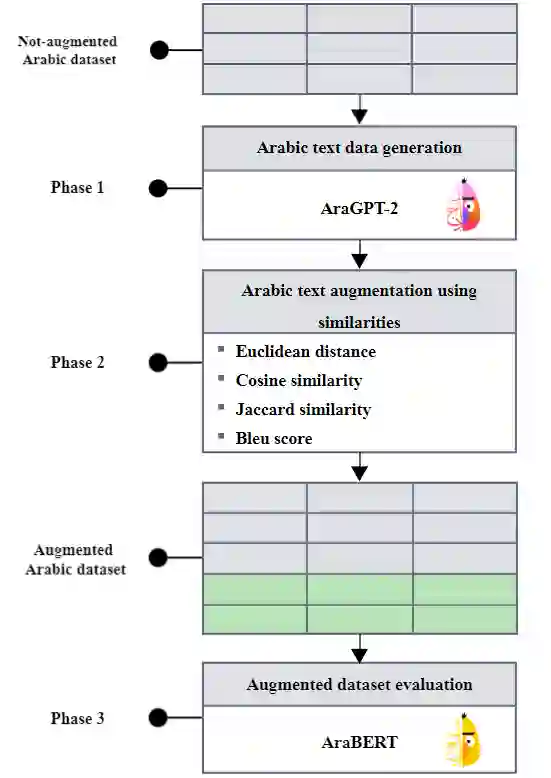
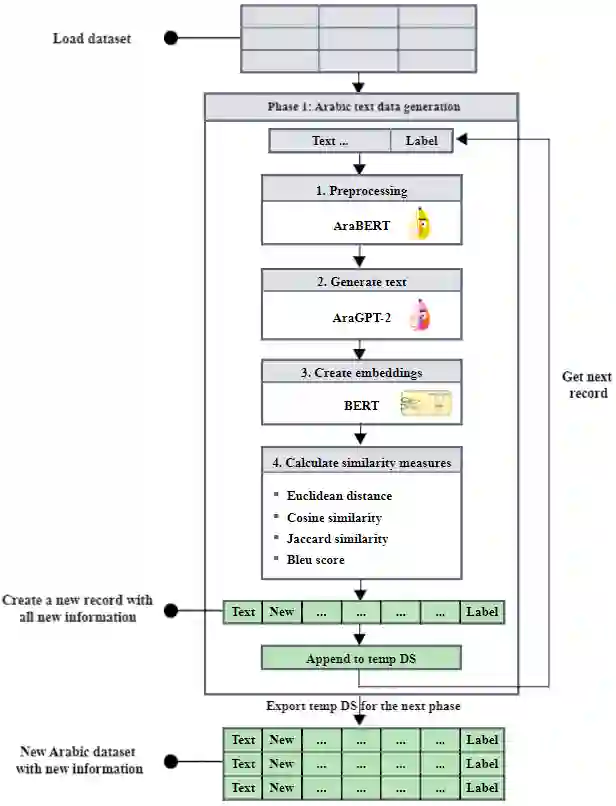
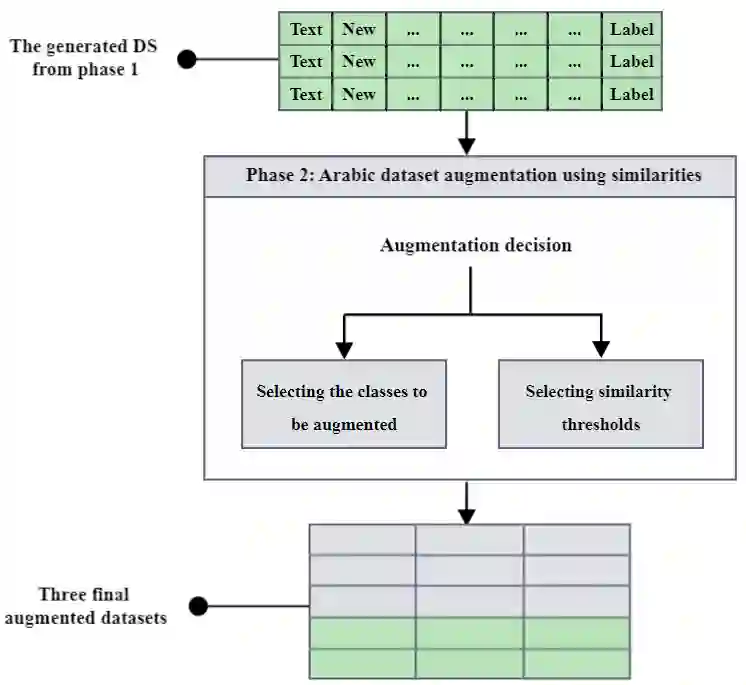
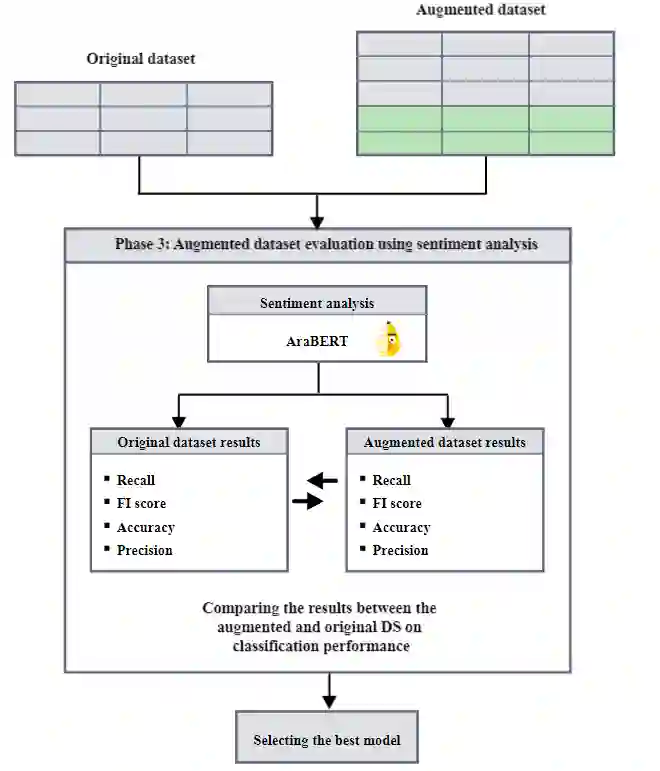
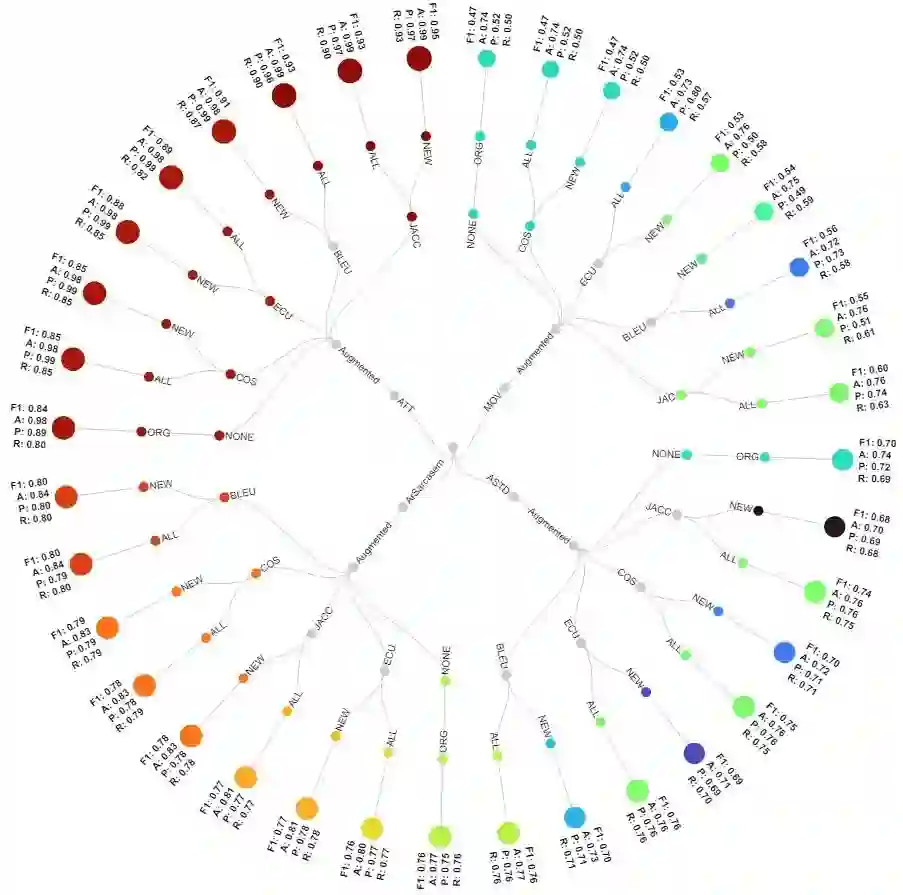
Learning models are highly dependent on data to work effectively, and they give a better performance upon training on big datasets. Massive research exists in the literature to address the dataset adequacy issue. One promising approach for solving dataset adequacy issues is the data augmentation (DA) approach. In DA, the amount of training data instances is increased by making different transformations on the available data instances to generate new correct and representative data instances. DA increases the dataset size and its variability, which enhances the model performance and its prediction accuracy. DA also solves the class imbalance problem in the classification learning techniques. Few studies have recently considered DA in the Arabic language. These studies rely on traditional augmentation approaches, such as paraphrasing by using rules or noising-based techniques. In this paper, we propose a new Arabic DA method that employs the recent powerful modeling technique, namely the AraGPT-2, for the augmentation process. The generated sentences are evaluated in terms of context, semantics, diversity, and novelty using the Euclidean, cosine, Jaccard, and BLEU distances. Finally, the AraBERT transformer is used on sentiment classification tasks to evaluate the classification performance of the augmented Arabic dataset. The experiments were conducted on four sentiment Arabic datasets, namely AraSarcasm, ASTD, ATT, and MOVIE. The selected datasets vary in size, label number, and unbalanced classes. The results show that the proposed methodology enhanced the Arabic sentiment text classification on all datasets with an increase in F1 score by 4% in AraSarcasm, 6% in ASTD, 9% in ATT, and 13% in MOVIE.
翻译:学习模型高度依赖数据才能有效工作,并且它们通过大数据集培训产生更好的业绩。文献中存在大量研究,以解决数据集是否充分的问题。解决数据集是否充分问题的一种有希望的方法是数据增强(DA)方法。在数据增强(DA)中,培训数据实例的数量通过对现有数据实例进行不同的转换而增加,以生成新的正确和有代表性的数据实例。DA增加了数据集大小及其变异性,这提高了模型的性能和预测准确性。DA还解决了分类学习技术中的分类不平衡问题。最近很少有研究考虑阿拉伯语中的DA。这些研究依靠传统的增强方法,例如使用规则或基于调频技术进行parphrasing。在本文中,我们提出了一种新的阿拉伯语DADA方法,即用于增强的AraGPT-2,用于增强数据排序的背景、语系、多样性和新版本,使用EUclidicial1、Cociard和BLEU的距离。最后,AraBER变异性变式变式变式的AAS方法,用于在AAS AS 4级中评估数据变异性数据排序,即ADS AS AS AS 的缩方法,在ADS 4 AS 4 AS AS 中,在ADisl化中,在评估数据变式变式变式的计算中,在分析中,在ADS AS AS AS AS AS 数据变式中用所有数据变式数据变式方法中,在A AS AS AS AS AS 数据变式的计算中,在评估了数据变式数据变式数据变式数据变式方法中,在ADV。