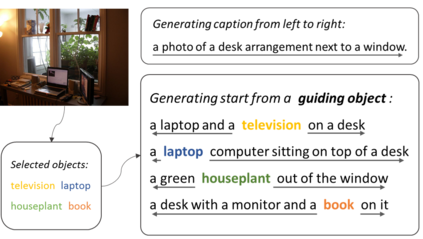
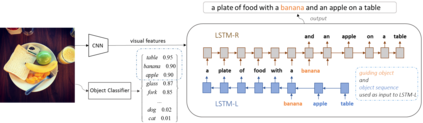
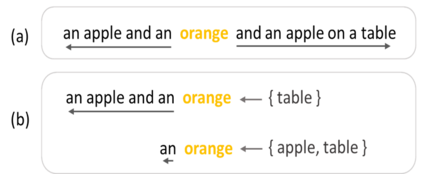
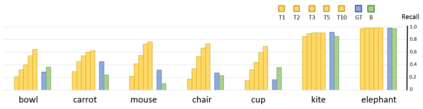
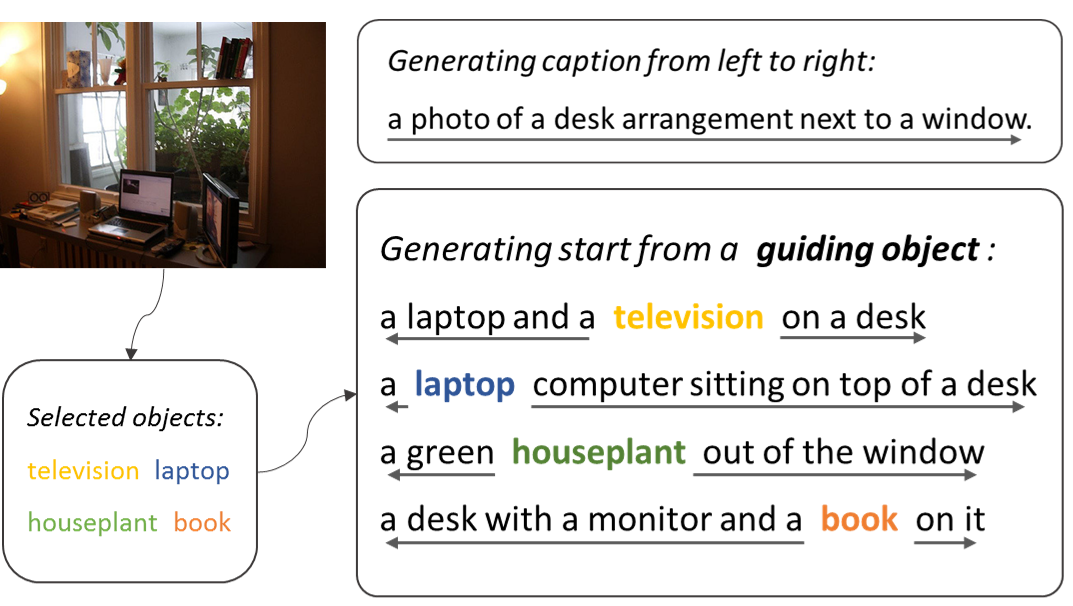
Although existing image caption models can produce promising results using recurrent neural networks (RNNs), it is difficult to guarantee that an object we care about is contained in generated descriptions, for example in the case that the object is inconspicuous in the image. Problems become even harder when these objects did not appear in training stage. In this paper, we propose a novel approach for generating image captions with guiding objects (CGO). The CGO constrains the model to involve a human-concerned object when the object is in the image. CGO ensures that the object is in the generated description while maintaining fluency. Instead of generating the sequence from left to right, we start the description with a selected object and generate other parts of the sequence based on this object. To achieve this, we design a novel framework combining two LSTMs in opposite directions. We demonstrate the characteristics of our method on MSCOCO where we generate descriptions for each detected object in the images. With CGO, we can extend the ability of description to the objects being neglected in image caption labels and provide a set of more comprehensive and diverse descriptions for an image. CGO shows advantages when applied to the task of describing novel objects. We show experimental results on both MSCOCO and ImageNet datasets. Evaluations show that our method outperforms the state-of-the-art models in the task with average F1 75.8, leading to better descriptions in terms of both content accuracy and fluency.
翻译:虽然现有的图像说明模型能够利用反复的神经网络产生有希望的结果,但很难保证我们所关心的物体包含在生成的描述中,例如,如果该物体在图像中不显眼,问题就更加严重。当这些物体没有出现在培训阶段时,问题就更加严重。在本文件中,我们建议采用一种新颖的方法来制作带有指导物体的图像说明(CGO)。在图像中,CGO将模型限制于涉及人类关注的对象。CGO确保该物体在生成的描述中包含该物体,同时保持流畅。我们不是从左向右生成序列,而是用一个选定的对象开始描述,并生成基于该物体的序列的其他部分。为了实现这一点,我们设计了一个新的框架,将两个LSTMMs放在相反的训练阶段。我们展示了我们在图像中每个被检测对象的描述方法的特性。与CGOO一道,我们可以将描述能力扩大到在图像说明标签中被忽略的对象,并为图像提供一套更全面、更多样化的描述。COO在应用一个精细的精确度模型时,在描述新物体的实验性任务中显示我们的平均格式任务中,我们展示了模型的实验性任务。