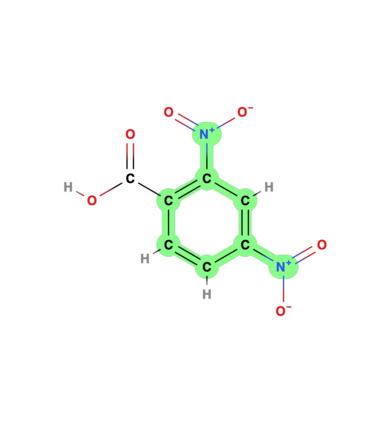
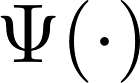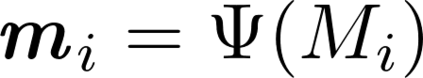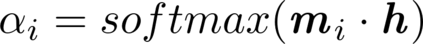We consider the explanation problem of Graph Neural Networks (GNNs). Most existing GNN explanation methods identify the most important edges or nodes but fail to consider substructures, which are more important for graph data. The only method that considers subgraphs tries to search all possible subgraphs and identify the most significant subgraphs. However, the subgraphs identified may not be recurrent or statistically important. In this work, we propose a novel method, known as MotifExplainer, to explain GNNs by identifying important motifs, recurrent and statistically significant patterns in graphs. Our proposed motif-based methods can provide better human-understandable explanations than methods based on nodes, edges, and regular subgraphs. Given an input graph and a pre-trained GNN model, our method first extracts motifs in the graph using well-designed motif extraction rules. Then we generate motif embedding by feeding motifs into the pre-trained GNN. Finally, we employ an attention-based method to identify the most influential motifs as explanations for the final prediction results. The empirical studies on both synthetic and real-world datasets demonstrate the effectiveness of our method.
翻译:我们考虑的是图形神经网络(GNN)的解释问题。大多数现有的GNN解释方法都确定了最重要的边缘或节点,但却没有考虑子结构,这对于图形数据来说更为重要。唯一一种方法是考虑子组织试图搜索所有可能的子集和确定最重要的子集。然而,所查明的子集可能不是经常性的或统计上重要的。在这项工作中,我们提出了一个称为MotifExplainer的新颖方法,通过在图表中找出重要的点、经常性和具有统计意义的模式来解释GNN。我们提议的基于模型的方法比基于节点、边缘和常规子集的方法可以提供更好的人类无法理解的解释。考虑到输入图和预先训练过的GNNN模型,我们的方法首先在图表中提取motifs,使用精心设计的 motif 提取规则。然后我们通过将motifs嵌入预先训练过的GNNNM,我们用基于注意力的方法来确定最有影响力的模型,作为我们最终预测结果的解释。实验性研究既展示了我们真实世界数据的方法。