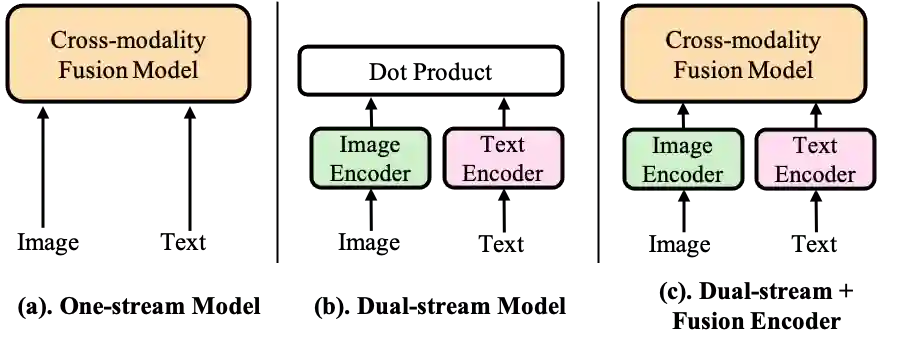
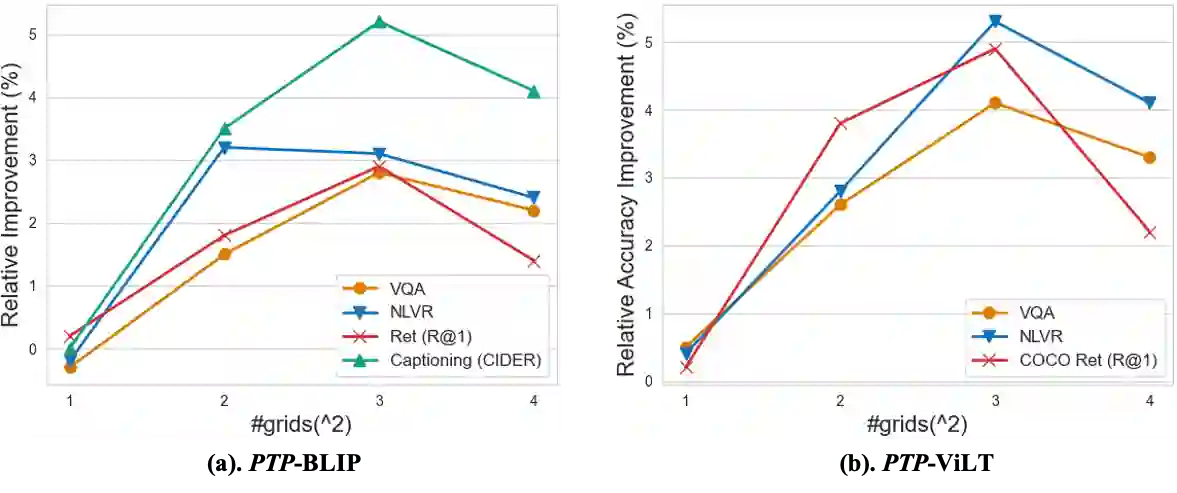
Vision-Language Pre-Training (VLP) has shown promising capabilities to align image and text pairs, facilitating a broad variety of cross-modal learning tasks. However, we observe that VLP models often lack the visual grounding/localization capability which is critical for many downstream tasks such as visual reasoning. In this work, we propose a novel Position-guided Text Prompt (PTP) paradigm to enhance the visual grounding ability of cross-modal models trained with VLP. Specifically, in the VLP phase, PTP divides the image into $N\times N$ blocks, and identifies the objects in each block through the widely used object detector in VLP. It then reformulates the visual grounding task into a fill-in-the-blank problem given a PTP by encouraging the model to predict the objects in the given blocks or regress the blocks of a given object, e.g. filling `P" or ``O" in aPTP ``The block P has a O". This mechanism improves the visual grounding capability of VLP models and thus helps them better handle various downstream tasks. By introducing PTP into several state-of-the-art VLP frameworks, we observe consistently significant improvements across representative cross-modal learning model architectures and several benchmarks, e.g. zero-shot Flickr30K Retrieval (+4.8 in average recall@1) for ViLT \cite{vilt} baseline, and COCO Captioning (+5.3 in CIDEr) for SOTA BLIP \cite{blip} baseline. Moreover, PTP achieves comparable results with object-detector based methods, and much faster inference speed since PTP discards its object detector for inference while the later cannot. Our code and pre-trained weight will be released at \url{https://github.com/sail-sg/ptp}.
翻译:预培训前的视觉- Language (VLP) 展示了有希望的能力, 将图像和文本配对相匹配, 便利了多种跨模式的学习任务。 然而, 我们观察到, VLP 模型往往缺乏视觉地面定位/ 本地化能力, 这对于许多下游任务( 如视觉推理等) 至关重要。 在这项工作中, 我们提出一个新的定位引导文本提示( PTP) 模式, 以提高与 VLP 培训的跨模式的视觉地面化能力。 具体来说, 在 VLP 阶段, PTP 将图像分割成$N\time N$, 并通过 VLP 广泛使用的对象探测器确定每个街区中的对象。 然后将视觉地面化任务重新配置成一个填充版式地面化能力, 因为 PTP 鼓励模型预测特定区块中的物体, 或将某个对象的回收块, 例如, 在 aPTP 中填“ P” 或“ litude” comer 代码中, 将 O' 。 这个机制改进了 的 e- e- e- PLPTP 基线模型的视觉定位/ true- ta deal la la lax lax lader lax lax lax s s s s s s s s s s s s s