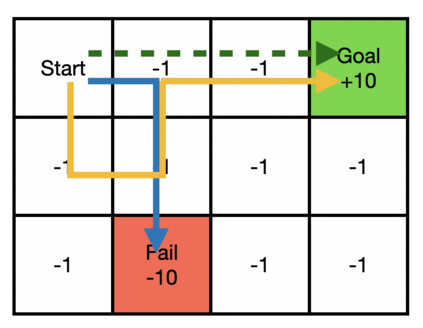
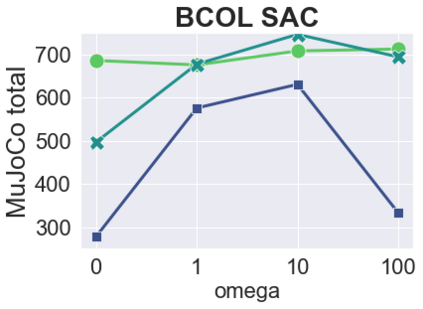
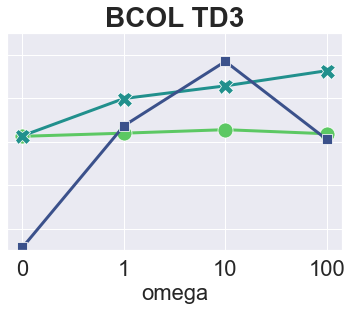
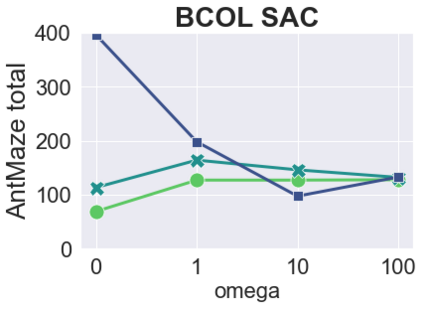
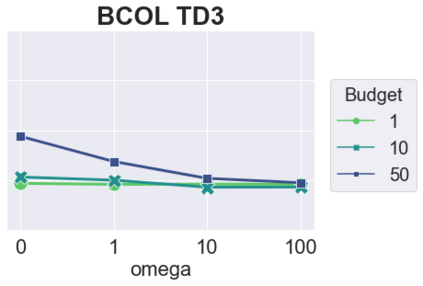
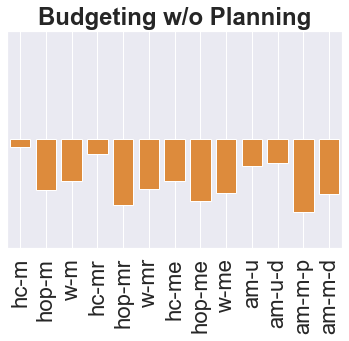
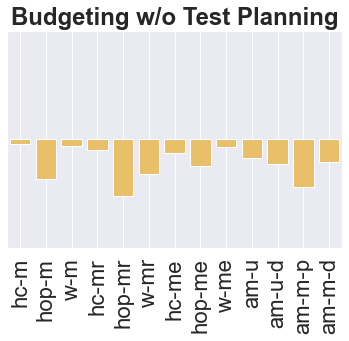
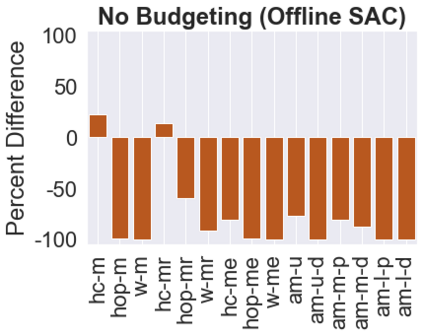
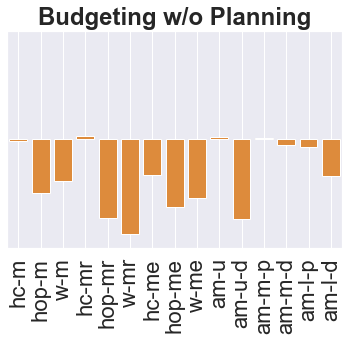
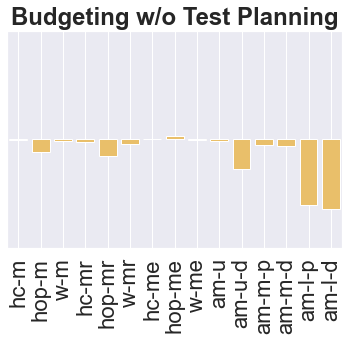
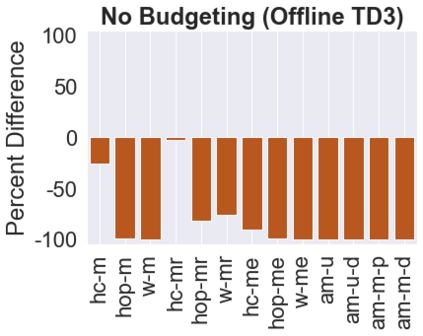
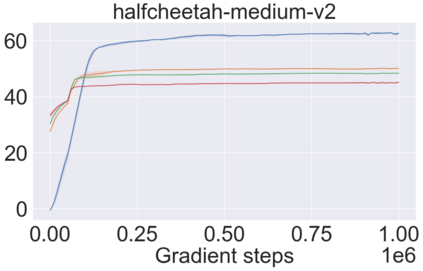
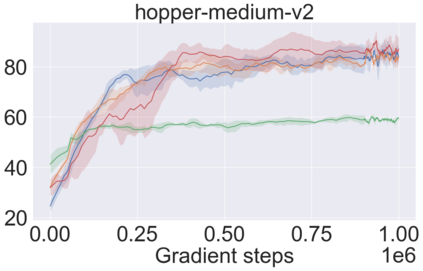
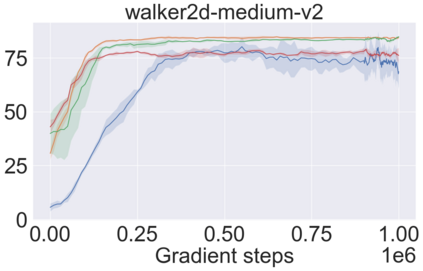
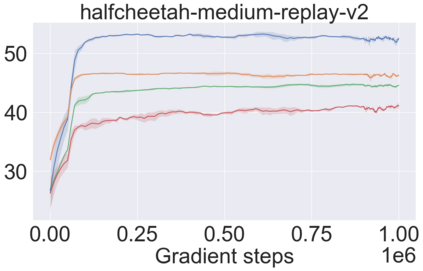
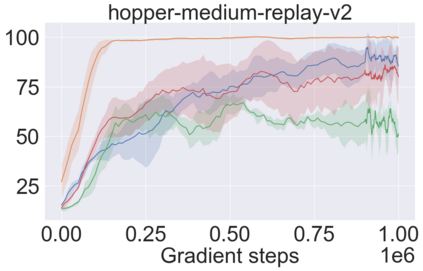
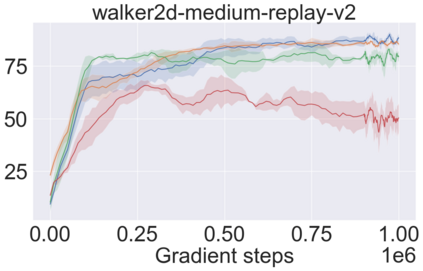
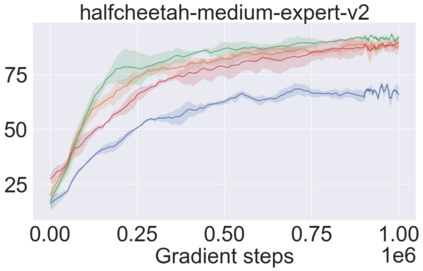
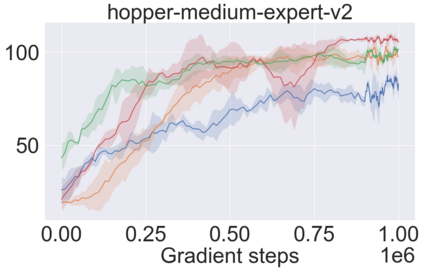
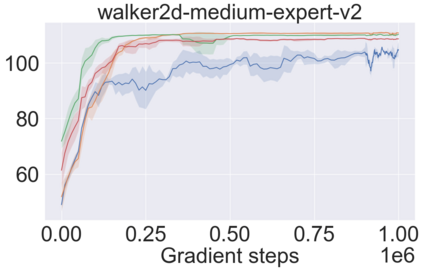
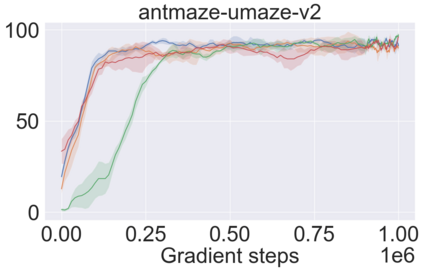
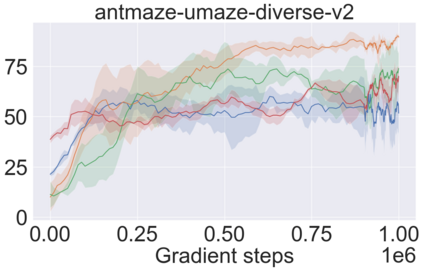
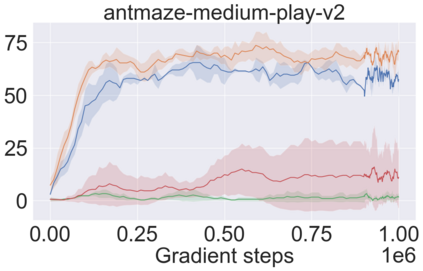
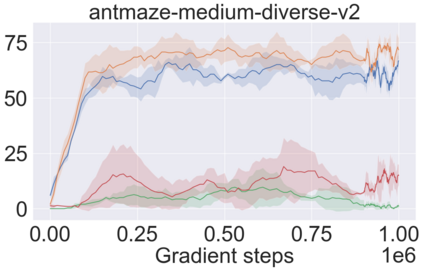
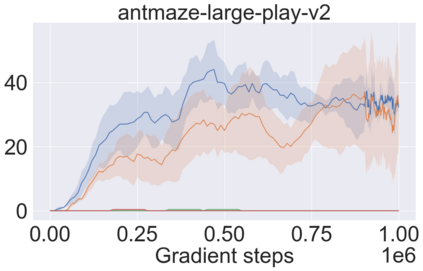
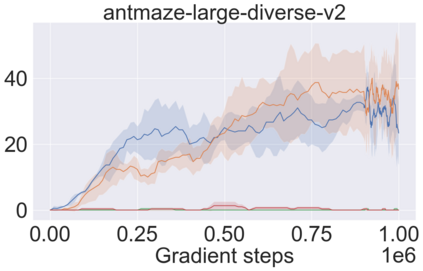
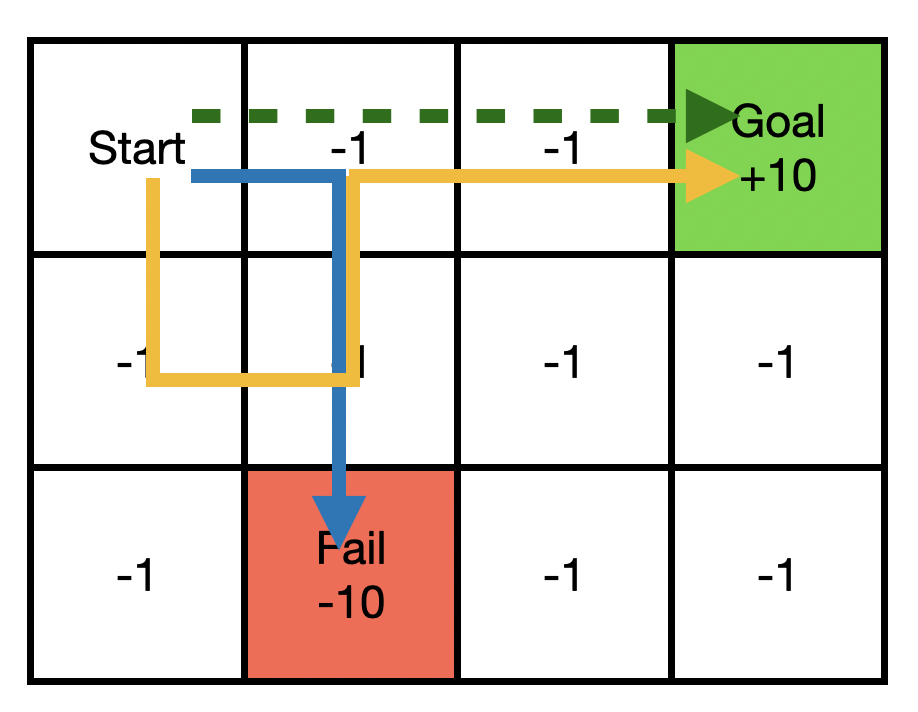
The main challenge of offline reinforcement learning, where data is limited, arises from a sequence of counterfactual reasoning dilemmas within the realm of potential actions: What if we were to choose a different course of action? These circumstances frequently give rise to extrapolation errors, which tend to accumulate exponentially with the problem horizon. Hence, it becomes crucial to acknowledge that not all decision steps are equally important to the final outcome, and to budget the number of counterfactual decisions a policy make in order to control the extrapolation. Contrary to existing approaches that use regularization on either the policy or value function, we propose an approach to explicitly bound the amount of out-of-distribution actions during training. Specifically, our method utilizes dynamic programming to decide where to extrapolate and where not to, with an upper bound on the decisions different from behavior policy. It balances between the potential for improvement from taking out-of-distribution actions and the risk of making errors due to extrapolation. Theoretically, we justify our method by the constrained optimality of the fixed point solution to our $Q$ updating rules. Empirically, we show that the overall performance of our method is better than the state-of-the-art offline RL methods on tasks in the widely-used D4RL benchmarks.
翻译:暂无翻译