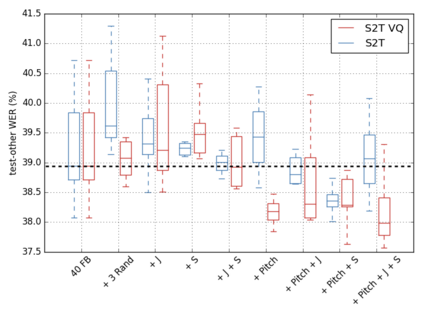
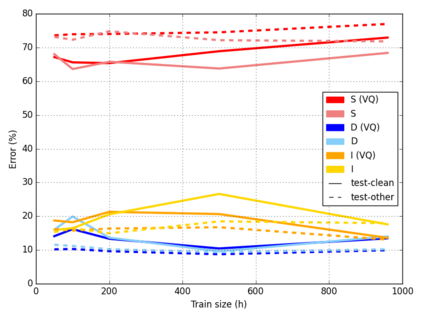
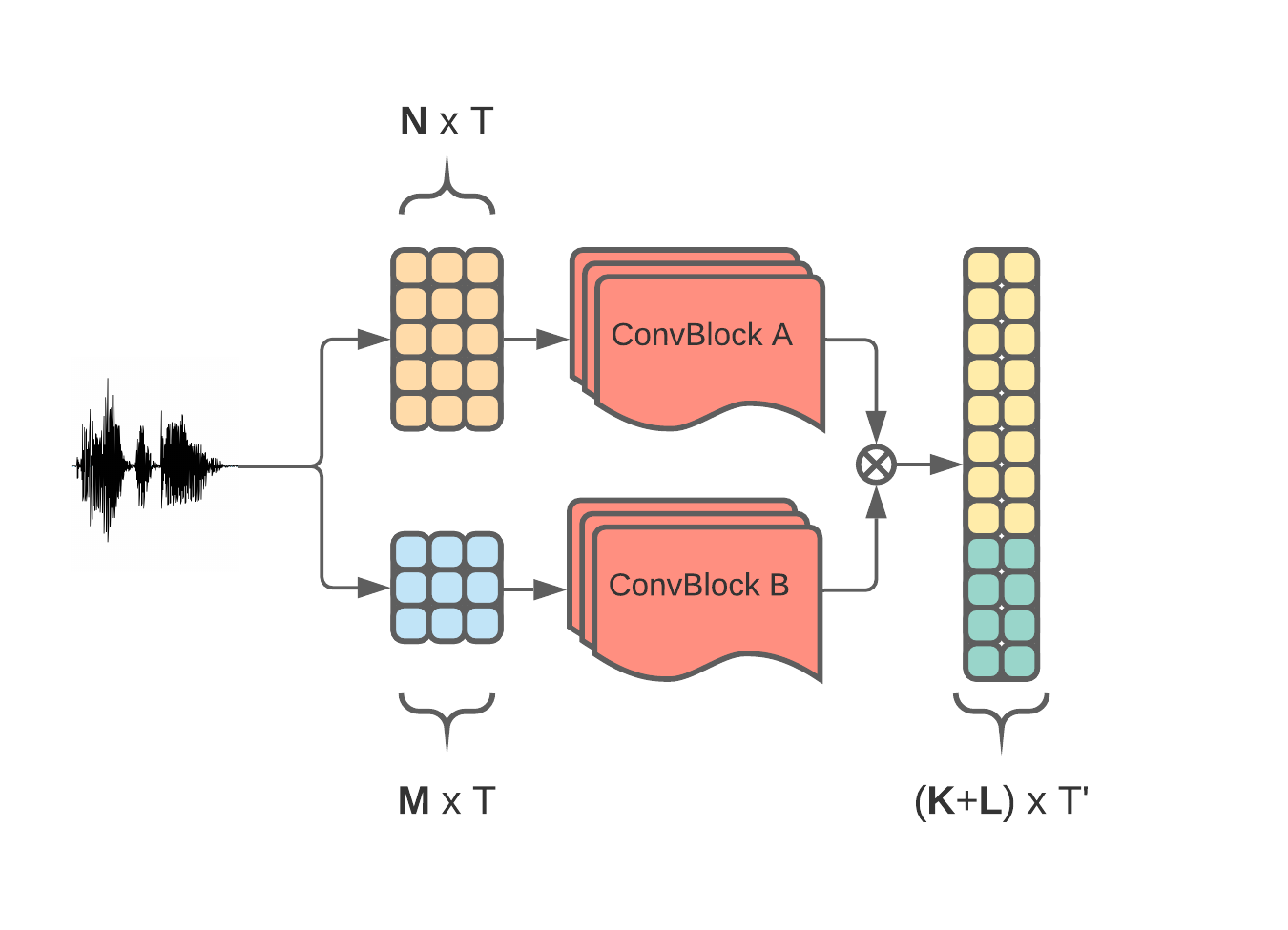
Jitter and shimmer measurements have shown to be carriers of voice quality and prosodic information which enhance the performance of tasks like speaker recognition, diarization or automatic speech recognition (ASR). However, such features have been seldom used in the context of neural-based ASR, where spectral features often prevail. In this work, we study the effects of incorporating voice quality and pitch features altogether and separately to a Transformer-based ASR model, with the intuition that the attention mechanisms might exploit latent prosodic traits. For doing so, we propose separated convolutional front-ends for prosodic and spectral features, showing that this architectural choice yields better results than simple concatenation of such pitch and voice quality features to mel-spectrogram filterbanks. Furthermore, we find mean Word Error Rate relative reductions of up to 5.6% with the LibriSpeech benchmark. Such findings motivate further research on the application of prosody knowledge for increasing the robustness of Transformer-based ASR.
翻译:热量和闪光度测量显示是声音质量和预断信息的载体,可以提高语音识别、分解或自动语音识别(ASR)等任务的性能;然而,这些特征很少在以神经为基础的ASR中使用,因为光谱特征往往在这种环境中占多数;在这项工作中,我们研究将声音质量和声道特征完全与以变异器为基础的ASR模型分别结合的影响,直觉认为关注机制可能会利用潜伏的分解特征;为此,我们提议对预感和光谱特征分别提出共振前端,表明这种建筑选择比简单将这种声频和声质量特征配置到Mel-spectrogrographer 过滤库中的结果要好;此外,我们发现,与LibSpeech基准相比,将高达5.6%的音频率相对降幅比值为5.6%。这些发现有助于进一步研究如何应用超常知识提高变异光源基于ASR的稳健性。