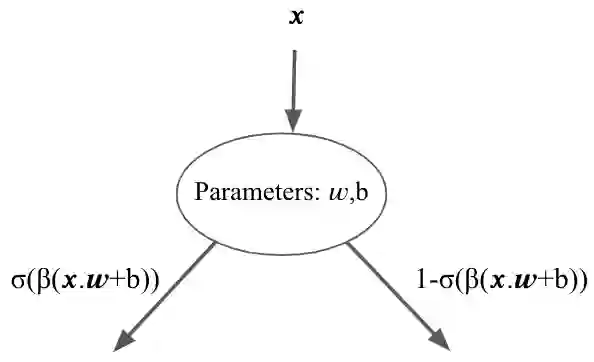
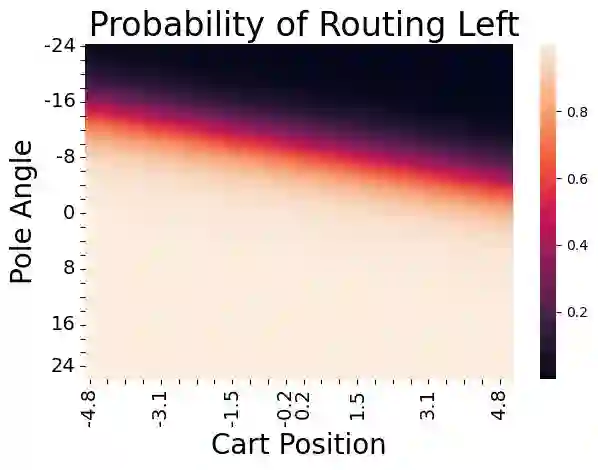
There is an increasing interest in learning reward functions that model human intent and human preferences. However, many frameworks use blackbox learning methods that, while expressive, are difficult to interpret. We propose and evaluate a novel approach for learning expressive and interpretable reward functions from preferences using Differentiable Decision Trees (DDTs). Our experiments across several domains, including Cartpole, Visual Gridworld environments and Atari games, provide evidence that that the tree structure of our learned reward function is useful in determining the extent to which the reward function is aligned with human preferences. We experimentally demonstrate that using reward DDTs results in competitive performance when compared with larger capacity deep neural network reward functions. We also observe that the choice between soft and hard (argmax) output of reward DDT reveals a tension between wanting highly shaped rewards to ensure good RL performance, while also wanting simple, non-shaped rewards to afford interpretability.
翻译:暂无翻译