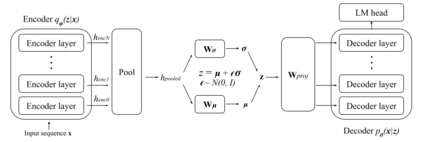
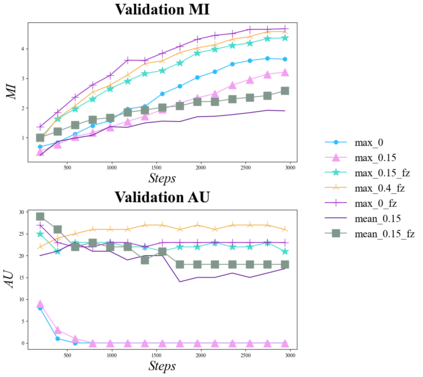
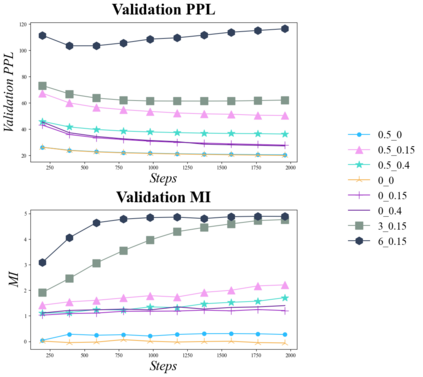
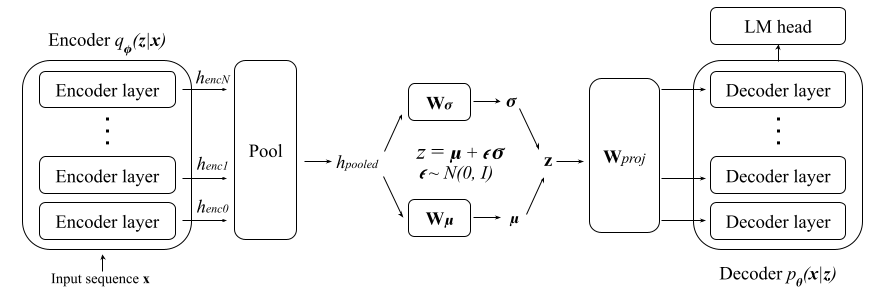
Text variational autoencoders (VAEs) are notorious for posterior collapse, a phenomenon where the model's decoder learns to ignore signals from the encoder. Because posterior collapse is known to be exacerbated by expressive decoders, Transformers have seen limited adoption as components of text VAEs. Existing studies that incorporate Transformers into text VAEs (Li et al., 2020; Fang et al., 2021) mitigate posterior collapse using massive pretraining, a technique unavailable to most of the research community without extensive computing resources. We present a simple two-phase training scheme to convert a sequence-to-sequence Transformer into a VAE with just finetuning. The resulting language model is competitive with massively pretrained Transformer-based VAEs in some internal metrics while falling short on others. To facilitate training we comprehensively explore the impact of common posterior collapse alleviation techniques in the literature. We release our code for reproducability.
翻译:文本变换自动编码器(VAEs)因事后崩溃而臭名昭著, 这是一种模型的解码器学会忽略编码器信号的现象。 因为已知后代解码器的表达式解码器会加剧后代崩溃, 变换器认为作为文本变换自动编码器组成部分的采用有限。 将变换器纳入文本变换器的现有研究(Li等人, 2020年; Fang 等人, 2021年)利用大规模预培训来减轻后代崩溃, 这是一种多数研究界没有广泛计算资源的技术。 我们提出了一个简单的两阶段培训计划, 将序列到序列变换器转换成VAE, 并进行简单的微调。 由此产生的语言模式具有竞争力, 与一些内部指标中大量预先训练的变换码器VAEs, 同时落后于其他指标。 为了便利培训, 我们全面探索文献中常见的后代崩溃法的影响。 我们发布了可复制的代码 。