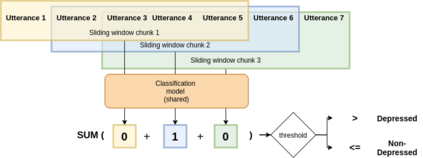
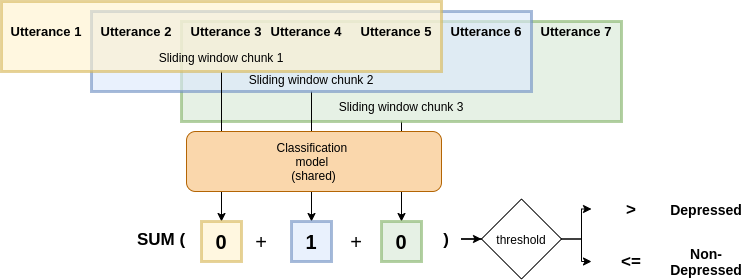
The high prevalence of depression in society has given rise to the need for new digital tools to assist in its early detection. To this end, existing research has mainly focused on detecting depression in the domain of social media, where there is a sufficient amount of data. However, with the rise of conversational agents like Siri or Alexa, the conversational domain is becoming more critical. Unfortunately, there is a lack of data in the conversational domain. We perform a study focusing on domain adaptation from social media to the conversational domain. Our approach mainly exploits the linguistic information preserved in the vector representation of text. We describe transfer learning techniques to classify users who suffer from early signs of depression with high recall. We achieve state-of-the-art results on a commonly used conversational dataset, and we highlight how the method can easily be used in conversational agents. We publicly release all source code.
翻译:社会抑郁症高发导致需要新的数字工具来帮助及早发现抑郁症,为此,现有研究主要侧重于在社会媒体领域发现抑郁症,因为那里有足够的数据,然而,随着Siri或Alexa等对话媒介的兴起,对话领域变得更加关键。不幸的是,在对话领域缺乏数据。我们开展了一项研究,重点是从社交媒体到对话领域的区域适应。我们的方法主要利用了文本矢量代表中保存的语言信息。我们描述了将早期抑郁症患者分类的转移学习技术,并记录了高记忆。我们在常用的谈话数据集上取得了最先进的结果,我们着重指出了该方法如何很容易用于对话媒介。我们公开发布所有源代码。