
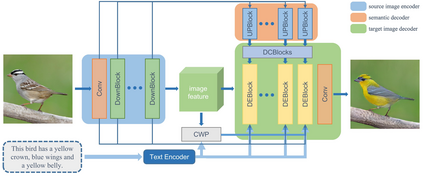
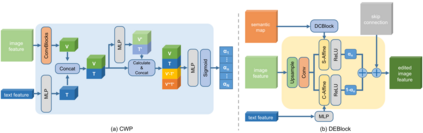
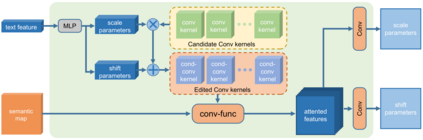
Text-guided image editing models have shown remarkable results. However, there remain two problems. First, they employ fixed manipulation modules for various editing requirements (e.g., color changing, texture changing, content adding and removing), which result in over-editing or insufficient editing. Second, they do not clearly distinguish between text-required parts and text-irrelevant parts, which leads to inaccurate editing. To solve these limitations, we propose: (i) a Dynamic Editing Block (DEBlock) which combines spatial- and channel-wise manipulations dynamically for various editing requirements. (ii) a Combination Weights Predictor (CWP) which predicts the combination weights for DEBlock according to the inference on text and visual features. (iii) a Dynamic text-adaptive Convolution Block (DCBlock) which queries source image features to distinguish text-required parts and text-irrelevant parts. Extensive experiments demonstrate that our DE-Net achieves excellent performance and manipulates source images more effectively and accurately. Code is available at \url{https://github.com/tobran/DE-Net}.
翻译:文本引导图像编辑模型显示了显著的结果。 但是,还存在两个问题。 首先,它们为各种编辑要求(例如,颜色变化、纹理变化、内容添加和删除)采用固定的操作模块,导致编辑过度或编辑不充分。 其次,它们没有明确区分文本要求的部分和文本不相关的部分,导致编辑不准确。 为了解决这些限制,我们建议:(一) 动态编辑块(DEBlock),它为各种编辑要求动态地将空间和频道操作结合起来。 (二) 组合 Weights 预测器(CWP),它根据文本和视觉特征的推论预测DEBlock的组合权重。 (三) 动态文本适应性演进区(DCBlock),它查询源图像特征,以区分文本要求的部件和文本不相关的部分。 广泛的实验表明,我们的DENet实现了出色的性能,并更有效和更准确地操纵源图像。代码可在\url{https://github.com/toran/Net}查阅源码。



相关内容

- Today (iOS and OS X): widgets for the Today view of Notification Center
- Share (iOS and OS X): post content to web services or share content with others
- Actions (iOS and OS X): app extensions to view or manipulate inside another app
- Photo Editing (iOS): edit a photo or video in Apple's Photos app with extensions from a third-party apps
- Finder Sync (OS X): remote file storage in the Finder with support for Finder content annotation
- Storage Provider (iOS): an interface between files inside an app and other apps on a user's device
- Custom Keyboard (iOS): system-wide alternative keyboards
Source: iOS 8 Extensions: Apple’s Plan for a Powerful App Ecosystem


