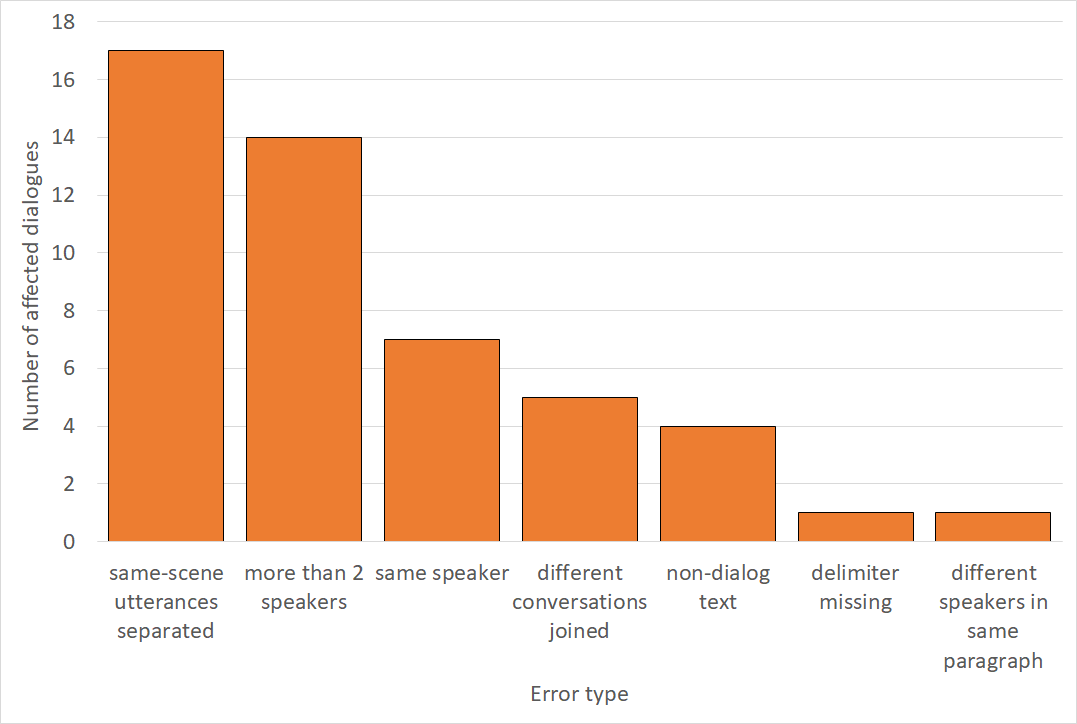
Large datasets are essential for neural modeling of many NLP tasks. Current publicly available open-domain dialogue datasets offer a trade-off between quality (e.g., DailyDialog) and size (e.g., Opensubtitles). We narrow this gap by building a high-quality dataset of 14.8M utterances in English, and smaller datasets in German, Dutch, Spanish, Portuguese, Italian, and Hungarian. We extract and process dialogues from public-domain books made available by Project Gutenberg. We describe our dialogue extraction pipeline, analyze the effects of the various heuristics used, and present an error analysis of extracted dialogues. Finally, we conduct experiments showing that better response quality can be achieved in zero-shot and finetuning settings by training on our data than on the larger but much noisier Opensubtitles dataset. Our open-source pipeline (https://github.com/ricsinaruto/gutenberg-dialog) can be extended to further languages with little additional effort. Researchers can also build their versions of existing datasets by adjusting various trade-off parameters. We also built a web demo for interacting with our models: https://ricsinaruto.github.io/chatbot.html.
翻译:大型数据集对于许多NLP任务的神经建模至关重要。 目前公开提供的开放域对话数据集在质量(例如DailyDialog)和大小(例如OpenSubititits)之间提供了权衡。 我们缩小了这一差距,建立了高质量的英文数据集14.8M,德国、荷兰、西班牙、葡萄牙、意大利和匈牙利的数据集较小。我们从Gutenberg项目提供的公共-Domain书籍中提取和处理对话。我们描述了我们的对话提取管道,分析了所使用的各种螺旋体的效果,并对提取的对话进行了错误分析。最后,我们进行了实验,表明通过培训我们的数据,而不是在更大但多为新颖的Opensubitallaties数据集方面,可以实现更好的反应质量。我们的开放源管道(https://github.com/ricsinaruto/gutenberg-dialog)可以扩大到更多的语言。研究人员还可以通过调整我们现有的数据设置的模型/数字模型来进行升级。我们还可以通过调整各种贸易/数字互动的模型来建立自己的数据库。