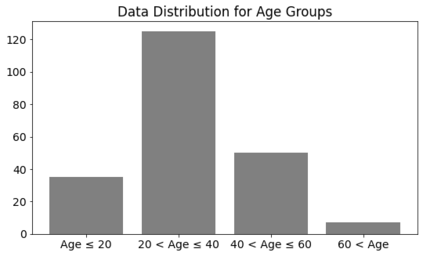
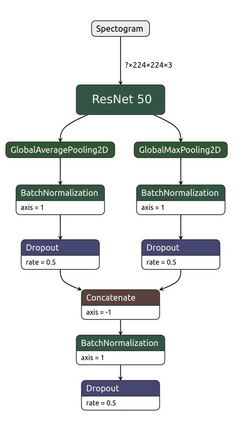
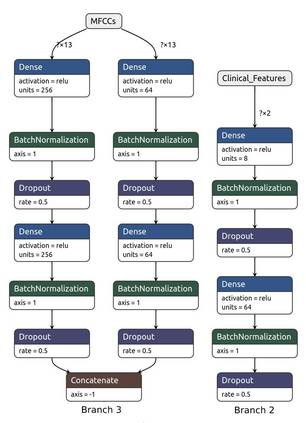
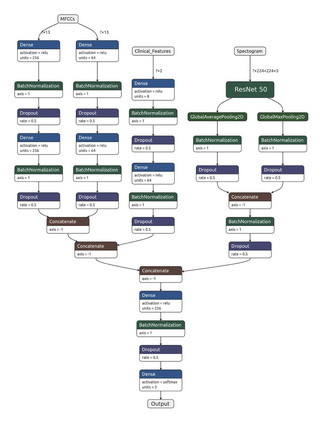
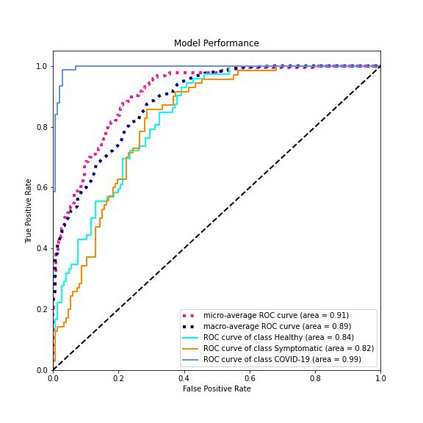
Fast and affordable solutions for COVID-19 testing are necessary to contain the spread of the global pandemic and help relieve the burden on medical facilities. Currently, limited testing locations and expensive equipment pose difficulties for individuals trying to be tested, especially in low-resource settings. Researchers have successfully presented models for detecting COVID-19 infection status using audio samples recorded in clinical settings [5, 15], suggesting that audio-based Artificial Intelligence models can be used to identify COVID-19. Such models have the potential to be deployed on smartphones for fast, widespread, and low-resource testing. However, while previous studies have trained models on cleaned audio samples collected mainly from clinical settings, audio samples collected from average smartphones may yield suboptimal quality data that is different from the clean data that models were trained on. This discrepancy may add a bias that affects COVID-19 status predictions. To tackle this issue, we propose a multi-branch deep learning network that is trained and tested on crowdsourced data where most of the data has not been manually processed and cleaned. Furthermore, the model achieves state-of-art results for the COUGHVID dataset [16]. After breaking down results for each category, we have shown an AUC of 0.99 for audio samples with COVID-19 positive labels.
翻译:COVID-19测试的快速和负担得起的解决方案对于遏制全球大流行病的蔓延是必要的,并有助于减轻医疗设施的负担。目前,有限的检测地点和昂贵的设备有限,给试图接受检测的个人、特别是低资源环境的人造成了困难。研究人员成功地展示了使用临床环境中记录的音频样本检测COVID-19感染状况的模式[5、15],建议可以使用基于音频的人工智能模型来识别COVID-19。这些模型有可能被安装在智能手机上,用于快速、广泛和低资源测试。然而,虽然以往的研究已经培训了主要从临床环境中收集的清洁音频样本模型,但从普通智能手机收集的音频样本可能会产生与所培训的清洁数据不同的非最佳质量数据。这一差异可能会增加一种影响COVID-19状况预测的偏差。为了解决这一问题,我们建议建立一个多处深层次的学习网络,在人群源数据中大部分数据未经人工处理和清理。此外,模型为COUGVI-19标签显示的每类正值,我们打破了CUGUVI的每类。