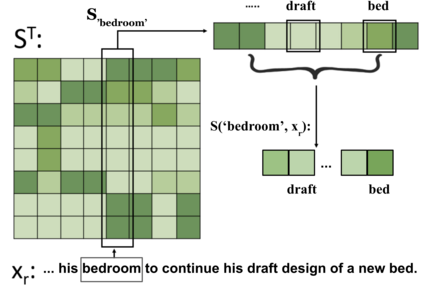
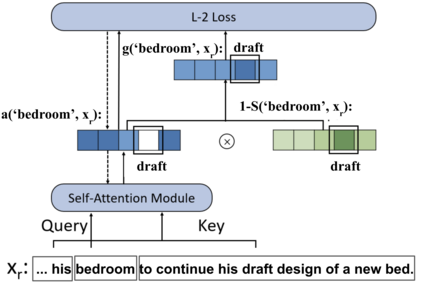
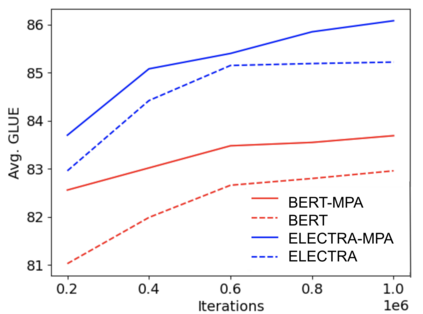
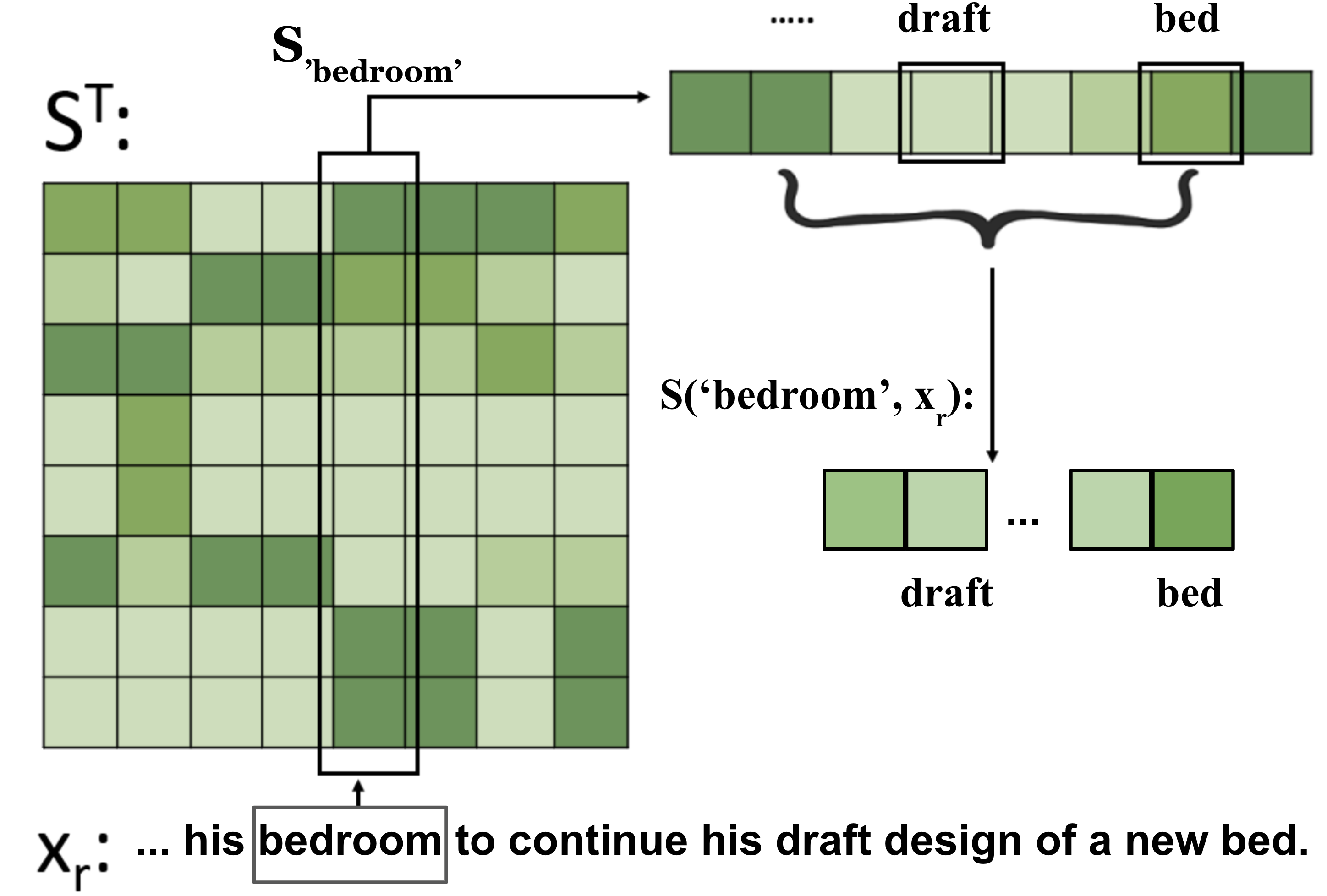
Fitting complex patterns in the training data, such as reasoning and commonsense, is a key challenge for language pre-training. According to recent studies and our empirical observations, one possible reason is that some easy-to-fit patterns in the training data, such as frequently co-occurring word combinations, dominate and harm pre-training, making it hard for the model to fit more complex information. We argue that mis-predictions can help locate such dominating patterns that harm language understanding. When a mis-prediction occurs, there should be frequently co-occurring patterns with the mis-predicted word fitted by the model that lead to the mis-prediction. If we can add regularization to train the model to rely less on such dominating patterns when a mis-prediction occurs and focus more on the rest more subtle patterns, more information can be efficiently fitted at pre-training. Following this motivation, we propose a new language pre-training method, Mis-Predictions as Harm Alerts (MPA). In MPA, when a mis-prediction occurs during pre-training, we use its co-occurrence information to guide several heads of the self-attention modules. Some self-attention heads in the Transformer modules are optimized to assign lower attention weights to the words in the input sentence that frequently co-occur with the mis-prediction while assigning higher weights to the other words. By doing so, the Transformer model is trained to rely less on the dominating frequently co-occurring patterns with mis-predictions while focus more on the rest more complex information when mis-predictions occur. Our experiments show that MPA expedites the pre-training of BERT and ELECTRA and improves their performances on downstream tasks.
翻译:适应培训数据中的复杂模式,如推理和常识,是语言培训前的一个关键挑战。根据最近的研究和我们的经验观察,一个可能的原因是培训数据中一些容易适应的模式,例如经常同时出现的单词组合、支配和伤害预培训,使得模型很难适应更复杂的信息。我们争辩说,错误预测有助于找到这种妨碍语言理解的主导模式。当发生错误预测时,应该经常出现与错误预测的词一起的错误预测模式相联的模式,从而导致错误预测。根据最近的研究和我们的经验观察,一个可能的原因是,如果在培训数据中能够增加一些容易适应的模式,从而在出现错误预测时,可以减少对模式的偏差模式的偏差,并更多地关注其余的微妙模式,使更多的信息能够有效地适应培训前的复杂信息。根据这一动机,我们提出了一种新的语言预培训方法,即错误预测作为危害警报。在培训前发生错误预测时,我们使用更偏差的偏差的偏差模式,从而导致错误预测的偏差模式导致错误预测的周期模式。如果我们能够增加正规化模式来训练模型,那么,那么,我们就会使用它用来规范模式来训练模型来训练模型来减少模式,从而指导模型,而经常调整模型的偏差的偏差,同时将部分的偏差的偏差的偏差,同时将部分的偏差的偏差的偏差信息,同时将调整我们会将一些对数的轨道的偏差的偏差的偏差的偏差的偏差,同时将显示,同时将显示,同时让数的偏差的偏差的偏差的偏差的偏差的偏差的偏差的偏差的偏差的偏差的偏差的偏差的偏差的偏差会将部分会将令的偏差的偏差的偏差的偏差的偏差的偏差的偏差会将令的偏差会将令将令将令将令将令将令将令将令会将调整会让,同时将令将令到分值将令将令到分值调整调整调整调整到分值将令将令将令将令到最重值将令到最重,同时将令的偏差的偏差调整值调整值调整值调整值调整值将令 。