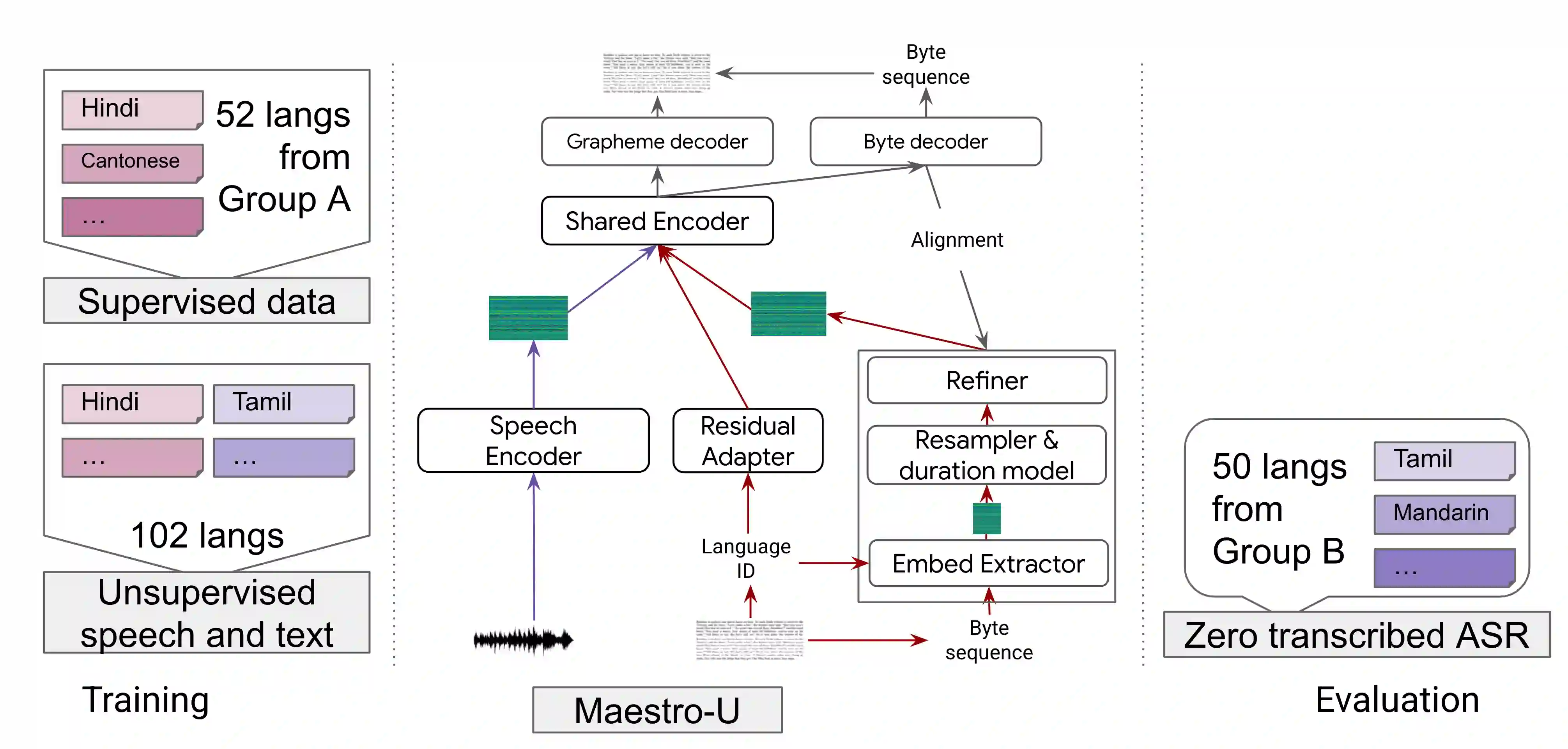
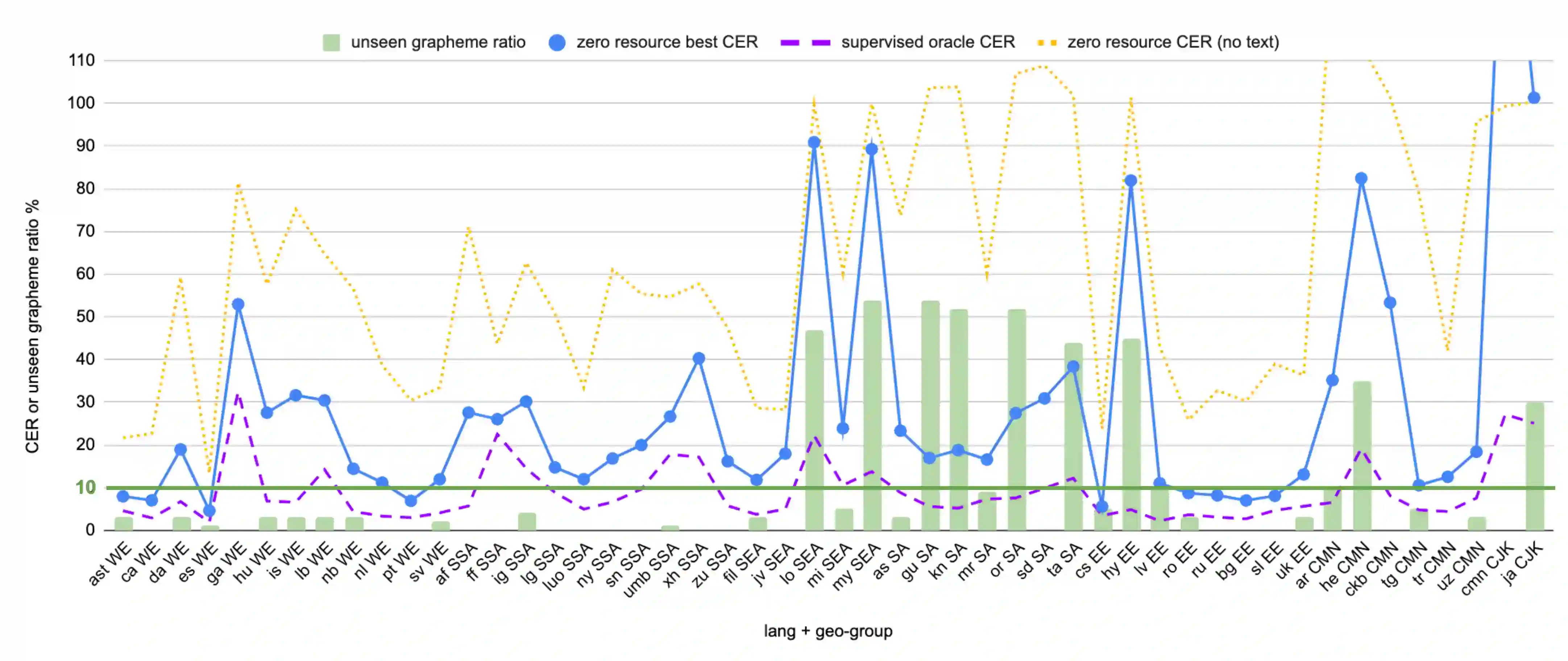
Training state-of-the-art Automated Speech Recognition (ASR) models typically requires a substantial amount of transcribed speech. In this work, we demonstrate that a modality-matched joint speech and text model can be leveraged to train a massively multilingual ASR model without any supervised (manually transcribed) speech for some languages. This paper explores the use of jointly learnt speech and text representations in a massively multilingual, zero supervised speech, real-world setting to expand the set of languages covered by ASR with only unlabeled speech and text in the target languages. Using the FLEURS dataset, we define the task to cover $102$ languages, where transcribed speech is available in $52$ of these languages and can be used to improve end-to-end ASR quality on the remaining $50$. First, we show that by combining speech representations with byte-level text representations and use of language embeddings, we can dramatically reduce the Character Error Rate (CER) on languages with no supervised speech from 64.8\% to 30.8\%, a relative reduction of 53\%. Second, using a subset of South Asian languages we show that Maestro-U can promote knowledge transfer from languages with supervised speech even when there is limited to no graphemic overlap. Overall, Maestro-U closes the gap to oracle performance by 68.5\% relative and reduces the CER of 19 languages below 15\%.
翻译:培训最先进的自动语音识别(ASR)模式通常要求大量转录语音。在这项工作中,我们证明可以利用一种模式式配对的联合语音和文本模式来培训大规模多语种的ASR模式,无需对一些语言进行任何监督(手动转录)的演讲。本文探讨了在大规模多语种、零监督的演讲、真实世界环境中使用联合学习的演讲和文字表述方式,以扩大ASR所涵盖的一套语言,仅使用目标语言的未加标记的演讲和文本。我们利用FLEURS数据集,界定了涵盖102美元语言的任务,在这些语言中,可提供520美元的转录制语音和文本模式,用于培训大规模多语言的大规模多语种(手语(手语翻译)语言。首先,我们表明,通过将语音表述与字级文字表达方式和语言嵌嵌入结合起来,我们可以大幅降低语言的字符错误率(CER)从64.8 ⁇ 降至30.8 ⁇ 。 我们界定了53 ⁇ 的相对差距,第二,使用15美元转录式语言的分组,我们通过监督的磁标式将18度转换为近平调。