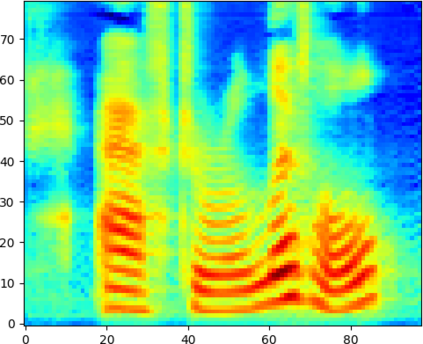
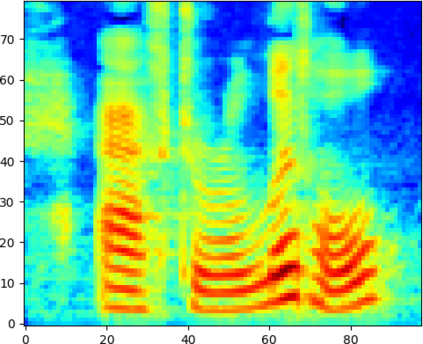
Deep learning has revolutionised synthetic speech quality. However, it has thus far delivered little value to the speech science community. The new methods do not meet the controllability demands that practitioners in this area require e.g.: in listening tests with manipulated speech stimuli. Instead, control of different speech properties in such stimuli is achieved by using legacy signal-processing methods. This limits the range, accuracy, and speech quality of the manipulations. Also, audible artefacts have a negative impact on the methodological validity of results in speech perception studies. This work introduces a system capable of manipulating speech properties through learning rather than design. The architecture learns to control arbitrary speech properties and leverages progress in neural vocoders to obtain realistic output. Experiments with copy synthesis and manipulation of a small set of core speech features (pitch, formants, and voice quality measures) illustrate the promise of the approach for producing speech stimuli that have accurate control and high perceptual quality.
翻译:深层学习使合成语言质量发生了革命性的变化。然而,迄今为止,它几乎没有给语言科学界带来什么价值。新方法没有满足该领域实践者所需要的可控制性要求,例如:用操纵的语音刺激进行听觉测试。相反,通过使用遗留的信号处理方法控制了这种刺激中的不同语音属性。这限制了操纵的广度、准确性和语言质量。此外,听力工艺对语音认知研究结果的方法有效性产生了负面影响。这项工作引入了一个能够通过学习而不是设计来操纵语言特性的系统。建筑学会控制任意的语音特性并利用神经电动器的进展获得现实的输出。在复制合成和操纵一小组核心语音特征(脉动、成型和声音质量措施)方面的实验显示了制作具有准确控制和高感官质量的语音模拟功能的前景。