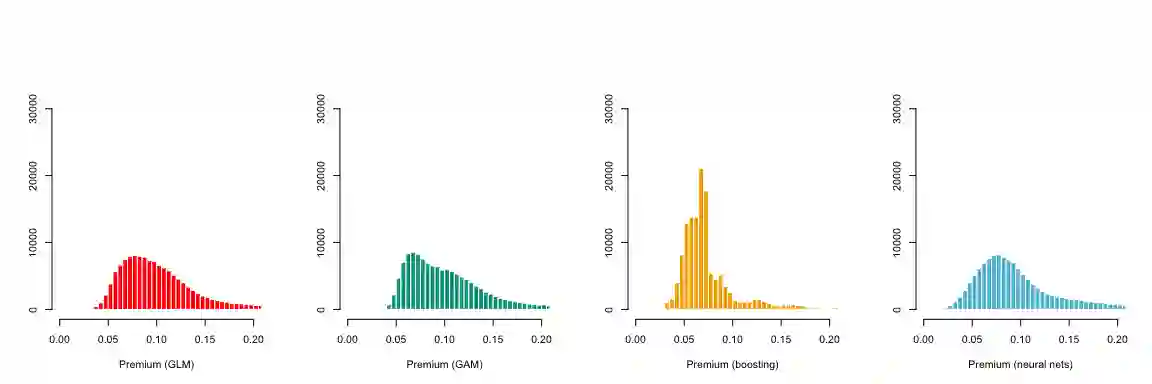
Boosting techniques and neural networks are particularly effective machine learning methods for insurance pricing. Often in practice, there are nevertheless endless debates about the choice of the right loss function to be used to train the machine learning model, as well as about the appropriate metric to assess the performances of competing models. Also, the sum of fitted values can depart from the observed totals to a large extent and this often confuses actuarial analysts. The lack of balance inherent to training models by minimizing deviance outside the familiar GLM with canonical link setting has been empirically documented in W\"uthrich (2019, 2020) who attributes it to the early stopping rule in gradient descent methods for model fitting. The present paper aims to further study this phenomenon when learning proceeds by minimizing Tweedie deviance. It is shown that minimizing deviance involves a trade-off between the integral of weighted differences of lower partial moments and the bias measured on a specific scale. Autocalibration is then proposed as a remedy. This new method to correct for bias adds an extra local GLM step to the analysis. Theoretically, it is shown that it implements the autocalibration concept in pure premium calculation and ensures that balance also holds on a local scale, not only at portfolio level as with existing bias-correction techniques. The convex order appears to be the natural tool to compare competing models, putting a new light on the diagnostic graphs and associated metrics proposed by Denuit et al. (2019).
翻译:激励技术和神经网络是保险定价方面特别有效的机械学习方法。 通常在实践中,对于如何选择用于培训机器学习模式的正确损失功能,以及评估竞争模式绩效的适当衡量标准,人们辩论无休止地讨论如何选择正确的损失功能,以培训机器学习模式,以及评估竞争模式绩效的适当衡量标准。此外,适应价值的总和可能在很大程度上偏离所观察到的总和,这往往混淆了精算分析师。通过尽量减少熟悉的GLM外的偏离和卡通联系设置,使培训模式内在的不平衡性最小化,这在W\"uthurich (2019,2020年) 中已有经验记录,后者将其归因于在模型安装的梯度下降方法中的早期停止规则。本文件旨在通过尽量减少 Tweedie deviance 学习收益来进一步研究这一现象。 事实表明,尽可能减少偏离价值的总和,这需要权衡较低部分时间的加权差异和特定尺度的偏差。 然后提出“自动校正”作为补救的一种新模式。这种纠正偏差的新方法为分析增加了当地GLM的一步。 理论上,它表明,它只是将自动校正比值概念放在纯粹的比值上。