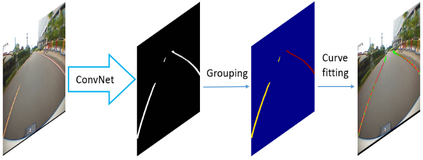
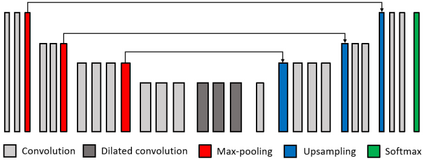
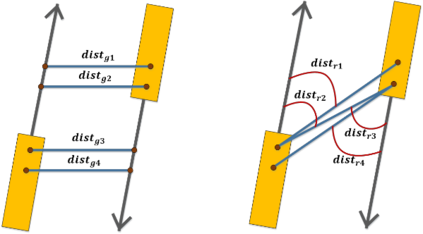
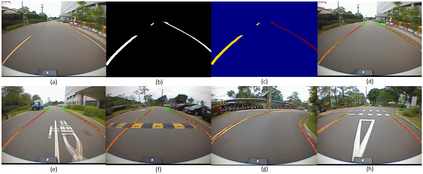
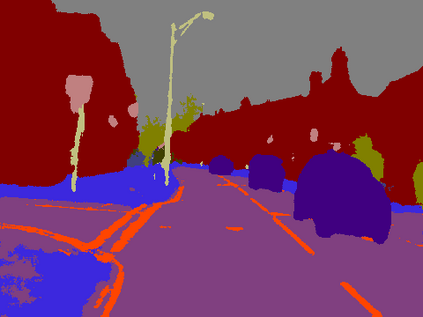
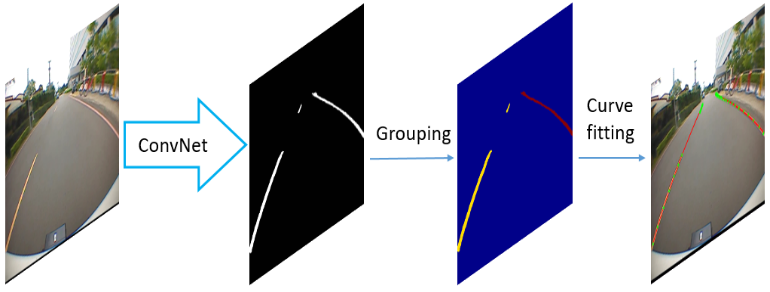
Lane mark detection is an important element in the road scene analysis for Advanced Driver Assistant System (ADAS). Limited by the onboard computing power, it is still a challenge to reduce system complexity and maintain high accuracy at the same time. In this paper, we propose a Lane Marking Detector (LMD) using a deep convolutional neural network to extract robust lane marking features. To improve its performance with a target of lower complexity, the dilated convolution is adopted. A shallower and thinner structure is designed to decrease the computational cost. Moreover, we also design post-processing algorithms to construct 3rd-order polynomial models to fit into the curved lanes. Our system shows promising results on the captured road scenes.
翻译:在高级司机助理系统(ADAS)的公路场景分析中,干线标记探测是发现高级司机助理系统(ADAS)的一个重要部分。由于机载计算能力的限制,降低系统复杂性并同时保持高精度仍是一项挑战。在本文中,我们提议使用一个深层的进化神经网络来提取稳健的车道标记特征,用一个低复杂度的目标来改进其性能,采用放大变速法。设计一个浅薄结构来降低计算成本。此外,我们还设计了后处理算法,以构建适合曲线道的三阶多动模型。我们的系统在所捕捉到的道路场景上显示了有希望的结果。