
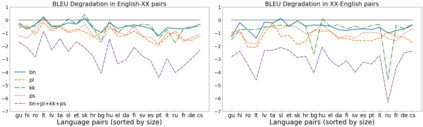
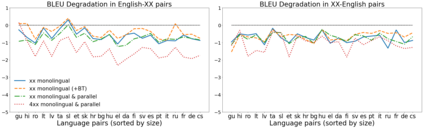
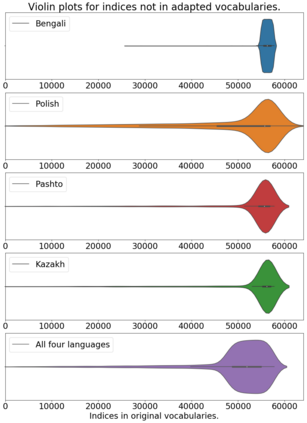
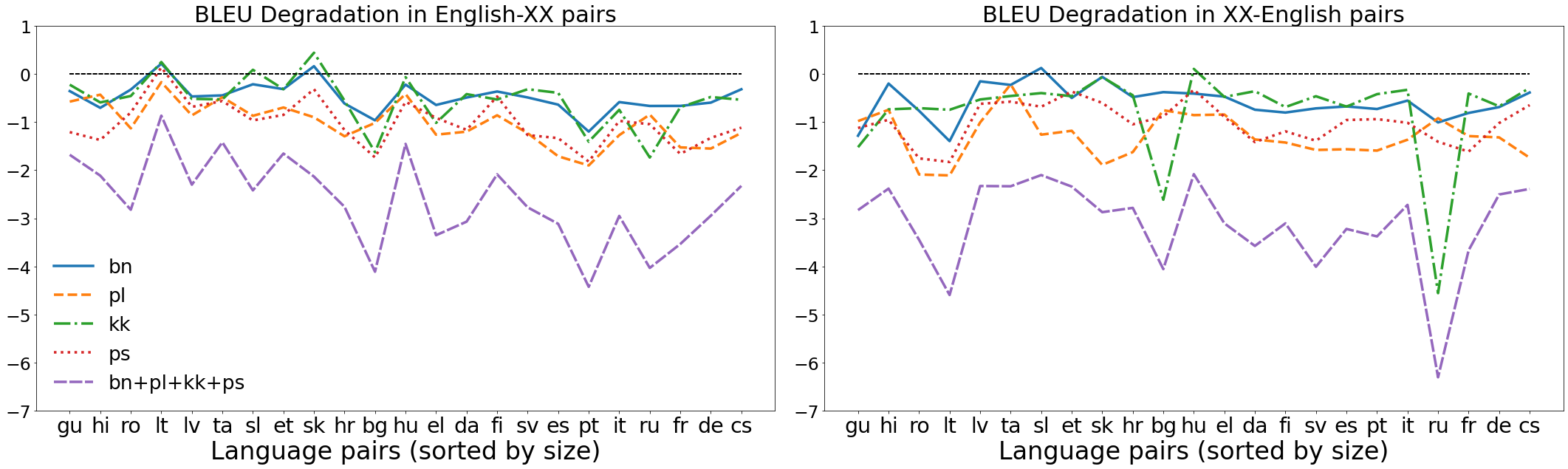
We propose a straightforward vocabulary adaptation scheme to extend the language capacity of multilingual machine translation models, paving the way towards efficient continual learning for multilingual machine translation. Our approach is suitable for large-scale datasets, applies to distant languages with unseen scripts, incurs only minor degradation on the translation performance for the original language pairs and provides competitive performance even in the case where we only possess monolingual data for the new languages.
翻译:我们提出一个直接的词汇适应计划,以扩大多语种机器翻译模式的语言能力,为高效地持续学习多语种机器翻译铺平道路。 我们的方法适合大规模数据集,适用于有看不见脚本的遥远语言,只造成原始语言对口翻译表现的轻微退化,并且提供竞争性的绩效,即使我们只掌握新语言的单一语言数据。
相关内容

让 iOS 8 和 OS X Yosemite 无缝切换的一个新特性。
> Apple products have always been designed to work together beautifully. But now they may really surprise you. With iOS 8 and OS X Yosemite, you’ll be able to do more wonderful things than ever before.
Source: Apple - iOS 8
Source: Apple - iOS 8
专知会员服务
54+阅读 · 2020年1月30日



相关VIP内容
专知会员服务
54+阅读 · 2020年1月30日
相关资讯
相关论文