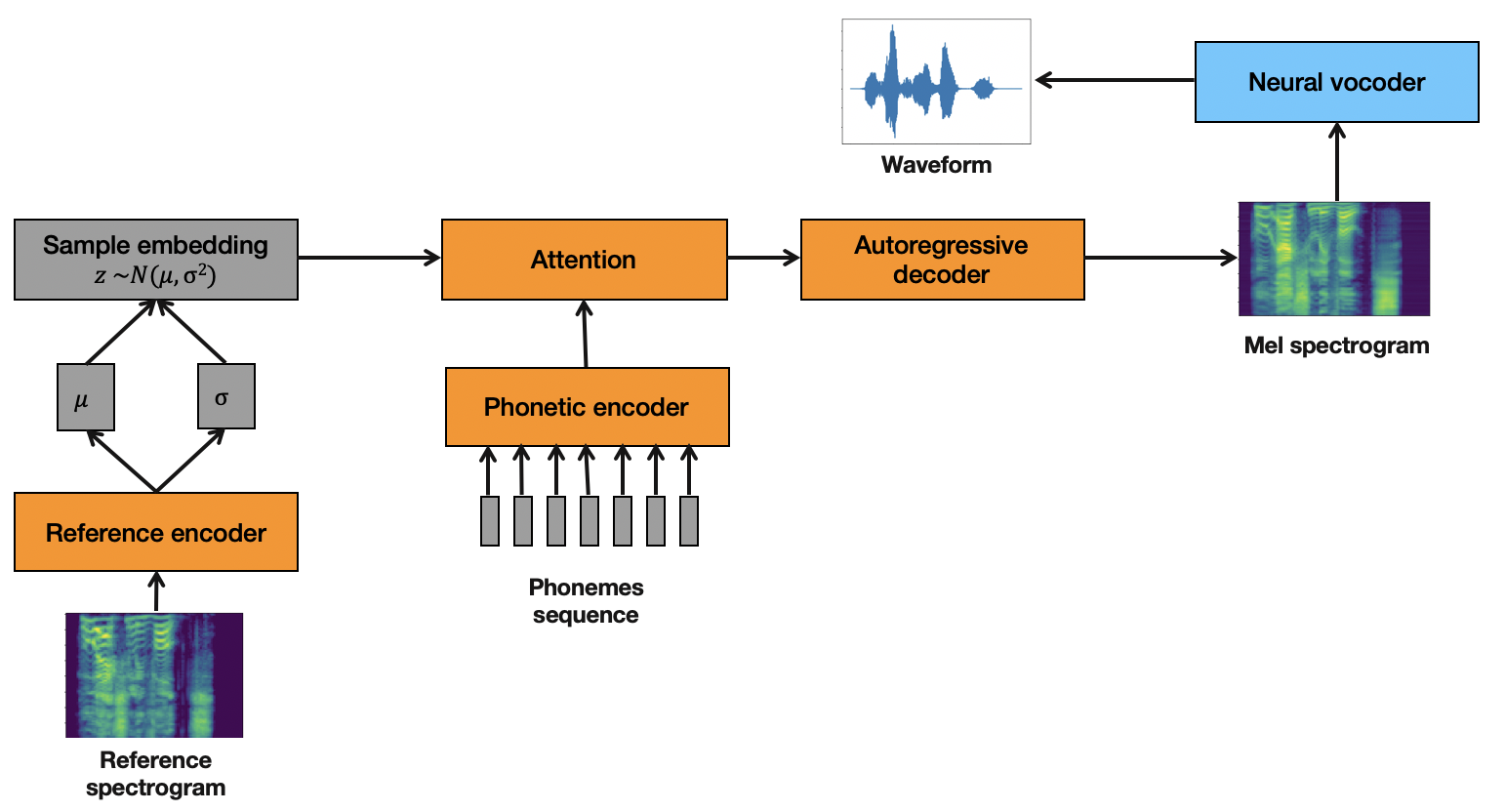
Artificial speech synthesis has made a great leap in terms of naturalness as recent Text-to-Speech (TTS) systems are capable of producing speech with similar quality to human recordings. However, not all speaking styles are easy to model: highly expressive voices are still challenging even to recent TTS architectures since there seems to be a trade-off between expressiveness in a generated audio and its signal quality. In this paper, we present a set of techniques that can be leveraged to enhance the signal quality of a highly-expressive voice without the use of additional data. The proposed techniques include: tuning the autoregressive loop's granularity during training; using Generative Adversarial Networks in acoustic modelling; and the use of Variational Auto-Encoders in both the acoustic model and the neural vocoder. We show that, when combined, these techniques greatly closed the gap in perceived naturalness between the baseline system and recordings by 39% in terms of MUSHRA scores for an expressive celebrity voice.
翻译:人工语音合成在自然性方面迈出了一大步,因为最近的文本到语音(TTS)系统能够生成与人类录音质量类似的语言。然而,并非所有的语音风格都容易建模:高表达式声音对于最近的TTS结构来说仍然具有挑战性,因为似乎在声音和信号质量的表达性之间存在着权衡。在本文中,我们展示了一套技术,这些技术可以在不使用额外数据的情况下用来提高高表达性声音的信号质量。拟议技术包括:在培训期间调整自动反射环的颗粒性;在音学建模中使用基因反转网络;在声学模型和神经电动中使用变动自动电解码器。我们表明,这些技术加在一起,大大缩小了基线系统和记录39%的MUSHRA分数之间的自然性差距。