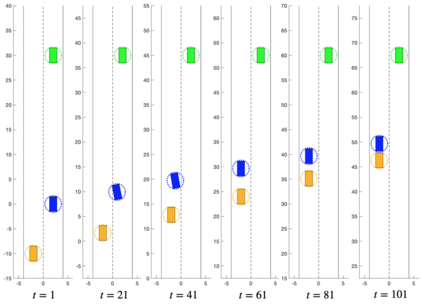
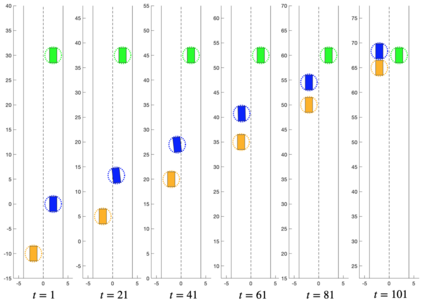
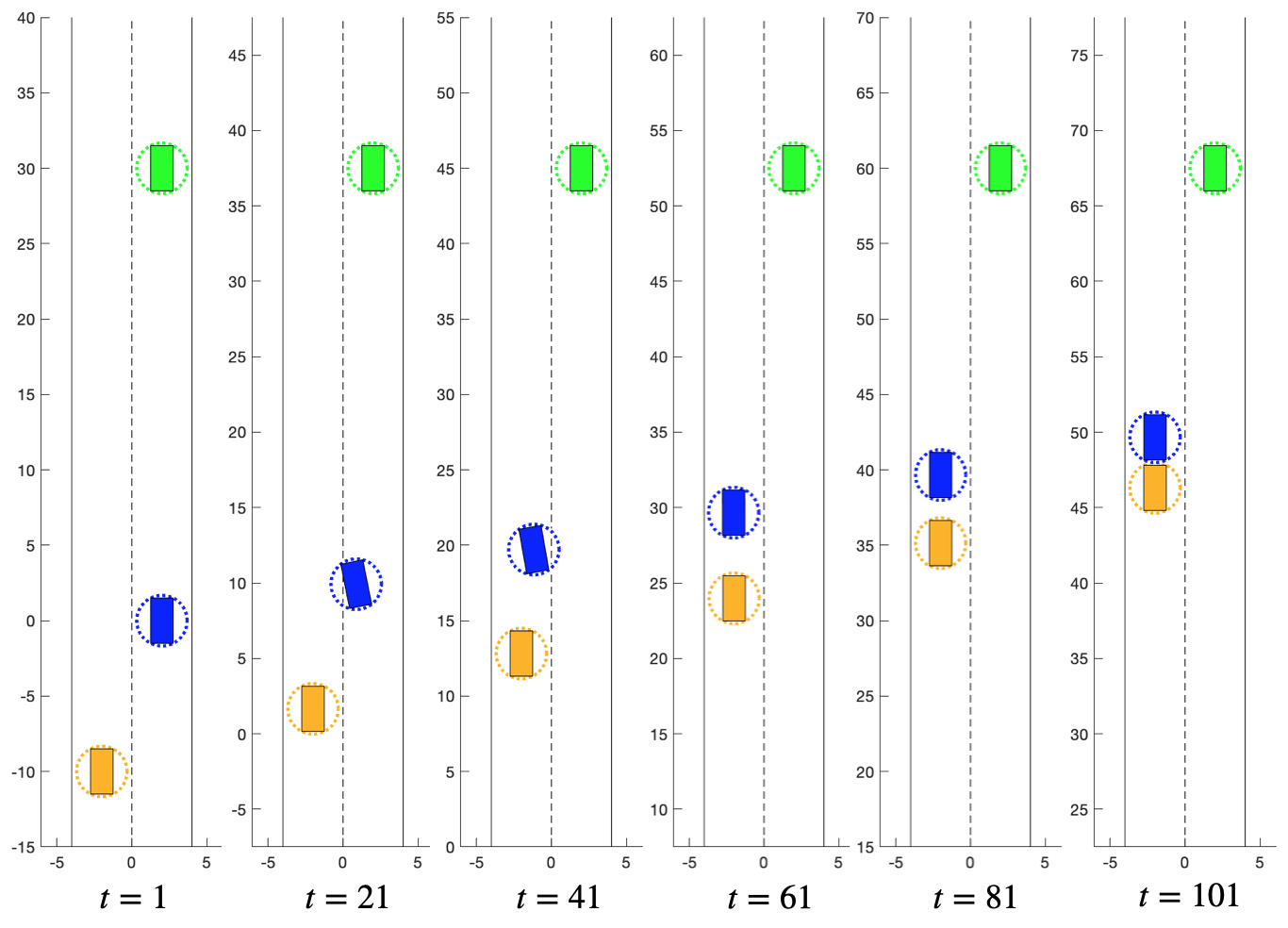
We present the concept of a Generalized Feedback Nash Equilibrium (GFNE) in dynamic games, extending the Feedback Nash Equilibrium concept to games in which players are subject to state and input constraints. We formalize necessary and sufficient conditions for (local) GFNE solutions at the trajectory level, which enable the development of efficient numerical methods for their computation. Specifically, we propose a Newton-style method for finding game trajectories which satisfy the necessary conditions, which can then be checked against the sufficiency conditions. We show that the evaluation of the necessary conditions in general requires computing a series of nested, implicitly-defined derivatives, which quickly becomes intractable. To this end, we introduce an approximation to the necessary conditions which is amenable to efficient evaluation, and in turn, computation of solutions. We term the solutions to the approximate necessary conditions Generalized Feedback Quasi Nash Equilibria (GFQNE), and we introduce numerical methods for their computation. In particular, we develop a Sequential Linear-Quadratic Game approach, in which a locally approximate LQ game is solved at each iteration. The development of this method relies on the ability to compute a GFNE to inequality- and equality-constrained LQ games, and therefore specific methods for the solution of these special cases are developed in detail. We demonstrate the effectiveness of the proposed solution approach on a dynamic game arising in an autonomous driving application.
翻译:我们在动态游戏中提出通用反馈Nash Equilibrium(GFNE)的概念,将反馈Nash Equilibrium(GFNE)的概念扩大到玩家受到州和投入限制的游戏;我们将(当地)GFNE解决方案的必要和充分条件正式确定为轨道水平,以便能够为计算这些解决方案制定高效的数字方法;具体地说,我们提出了牛顿式的游戏轨迹寻找方法,满足必要的条件,然后可以对照充足条件加以检查;我们表明,对一般必要条件的评估需要计算一系列嵌套的、隐含定义的衍生物,这些衍生物很快变得难以解决;为此,我们提出近似适合高效评估的必要条件的(当地)GFNE解决方案的近似和充分条件,反过来,计算解决方案的计算方法;我们提出一个符合必要条件的牛顿式的游戏轨迹,然后对照充足条件加以检查;我们提出一个渐进式的线-二次游戏方法,在每次游戏中解决近似的LQ游戏。为此,我们引入了近似本地的LQ游戏的组合,因此要接近于高效评估必要的必要条件,并详细选择了这些特定的游戏。