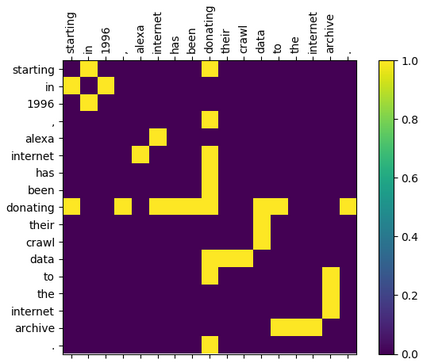
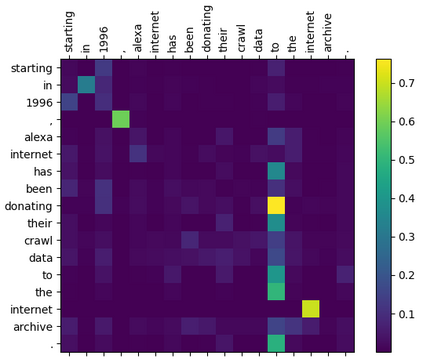
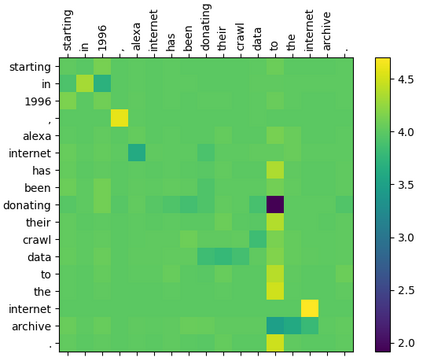
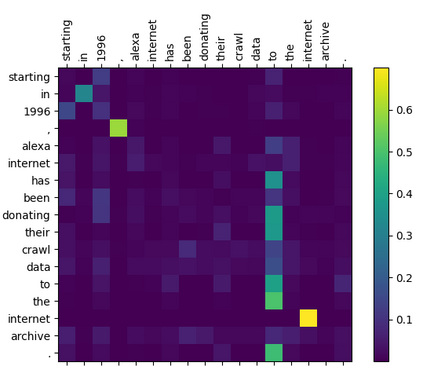
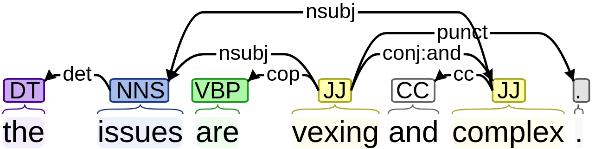
Within natural language processing tasks, linguistic knowledge can always serve an important role in assisting the model to learn excel representations and better guide the natural language generation. In this work, we develop a neural network based abstractive multi-document summarization (MDS) model which leverages dependency parsing to capture cross-positional dependencies and grammatical structures. More concretely, we process the dependency information into the linguistic-guided attention mechanism and further fuse it with the multi-head attention for better feature representation. With the help of linguistic signals, sentence-level relations can be correctly captured, thus improving MDS performance. Our model has two versions based on Flat-Transformer and Hierarchical Transformer respectively. Empirical studies on both versions demonstrate that this simple but effective method outperforms existing works on the benchmark dataset. Extensive analyses examine different settings and configurations of the proposed model which provide a good reference to the community.
翻译:在自然语言处理任务中,语言知识在协助模型学习优秀表现和更好地指导自然语言生成方面总是可以发挥重要作用。在这项工作中,我们开发了一个基于抽象的神经网络,基于抽象的多文档汇总模型,利用依赖性分析来捕捉跨位置依赖性和语法结构。更具体地说,我们将依赖性信息处理到语言引导关注机制中,并进一步将其与多头关注结合起来,以更好地体现特征。在语言信号的帮助下,可以正确捕捉到判决层关系,从而改进MDS的性能。我们的模型有两种版本,分别以Flat-Transexter和Hiarchical变异器为基础。关于这两种版本的经验研究表明,这一简单而有效的方法超越了基准数据集的现有工作。广泛分析了为社区提供良好参考的拟议模型的不同设置和配置。