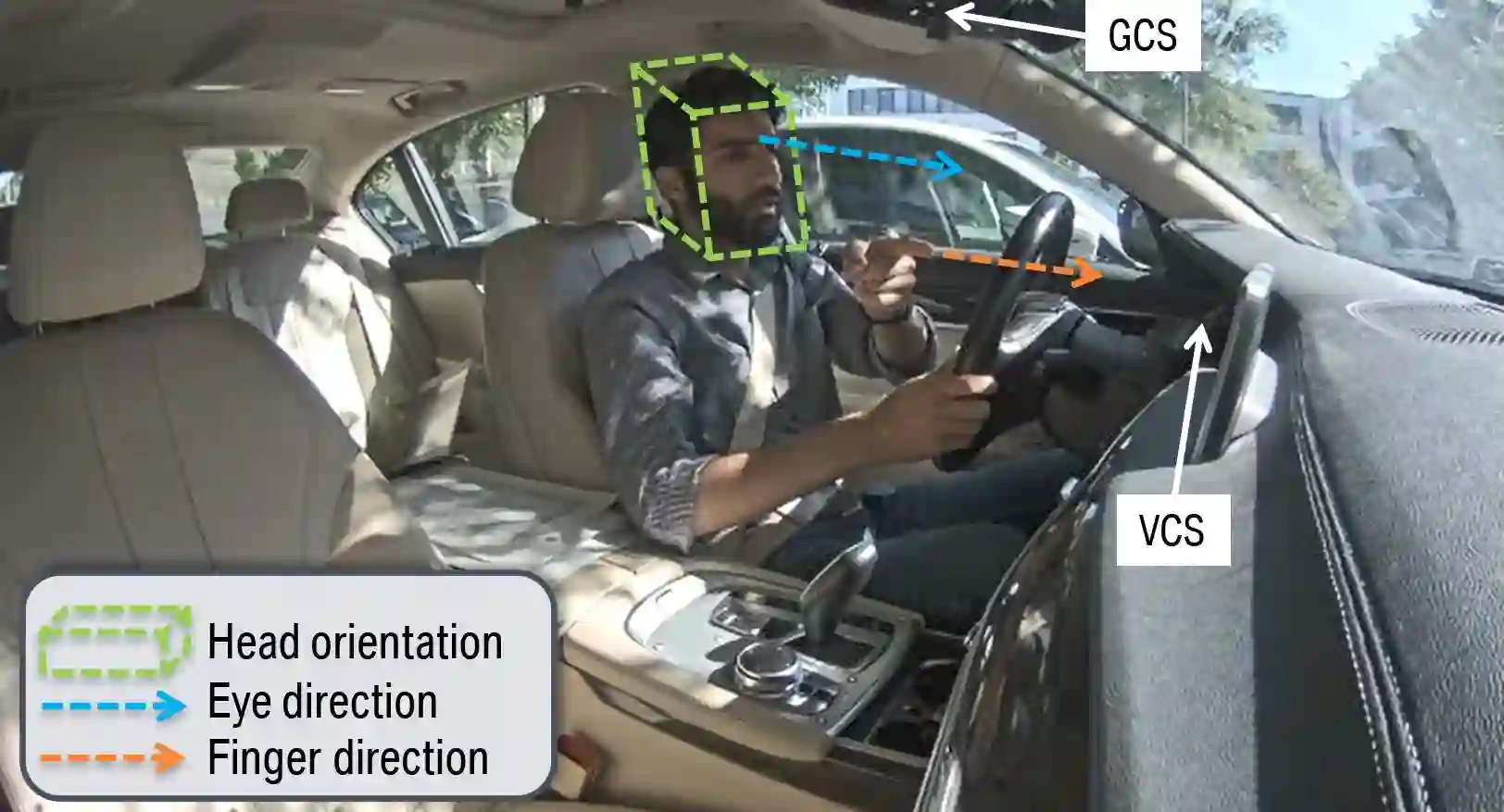
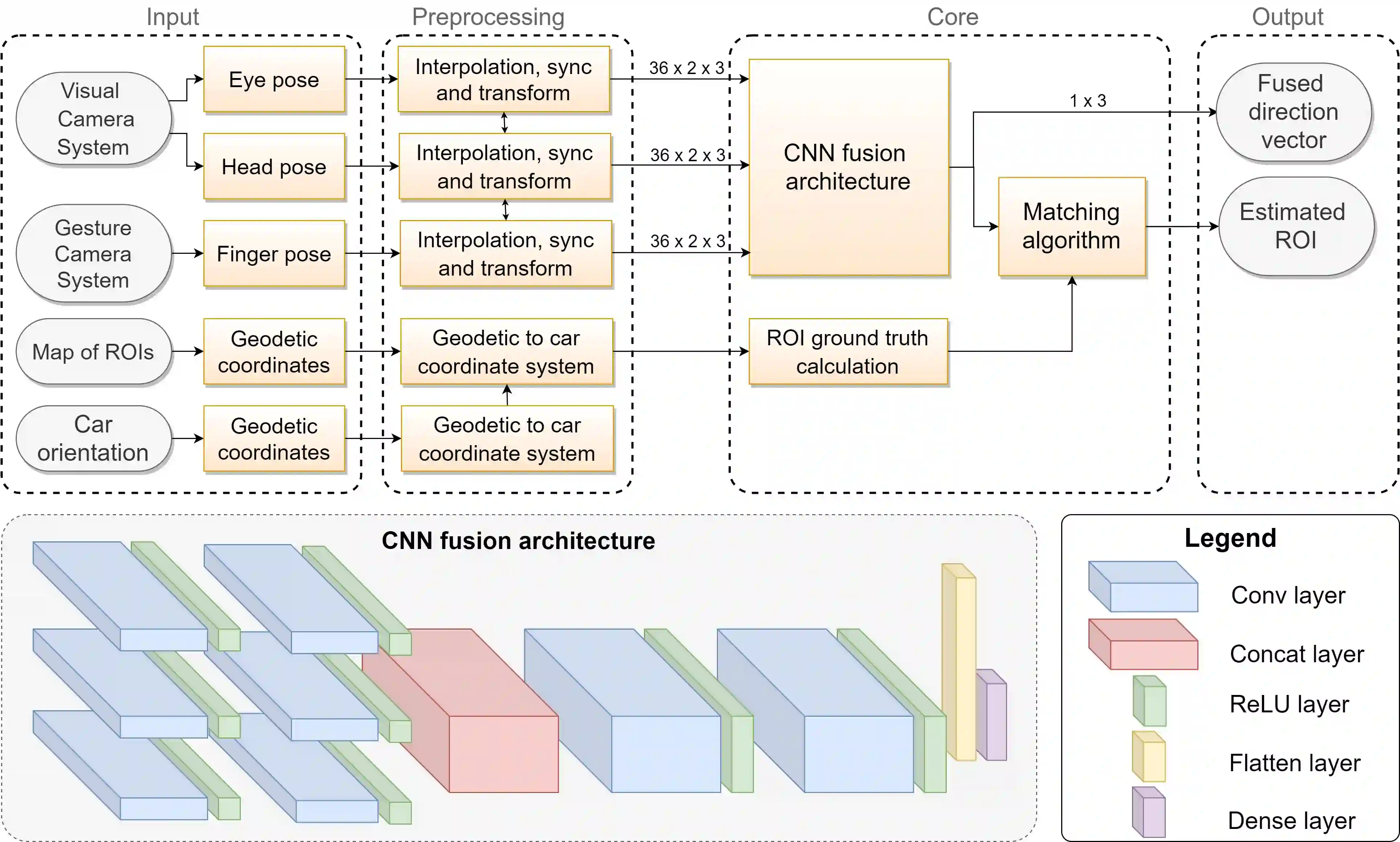
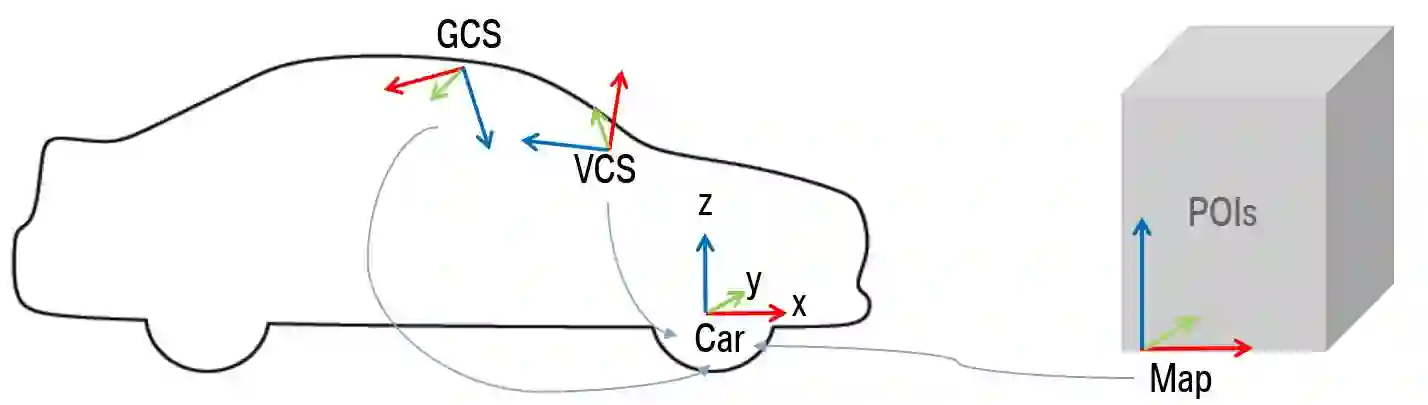
There is a growing interest in more intelligent natural user interaction with the car. Hand gestures and speech are already being applied for driver-car interaction. Moreover, multimodal approaches are also showing promise in the automotive industry. In this paper, we utilize deep learning for a multimodal fusion network for referencing objects outside the vehicle. We use features from gaze, head pose and finger pointing simultaneously to precisely predict the referenced objects in different car poses. We demonstrate the practical limitations of each modality when used for a natural form of referencing, specifically inside the car. As evident from our results, we overcome the modality specific limitations, to a large extent, by the addition of other modalities. This work highlights the importance of multimodal sensing, especially when moving towards natural user interaction. Furthermore, our user based analysis shows noteworthy differences in recognition of user behavior depending upon the vehicle pose.
翻译:人们越来越关心与汽车进行更聪明的自然用户互动。 手势和语言已经应用到驾驶汽车的互动中。 此外,多式方法也在汽车业中表现出希望。 在本文中,我们利用对多式聚合网络的深层次学习来查找车辆以外的物体。 我们使用目光、头部和手指的特征,同时指向准确预测不同车辆的被引用物体。 我们显示了在使用自然形式的参考时,特别是汽车内部,每种模式的实际局限性。从我们的结果中可以明显看出,我们在很大程度上通过添加其他模式克服了模式的具体局限性。 这项工作突出了多式联运的重要性,特别是在转向自然用户互动时。 此外,我们的用户分析显示,根据车辆的构成,在识别用户行为方面存在着显著的差异。