
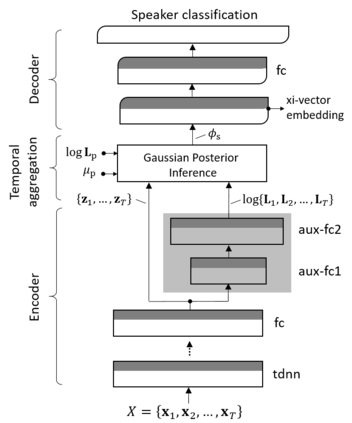
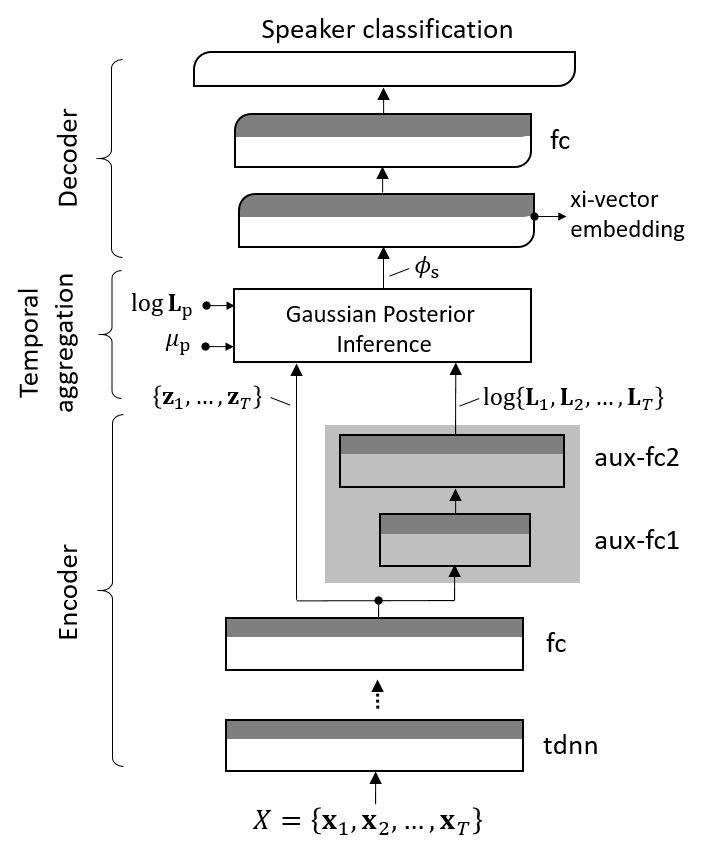
We present a Bayesian formulation for deep speaker embedding, wherein the xi-vector is the Bayesian counterpart of the x-vector, taking into account the uncertainty estimate. On the technology front, we offer a simple and straightforward extension to the now widely used x-vector. It consists of an auxiliary neural net predicting the frame-wise uncertainty of the input sequence. We show that the proposed extension leads to substantial improvement across all operating points, with a significant reduction in error rates and detection cost. On the theoretical front, our proposal integrates the Bayesian formulation of linear Gaussian model to speaker-embedding neural networks via the pooling layer. In one sense, our proposal integrates the Bayesian formulation of the i-vector to that of the x-vector. Hence, we refer to the embedding as the xi-vector, which is pronounced as /zai/ vector. Experimental results on the SITW evaluation set show a consistent improvement of over 17.5% in equal-error-rate and 10.9% in minimum detection cost.
翻译:我们提出了一个用于深层扩音器嵌入的贝叶斯配方,其中x-矢量器的x-矢量器为Bayesian配方,同时考虑到不确定性的估计。在技术方面,我们向目前广泛使用的 x-矢量器提供简单和直截了当的扩展。它包括一个辅助神经网,预测输入序列的框架不确定性。我们表明,拟议的扩展导致所有操作点的大幅改进,差错率和检测成本显著下降。在理论方面,我们的提案将Bayesian线性高斯模型通过集合层与扩音器组成神经网络相结合。从某种意义上讲,我们的提案将i-矢量器的贝耶斯配方与x-矢量器的配方结合起来。因此,我们把嵌入称为x-矢量器,这被称为/zai/矢量器。SITW评价组的实验结果显示,平等er-or-率和最低检测成本的超过17.5%。
相关内容

- Today (iOS and OS X): widgets for the Today view of Notification Center
- Share (iOS and OS X): post content to web services or share content with others
- Actions (iOS and OS X): app extensions to view or manipulate inside another app
- Photo Editing (iOS): edit a photo or video in Apple's Photos app with extensions from a third-party apps
- Finder Sync (OS X): remote file storage in the Finder with support for Finder content annotation
- Storage Provider (iOS): an interface between files inside an app and other apps on a user's device
- Custom Keyboard (iOS): system-wide alternative keyboards
Source: iOS 8 Extensions: Apple’s Plan for a Powerful App Ecosystem


