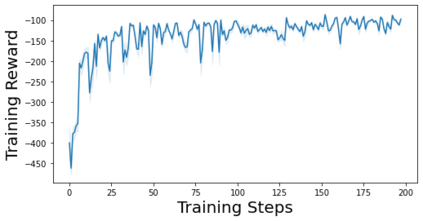
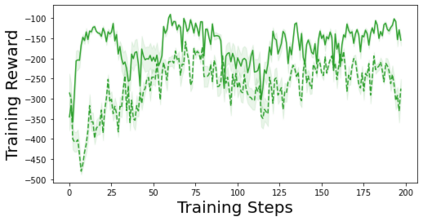
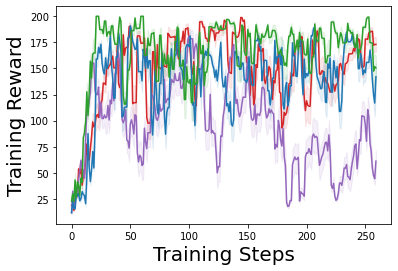
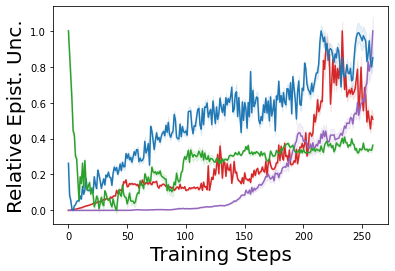
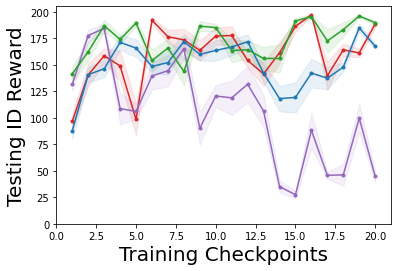
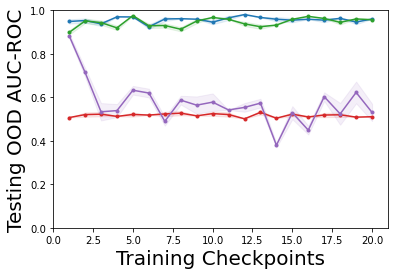
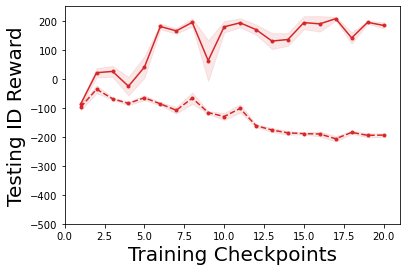
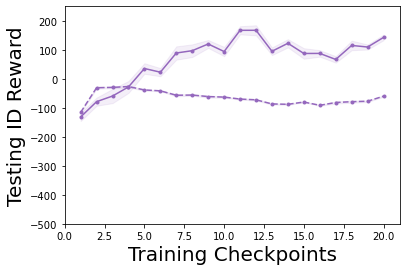
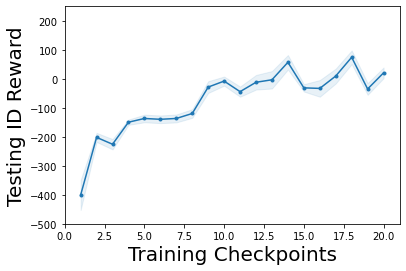
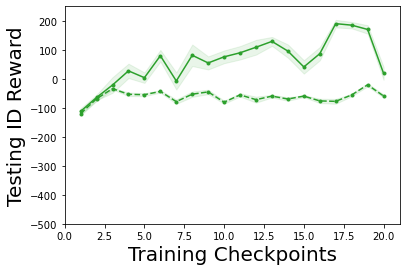
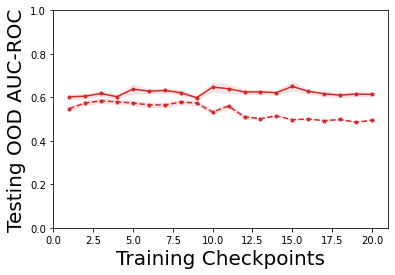
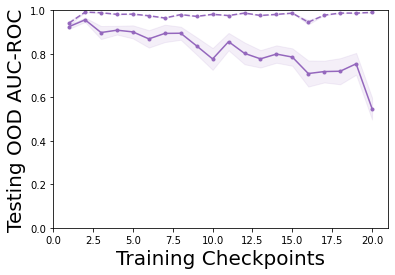
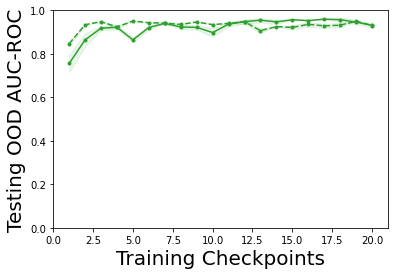
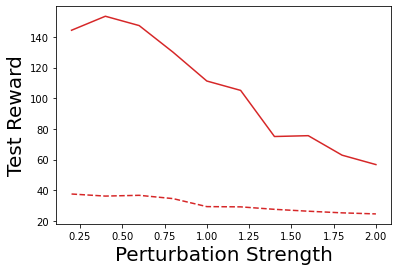
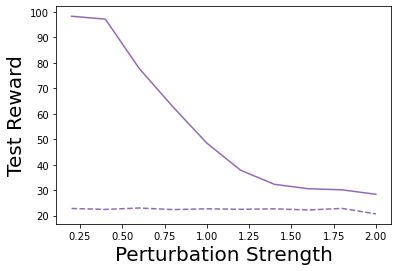
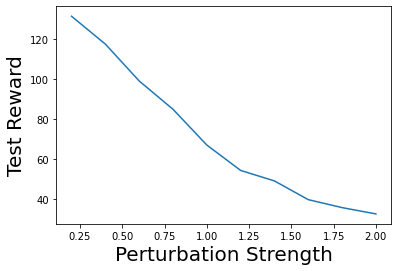
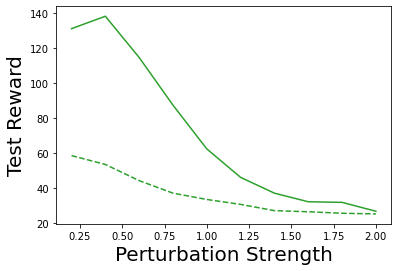
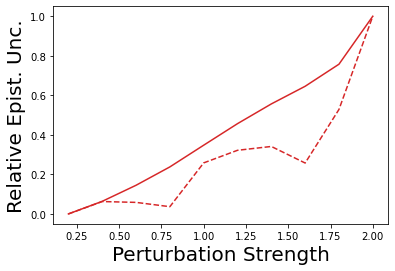
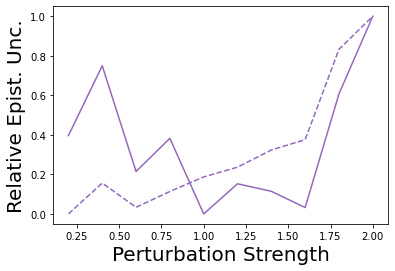
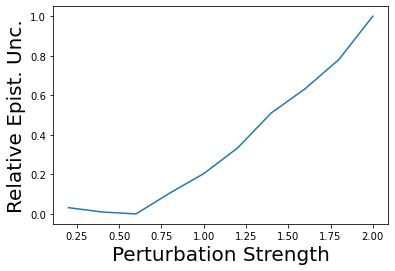
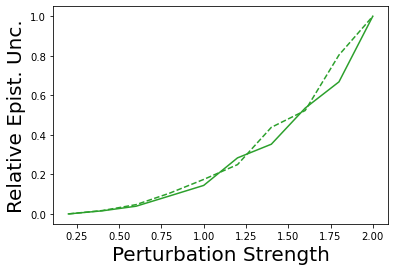
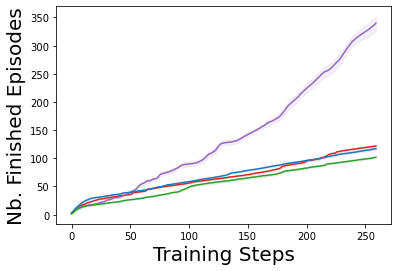
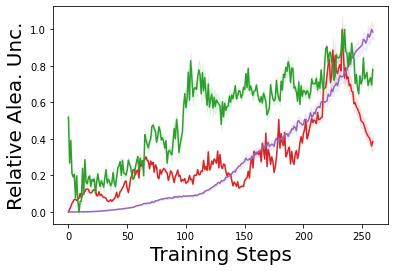
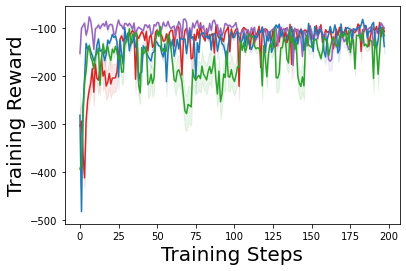
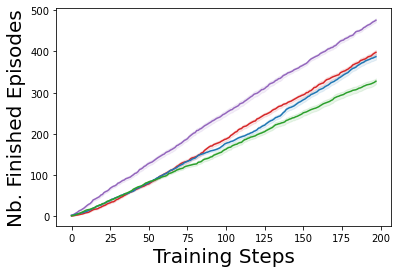
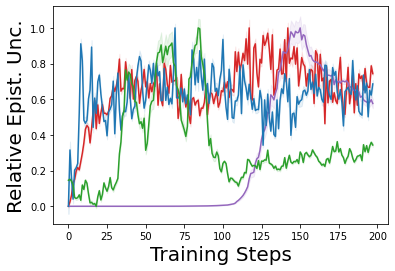
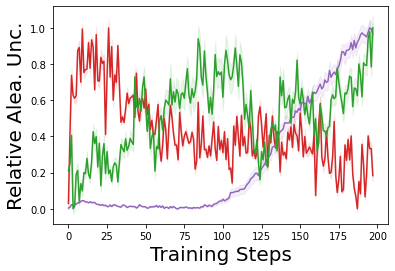
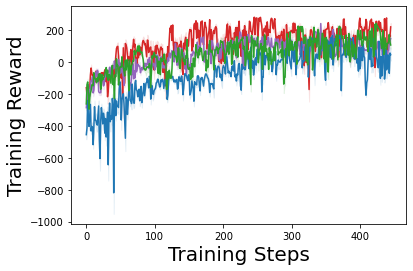
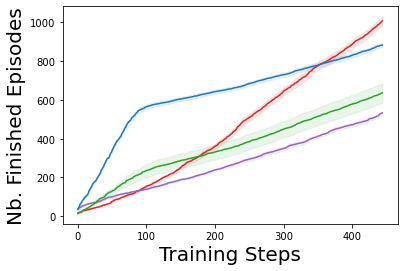
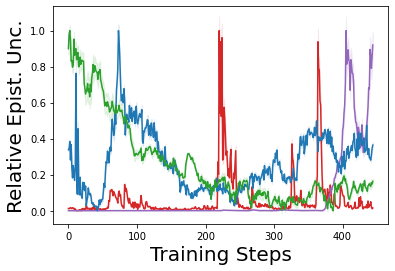
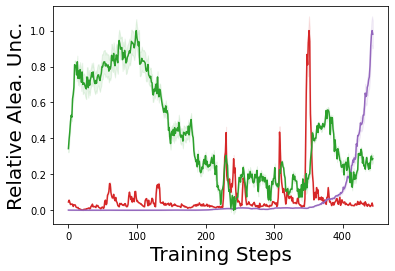
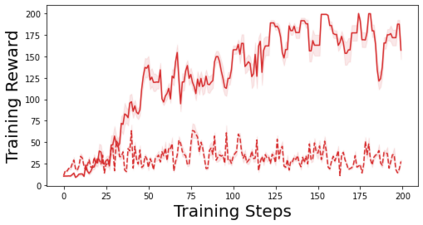
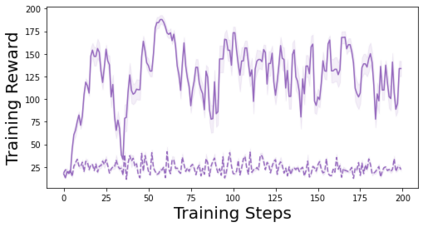
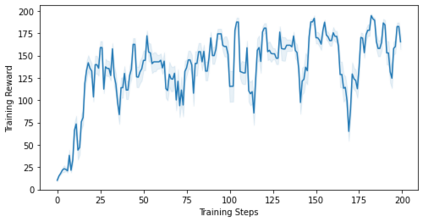
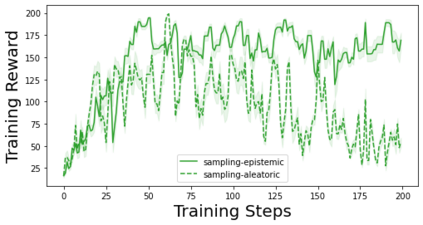
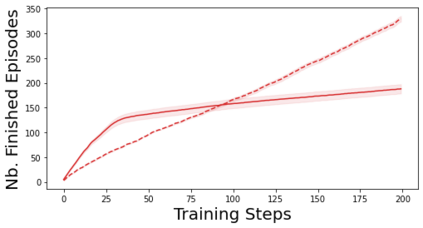
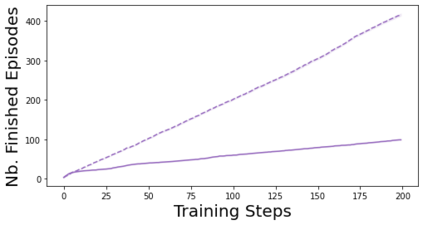
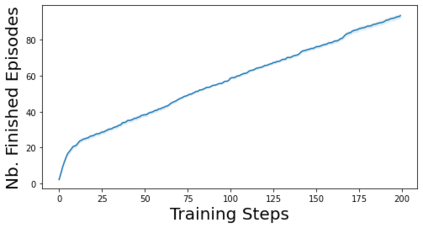
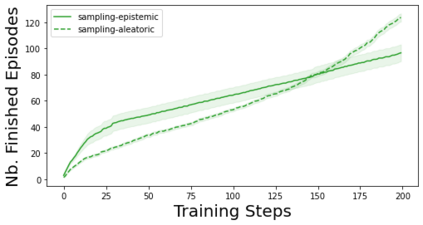
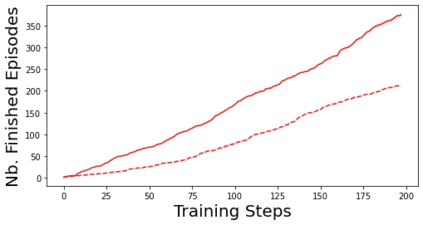
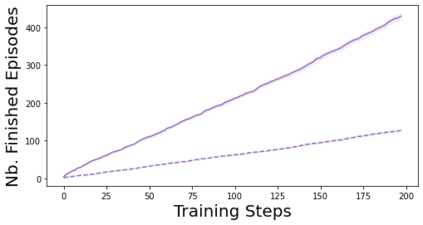
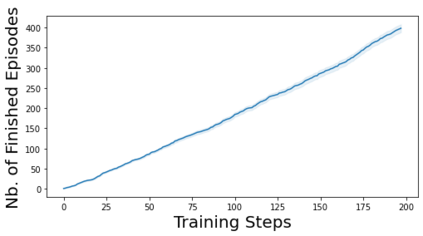
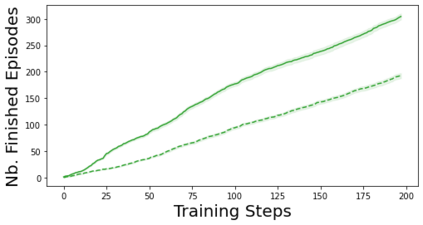
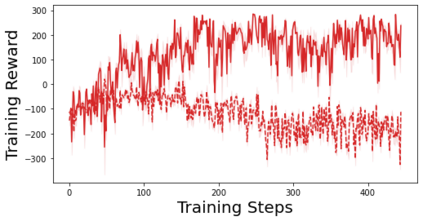
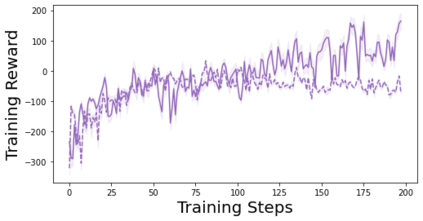
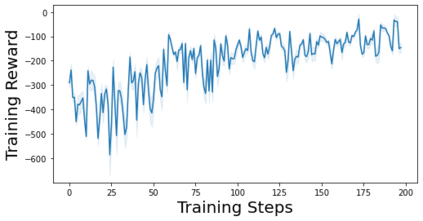
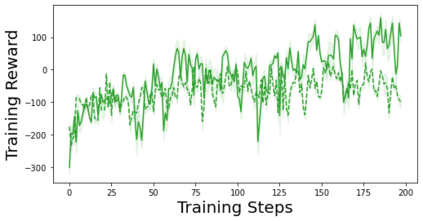
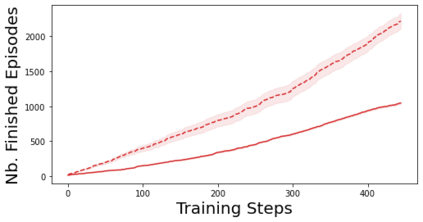
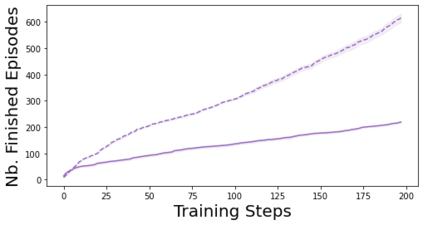
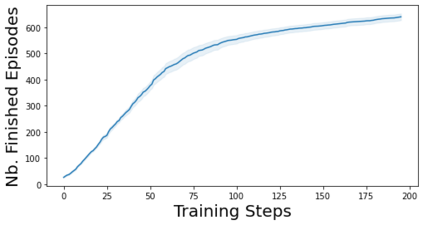
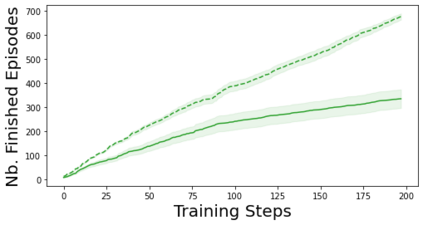
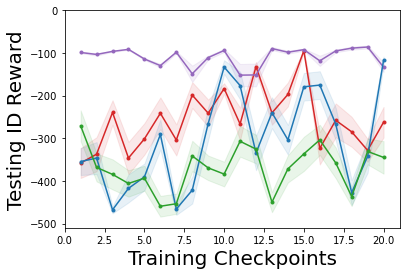
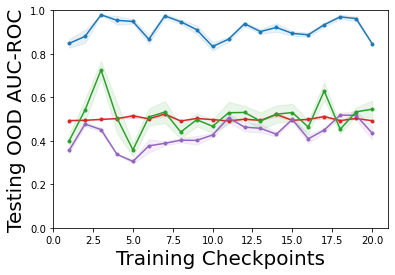
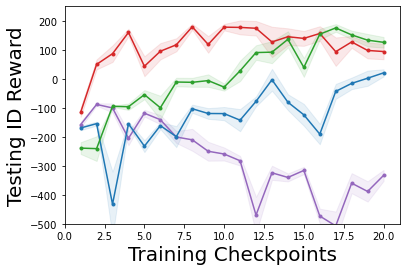
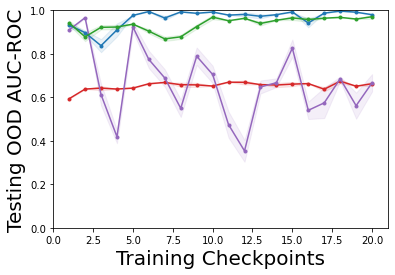
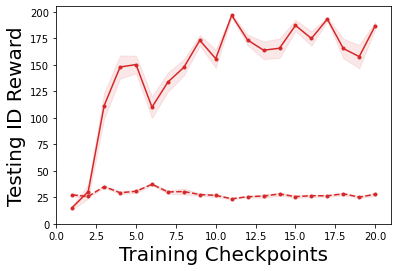
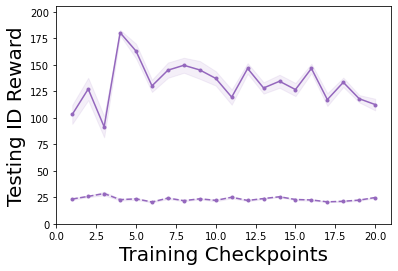
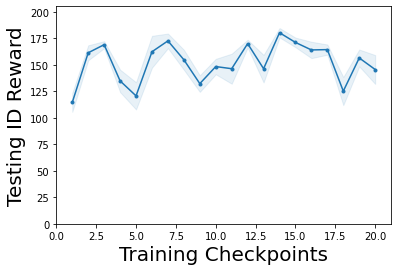
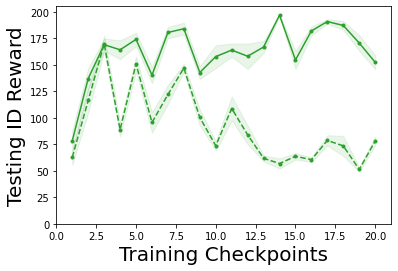
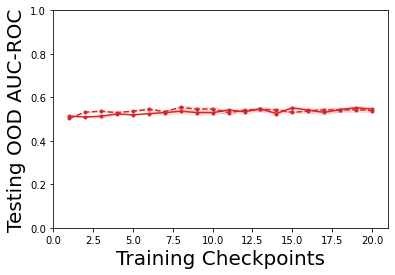
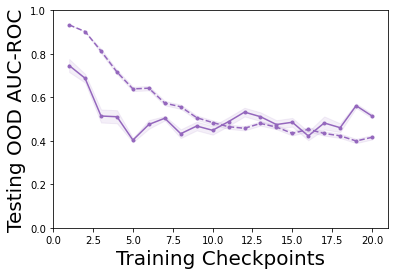
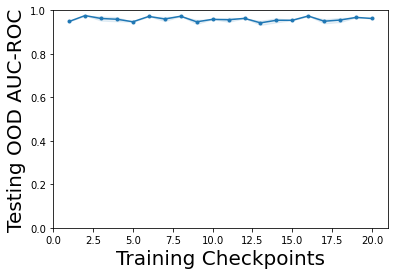
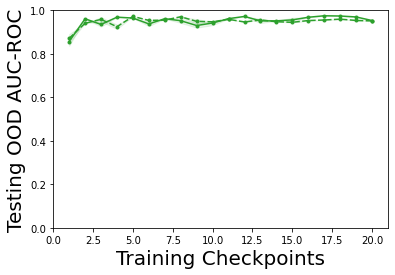
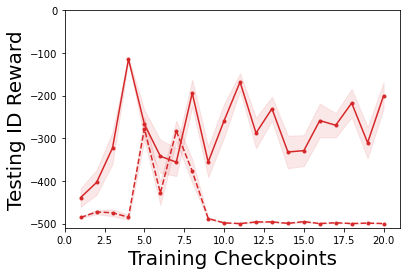
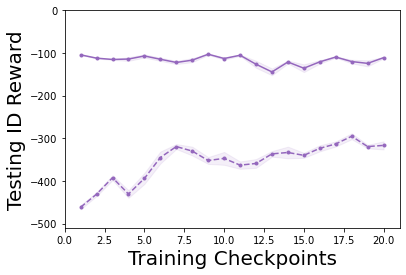
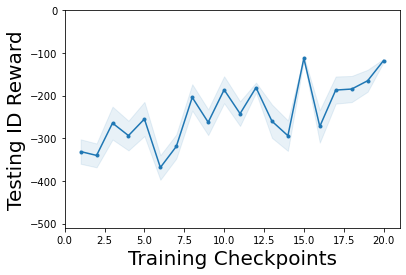
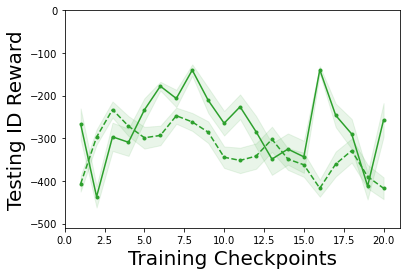
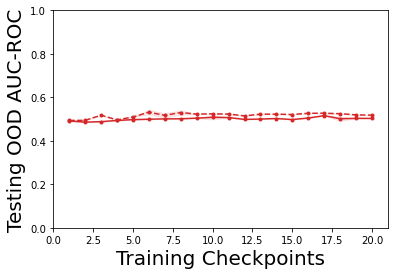
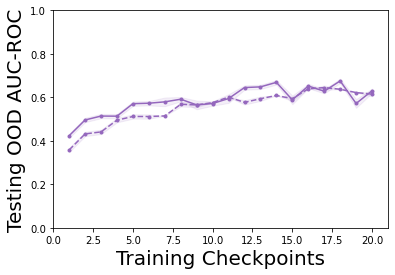
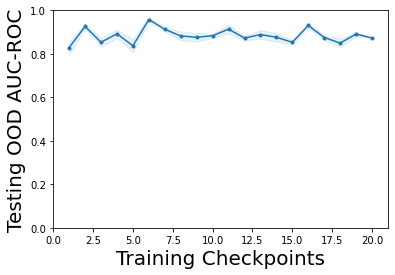
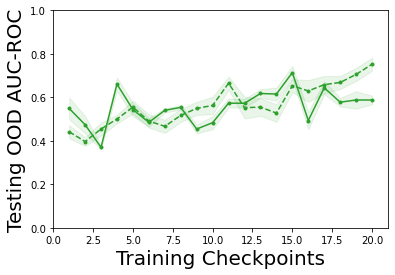
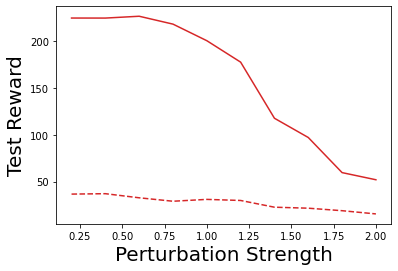
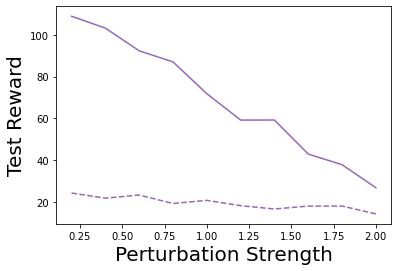
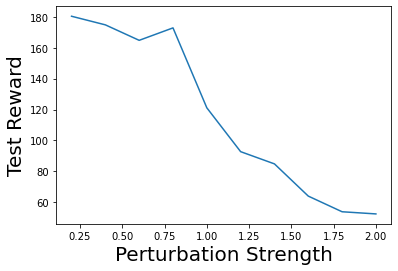
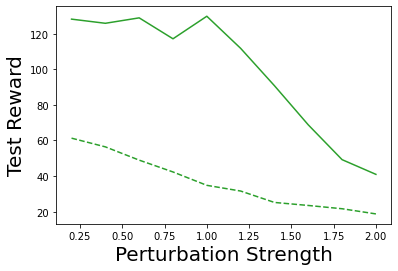
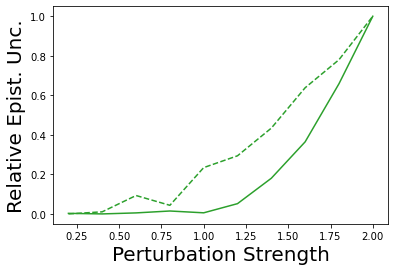
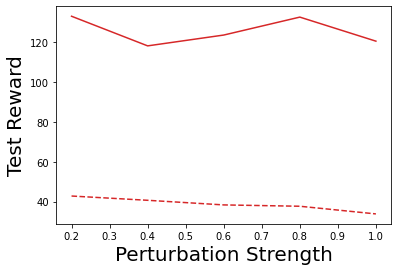
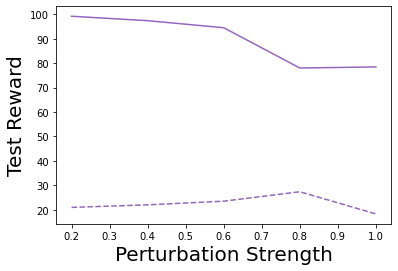
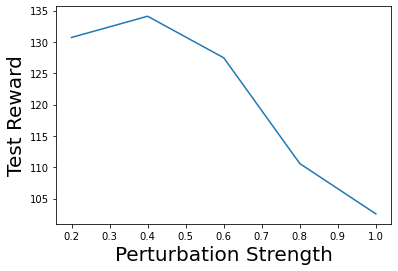
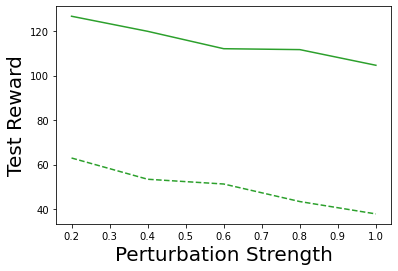
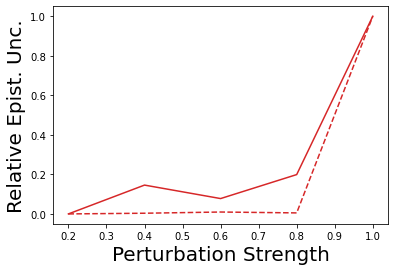
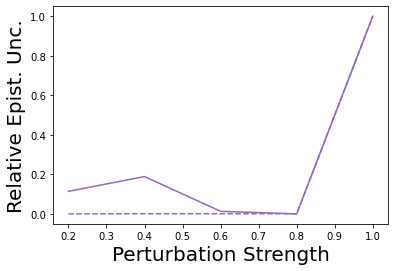
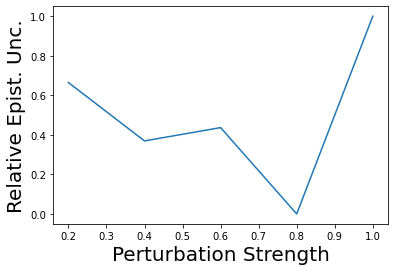
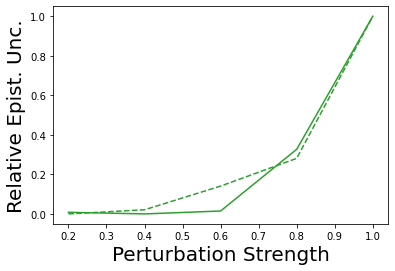
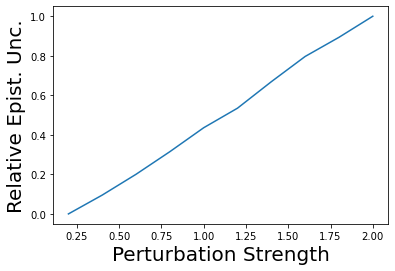
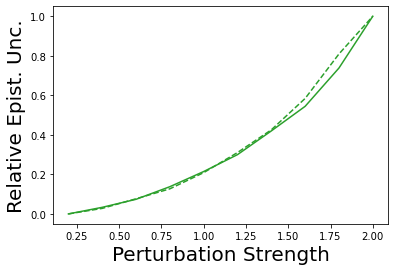
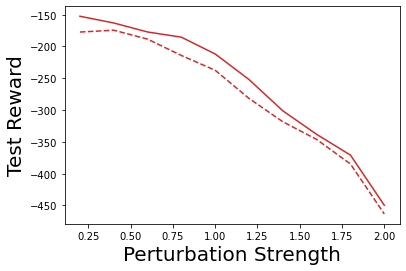
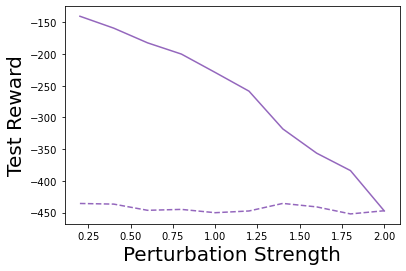
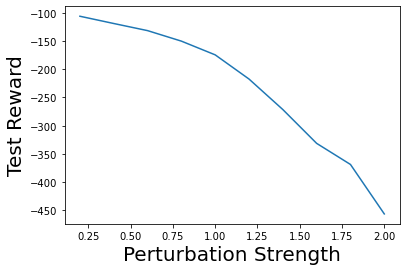
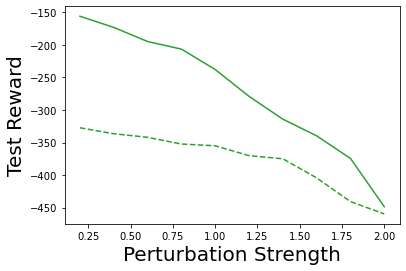
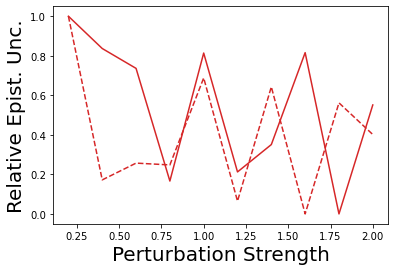
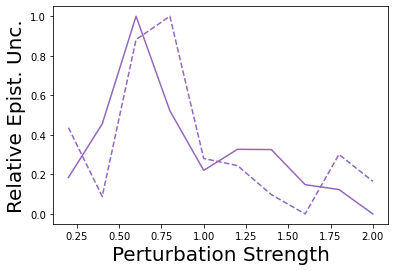
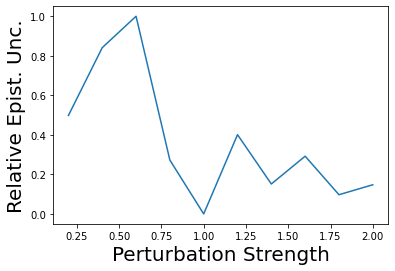
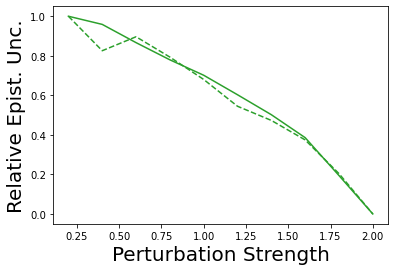
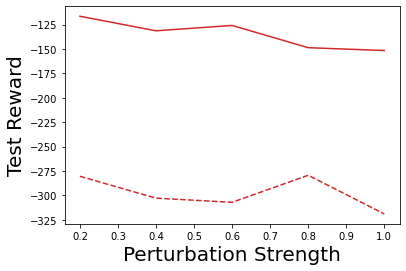
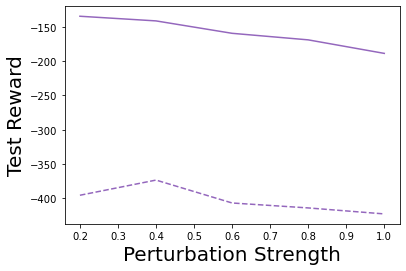
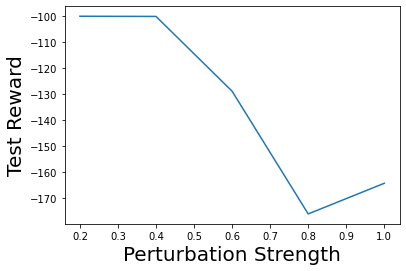
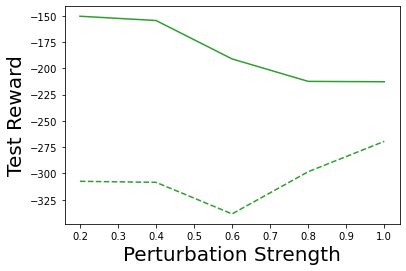
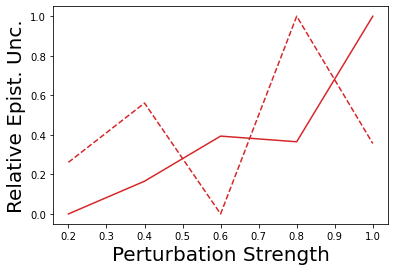
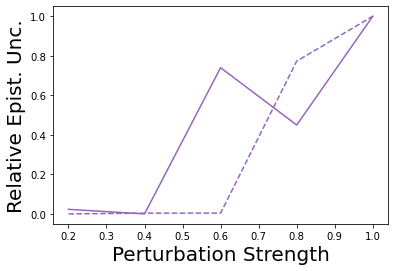
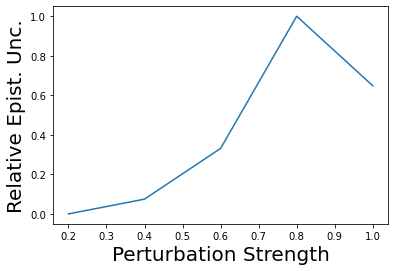
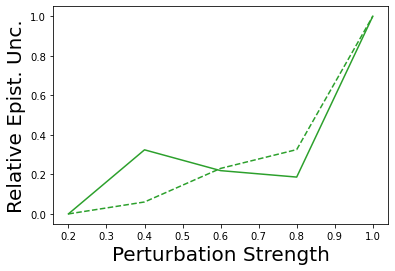
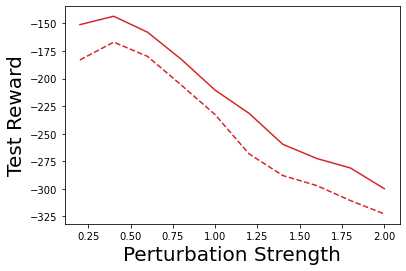
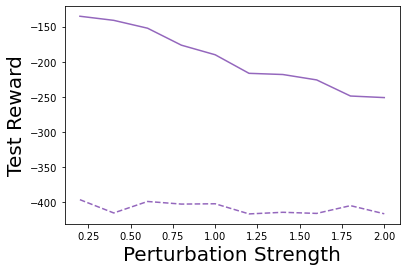
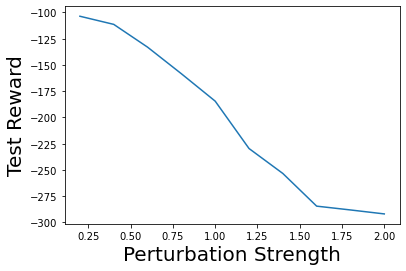
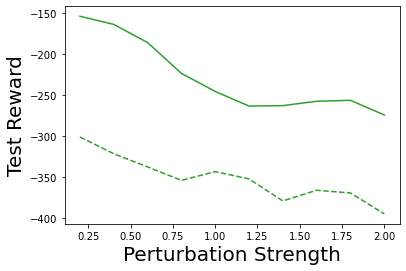
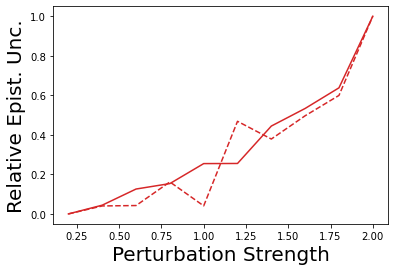
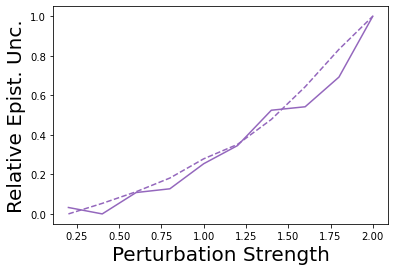
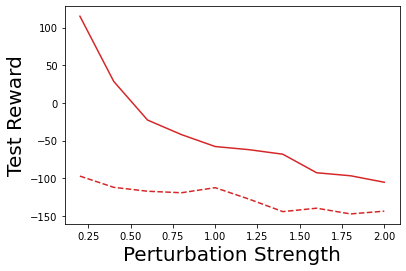
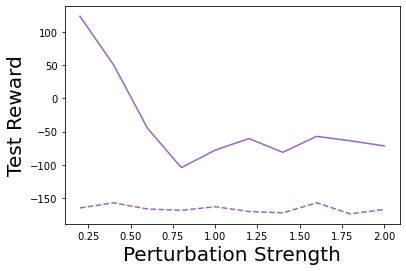
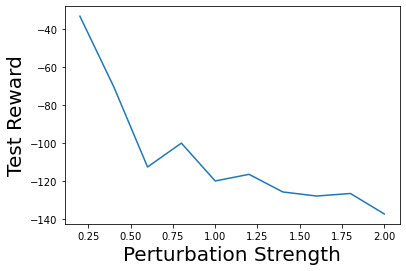
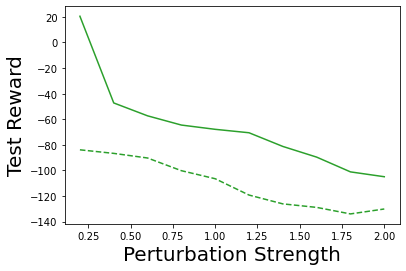
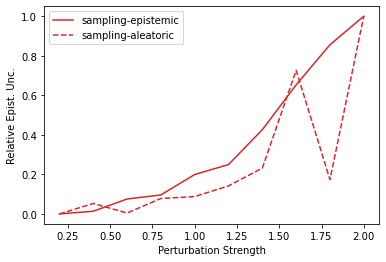
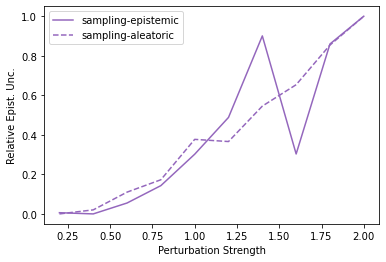
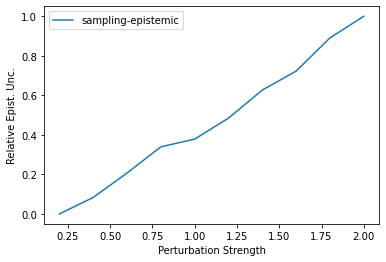
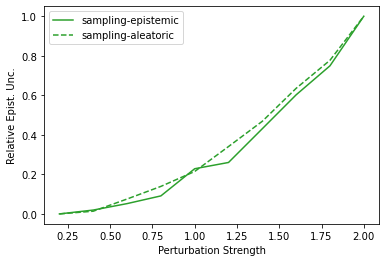
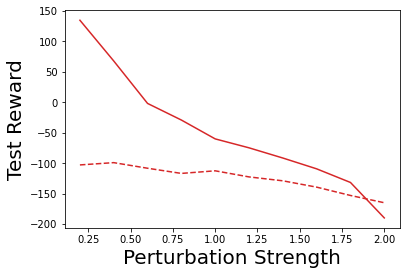
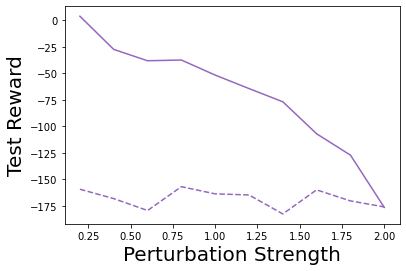
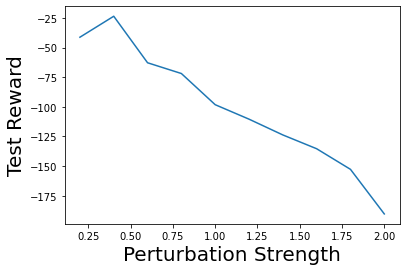
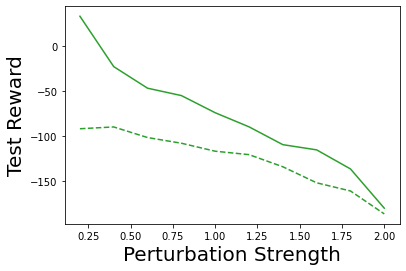
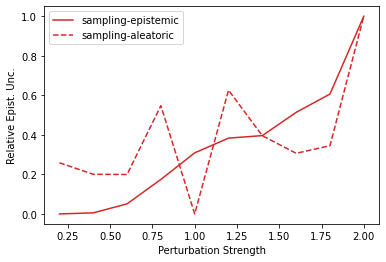
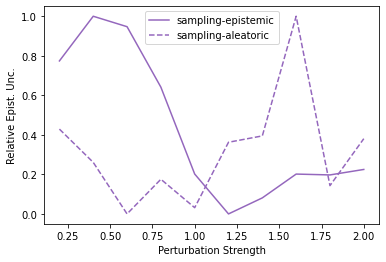
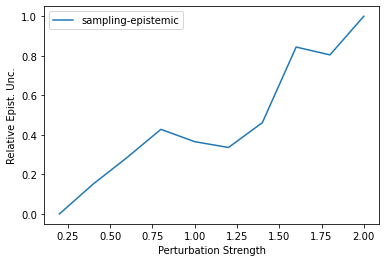
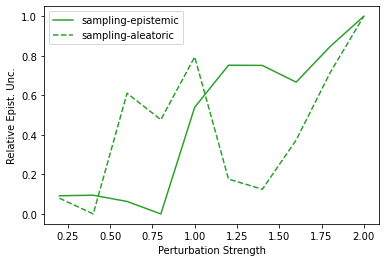
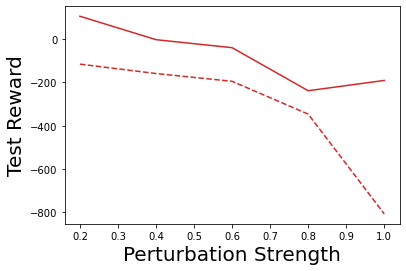
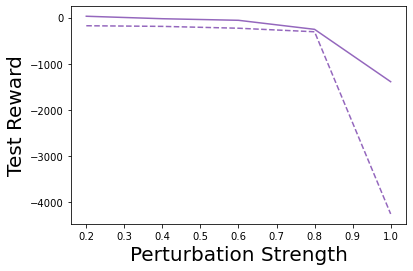
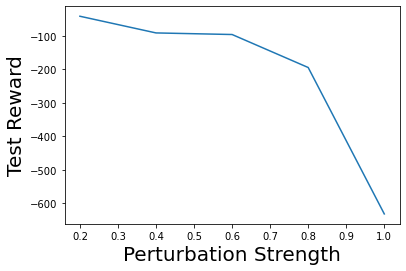
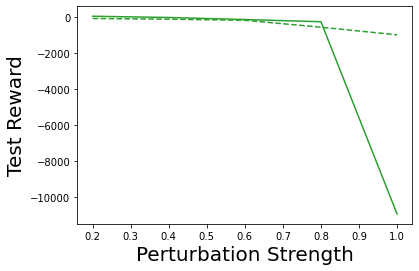
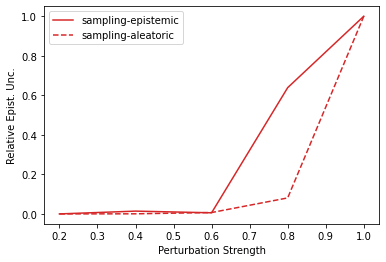
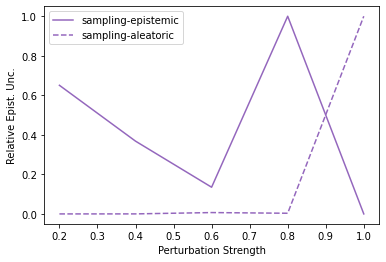
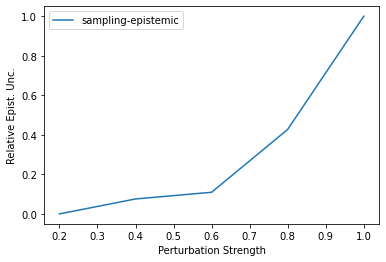
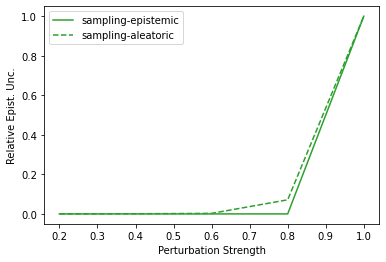
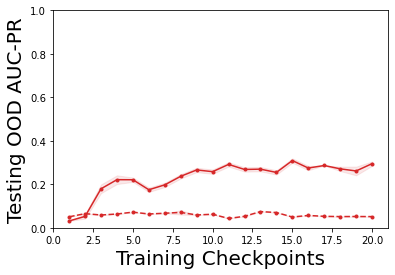
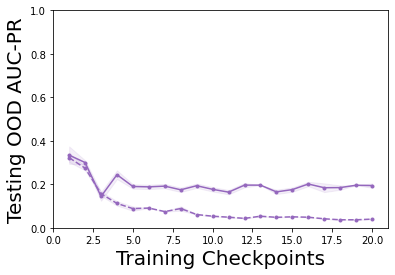
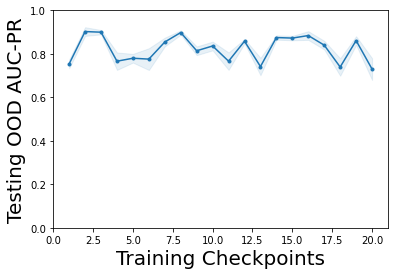
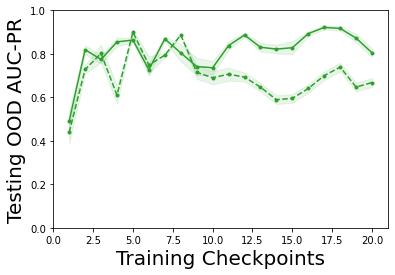
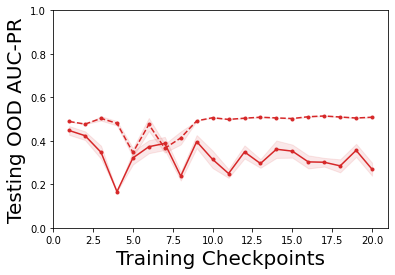
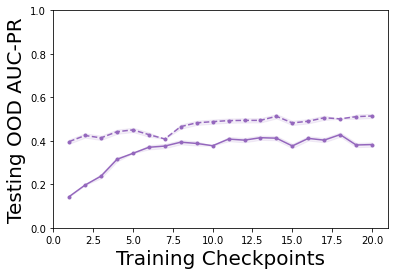
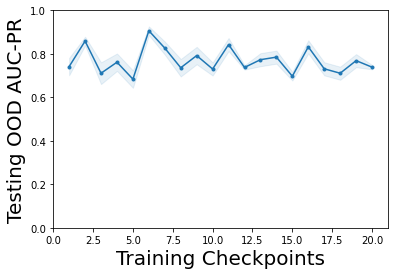
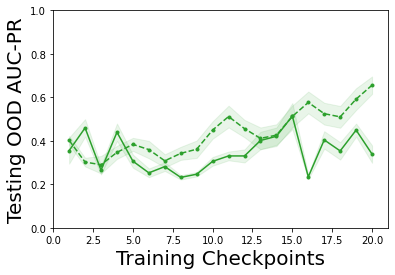
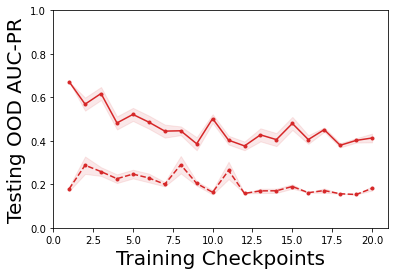
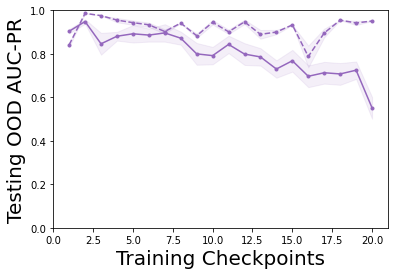
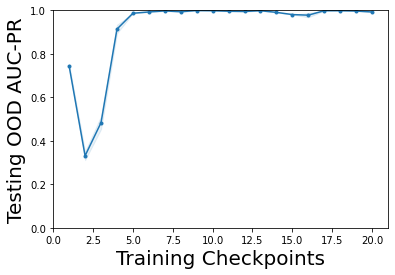
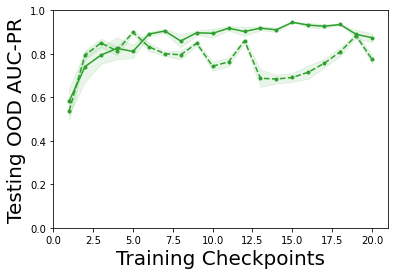
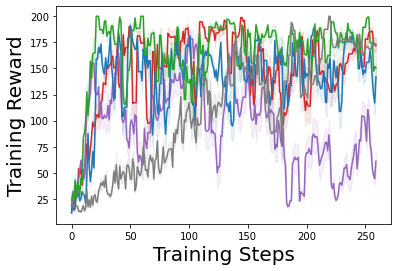
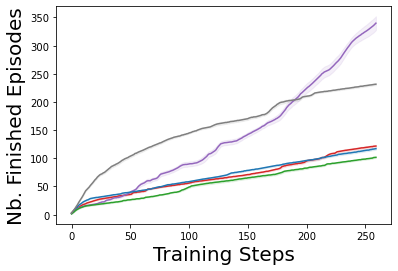
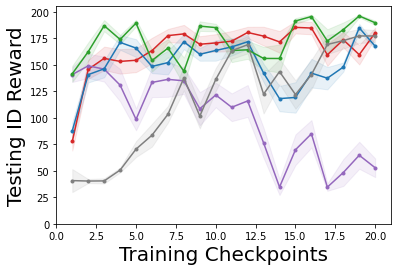
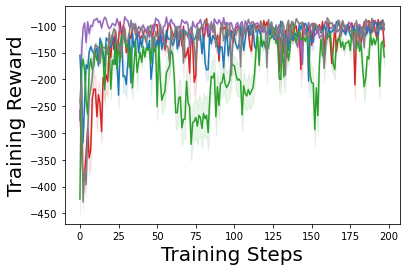
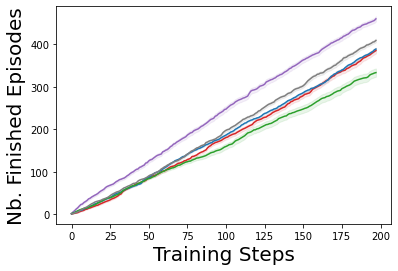
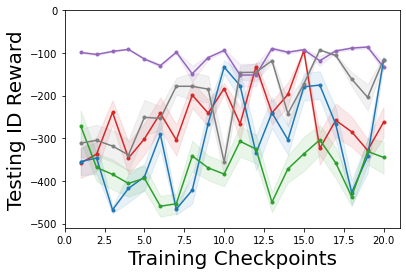
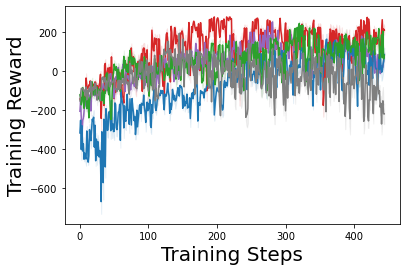
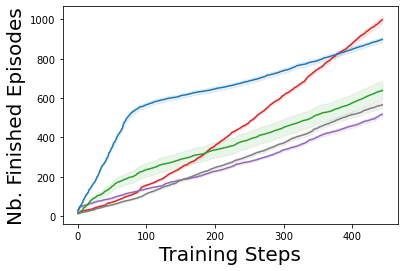
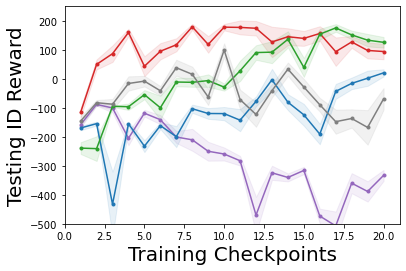
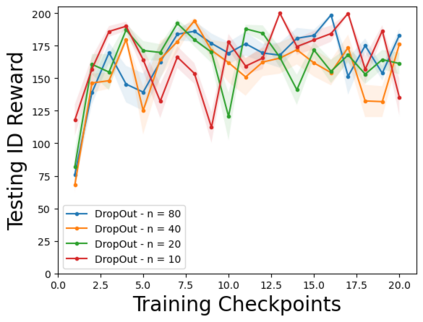
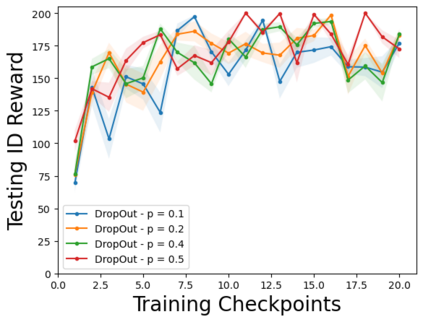
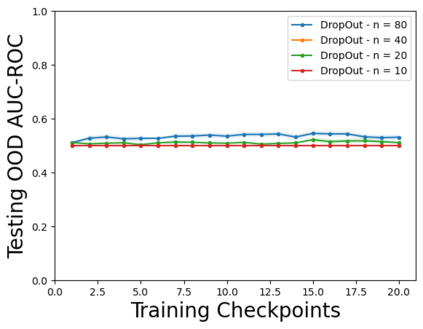
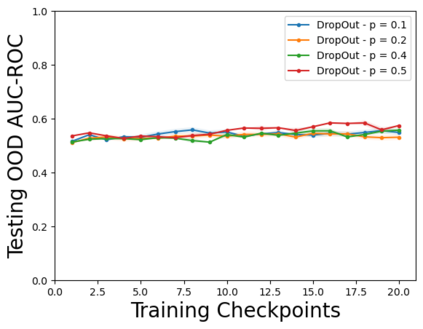
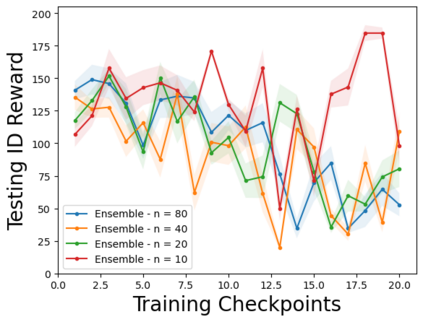
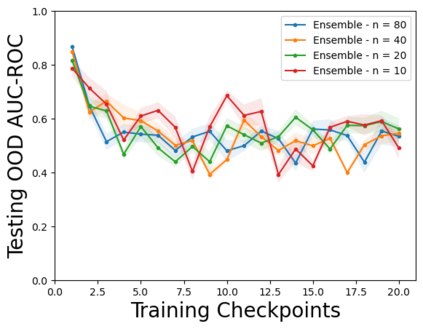
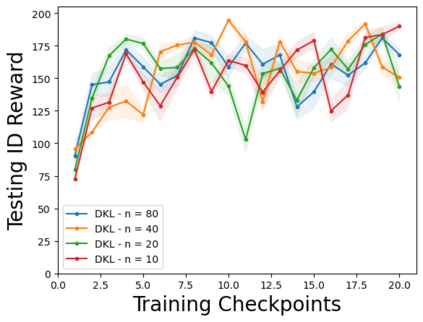
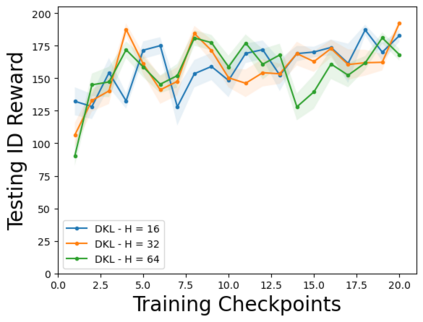
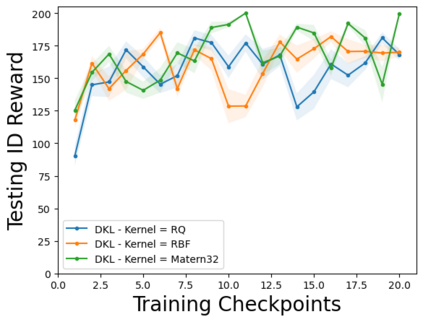
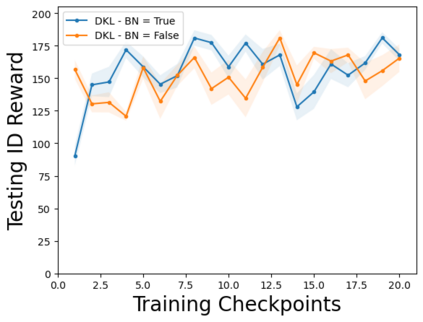
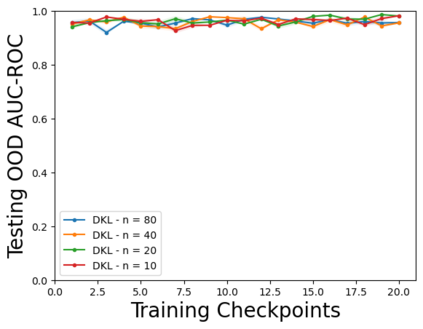
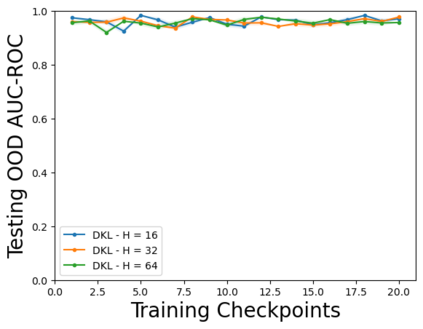
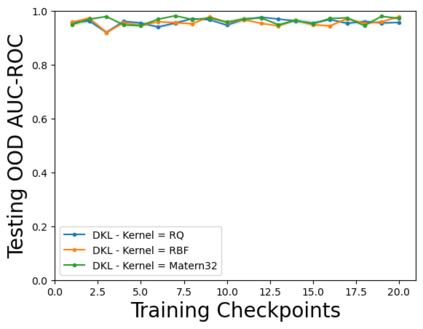
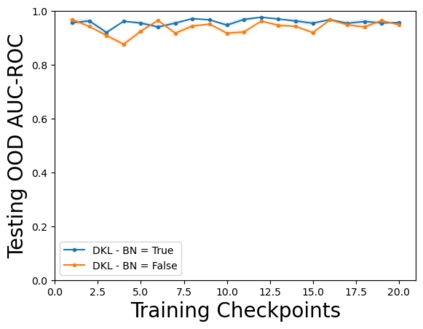
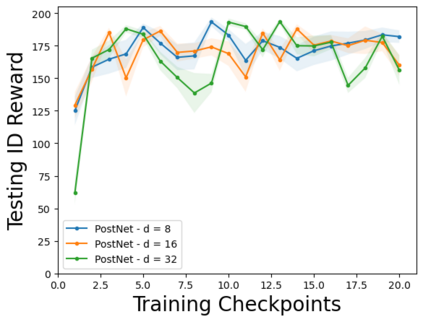
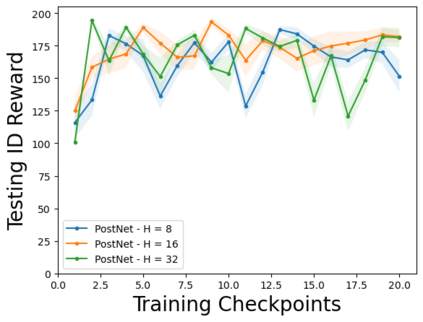
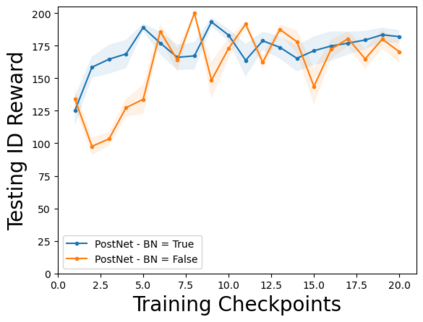
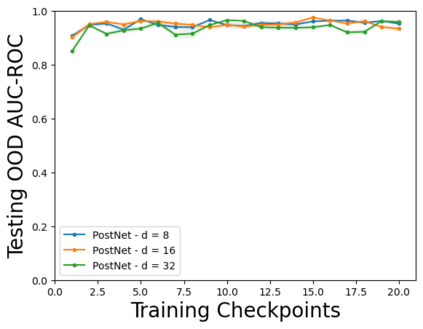
Characterizing aleatoric and epistemic uncertainty on the predicted rewards can help in building reliable reinforcement learning (RL) systems. Aleatoric uncertainty results from the irreducible environment stochasticity leading to inherently risky states and actions. Epistemic uncertainty results from the limited information accumulated during learning to make informed decisions. Characterizing aleatoric and epistemic uncertainty can be used to speed up learning in a training environment, improve generalization to similar testing environments, and flag unfamiliar behavior in anomalous testing environments. In this work, we introduce a framework for disentangling aleatoric and epistemic uncertainty in RL. (1) We first define four desiderata that capture the desired behavior for aleatoric and epistemic uncertainty estimation in RL at both training and testing time. (2) We then present four RL models inspired by supervised learning (i.e. Monte Carlo dropout, ensemble, deep kernel learning models, and evidential networks) to instantiate aleatoric and epistemic uncertainty. Finally, (3) we propose a practical evaluation method to evaluate uncertainty estimation in model-free RL based on detection of out-of-distribution environments and generalization to perturbed environments. We present theoretical and experimental evidence to validate that carefully equipping model-free RL agents with supervised learning uncertainty methods can fulfill our desiderata.
翻译:在预测的奖赏中,确定优异和隐性不确定性有助于建立可靠的强化学习(RL)系统。在这项工作中,我们引入了一个框架,在RL中,分解了疏松的和隐化的不确定性。(1) 我们首先界定了四种偏差,在培训和测试期间,在RL中,既能捕捉到所希望的偏移和隐化的不确定性估计所需的行为,又能捕捉到所希望的偏移和隐化的不确定性估计。(2) 然后,我们提出四个受监督的学习(如蒙特卡洛辍学、高调、深层内核内核学习模式和显性网络)启发的RL模型模型模型,以便进行即时解析和隐化不确定性的不确定性分析。(3) 我们提出一种实用的评估方法,以便在模型和测试期间,根据无弹性的理论环境来评估不确定性的不定性和不定性的理论评估。