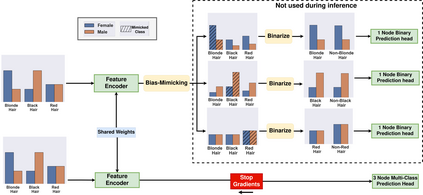
Prior work has shown that Visual Recognition datasets frequently underrepresent bias groups $B$ (\eg Female) within class labels $Y$ (\eg Programmers). This dataset bias can lead to models that learn spurious correlations between class labels and bias groups such as age, gender, or race. Most recent methods that address this problem require significant architectural changes or additional loss functions requiring more hyper-parameter tuning. Alternatively, data sampling baselines from the class imbalance literature (\eg Undersampling, Upweighting), which can often be implemented in a single line of code and often have no hyperparameters, offer a cheaper and more efficient solution. However, these methods suffer from significant shortcomings. For example, Undersampling drops a significant part of the input distribution while Oversampling repeats samples, causing overfitting. To address these shortcomings, we introduce a new class conditioned sampling method: Bias Mimicking. The method is based on the observation that if a class $c$ bias distribution, \ie $P_D(B|Y=c)$ is mimicked across every $c^{\prime}\neq c$, then $Y$ and $B$ are statistically independent. Using this notion, BM, through a novel training procedure, ensures that the model is exposed to the entire distribution without repeating samples. Consequently, Bias Mimicking improves underrepresented groups average accuracy of sampling methods by 3\% over four benchmarks while maintaining and sometimes improving performance over non sampling methods. Code can be found in https://github.com/mqraitem/Bias-Mimicking
翻译:先前的工作显示, 视觉识别数据集经常在类标签( eg Propublic Propublicers) 中出现偏差类别 $B$ (eg Fender) 。 这种数据集偏差可能导致一些模型, 了解类标签与年龄、 性别或种族等偏差群体之间的虚假关联。 大部分最近解决这一问题的方法需要重大的建筑变化或额外损失功能, 需要更高的参数调整。 或者, 类不平衡文献的数据抽样基线( eg Underspering, 提高重量) 通常可以在单行代码中执行, 并且往往没有超参数, 提供更便宜和更有效的解决方案。 然而, 这些方法有显著的缺陷。 例如, 底抽样减少大量输入分布, 而过重复制样本, 导致过度适应。 为了克服这些缺陷, 我们引入了一个新的等级条件抽样方法: 比亚斯 Mimicking。 该方法基于这样的观察, 如果一个等级的偏差分布,\ $ $ (B_ D_ Y=come=cal $), 在每一个基数的精度样本中, 的精度分析中可以改进 。