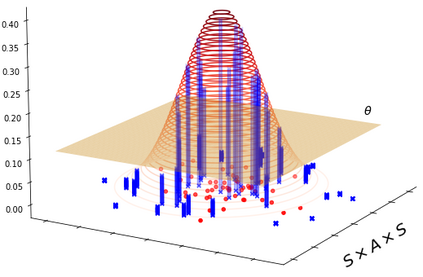
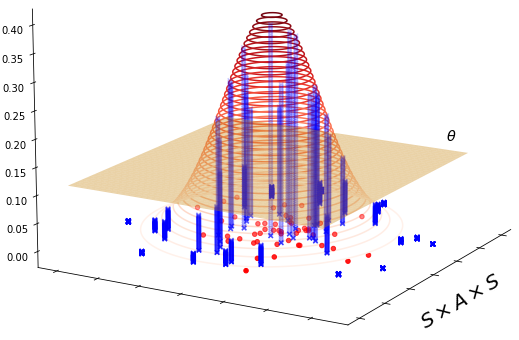
Learning a Markov Decision Process (MDP) from a fixed batch of trajectories is a non-trivial task whose outcome's quality depends on both the amount and the diversity of the sampled regions of the state-action space. Yet, many MDPs are endowed with invariant reward and transition functions with respect to some transformations of the current state and action. Being able to detect and exploit these structures could benefit not only the learning of the MDP but also the computation of its subsequent optimal control policy. In this work we propose a paradigm, based on Density Estimation methods, that aims to detect the presence of some already supposed transformations of the state-action space for which the MDP dynamics is invariant. We tested the proposed approach in a discrete toroidal grid environment and in two notorious environments of OpenAI's Gym Learning Suite. The results demonstrate that the model distributional shift is reduced when the dataset is augmented with the data obtained by using the detected symmetries, allowing for a more thorough and data-efficient learning of the transition functions.
翻译:从固定的轨迹中学习Markov决定程序(MDP)是一项非三重任务,其结果的质量取决于州-行动空间抽样区域的数量和多样性。然而,许多MDP在目前状态和行动的某些转变方面具有无差别的奖赏和过渡功能。能够探测和利用这些结构不仅有利于MDP的学习,而且有利于计算其随后的最佳控制政策。在这项工作中,我们提出了一个基于密度估计方法的模式,目的是检测MDP动力不变化的州-行动空间某些已经假设的变换的存在。我们在一个离散的至机器人电网环境中和OpenAI的Gym学习套件的两个臭名昭著的环境中测试了拟议办法。结果表明,如果利用所检测到的对称来扩大数据集,从而能够更彻底和有效地学习转型功能,模型分布变化就会减少。