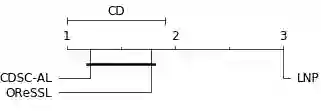
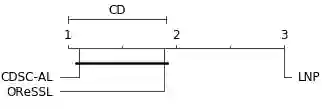
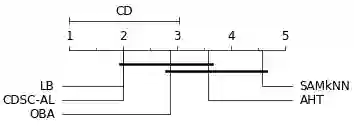
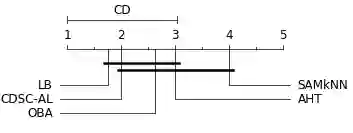
The non-stationary nature of data streams strongly challenges traditional machine learning techniques. Although some solutions have been proposed to extend traditional machine learning techniques for handling data streams, these approaches either require an initial label set or rely on specialized design parameters. The overlap among classes and the labeling of data streams constitute other major challenges for classifying data streams. In this paper, we proposed a clustering-based data stream classification framework to handle non-stationary data streams without utilizing an initial label set. A density-based stream clustering procedure is used to capture novel concepts with a dynamic threshold and an effective active label querying strategy is introduced to continuously learn the new concepts from the data streams. The sub-cluster structure of each cluster is explored to handle the overlap among classes. Experimental results and quantitative comparison studies reveal that the proposed method provides statistically better or comparable performance than the existing methods.
翻译:数据流的非静止性质对传统的机器学习技术提出了强烈的挑战。虽然已经提出一些解决办法,以扩大处理数据流的传统机器学习技术,但这些办法要么需要初步的标签,要么依靠专门的设计参数。数据流的分类重叠和标签是数据流分类的其他重大挑战。在本文件中,我们提议了一个基于集群的数据流分类框架,以处理非静止数据流,而不用最初的标签集。一个基于密度的流群集程序用来捕捉具有动态阈值的新概念,并采用有效的积极标签查询战略,不断从数据流中学习新概念。每个组群的分组结构是用来处理分类重叠的。实验结果和定量比较研究表明,拟议的方法比现有方法在统计上更好或更具有可比性。